Емпірична функція розподілу у статистиці. Емпірична функція розподілу, властивості
Як відомо, закон розподілу випадкової величини можна задавати у різний спосіб. Дискретну випадкову величину можна задати за допомогою ряду розподілу або інтегральної функції, а безперервну випадкову величину – за допомогою інтегральної або диференціальної функції. Розглянемо вибіркові аналоги цих двох функций.
Нехай є вибіркова сукупність значень деякої випадкової величини обсягу  і кожному варіанту з цієї сукупності поставлена у відповідність його частість. Нехай далі,
і кожному варіанту з цієї сукупності поставлена у відповідність його частість. Нехай далі,  - Деяке дійсне число, а
- Деяке дійсне число, а  - Число вибіркових значень випадкової величини
- Число вибіркових значень випадкової величини  , менших
, менших  . Тоді число
. Тоді число  є частиною значень величини, що спостерігаються у вибірці X, менших
є частиною значень величини, що спостерігаються у вибірці X, менших  ,
тобто. частістю появи події
,
тобто. частістю появи події 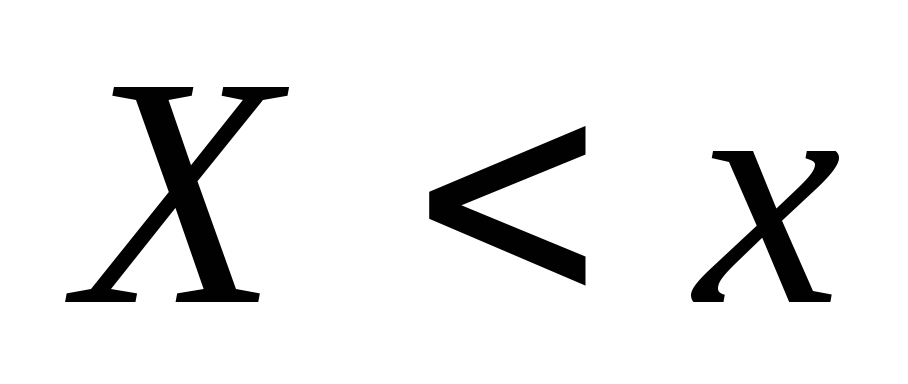 . При зміні xу загальному випадку змінюватиметься і величина
. При зміні xу загальному випадку змінюватиметься і величина  . Це означає, що відносна частота
. Це означає, що відносна частота  є функцією аргументу
є функцією аргументу  . Оскільки ця функція знаходиться за вибірковими даними, отриманими в результаті дослідів, то її називають вибірковою або емпіричної.
. Оскільки ця функція знаходиться за вибірковими даними, отриманими в результаті дослідів, то її називають вибірковою або емпіричної.
Визначення 10.15. Емпіричною функцією розподілу(функцією розподілу вибірки) називають функцію  , що визначає для кожного значення xвідносну частоту події
, що визначає для кожного значення xвідносну частоту події  .
.
 (10.19)
(10.19)
На відміну від емпіричної функції розподілу вибірки, функцію розподілу F(x) генеральної сукупності називають теоретичною функцією розподілу. Відмінність між ними полягає в тому, що теоретична функція F(x)
визначає ймовірність події  , А емпірична - відносну частоту цієї ж події. З теореми Бернуллі випливає
, А емпірична - відносну частоту цієї ж події. З теореми Бернуллі випливає
 ,
,
 (10.20)
(10.20)
тобто. при великих  ймовірність
ймовірність  та відносна частота події
та відносна частота події  , тобто.
, тобто.  мало відрізняються одне від одного. Вже звідси випливає доцільність використання емпіричної функції розподілу вибірки для наближеного представлення теоретичної (інтегральної) функції розподілу генеральної сукупності.
мало відрізняються одне від одного. Вже звідси випливає доцільність використання емпіричної функції розподілу вибірки для наближеного представлення теоретичної (інтегральної) функції розподілу генеральної сукупності.
Функція  і
і  мають однакові властивості. Це випливає із визначення функції.
мають однакові властивості. Це випливає із визначення функції. 
Властивості  :
:

Приклад 10.4.Побудувати емпіричну функцію щодо даного розподілу вибірки:
|
Варіанти | |||
|
Частоти |


Рішення:Знайдемо обсяг вибірки n=
12 +18 +30 = 60. Найменша варіанта  , отже,
, отже,  при
при  . Значення
. Значення  , а саме
, а саме  спостерігалося 12 разів, отже:
спостерігалося 12 разів, отже:
 =
= при
при  .
.
Значення x<
10, а саме  і
і  спостерігалися 12+18=30 разів, отже,
спостерігалися 12+18=30 разів, отже,  =
= при
при  . При
. При 
 .
.
Шукана емпірична функція розподілу:
 =
=
Графік  представлений на рис. 10.2
представлений на рис. 10.2
Р  іс. 10.2
іс. 10.2
Контрольні питання
1. Які основні завдання розв'язує математична статистика? 2. Генеральна та вибіркова сукупність? 3. Дайте визначення об'єму вибірки. 4. Які вибірки називаються репрезентативними? 5. Помилки репрезентативності. 6. Основні способи утворення вибірки. 7. Поняття частоти, відносної частоти. 8. Поняття статистичного ряду. 9. Запишіть формулу Стерджеса. 10. Сформулюйте поняття розмаху вибірки, медіани та моди. 11. Полігон частот, гістограма. 12. Поняття точкової оцінки вибіркової сукупності. 13. Зміщена та незміщена точкова оцінка. 14. Сформулюйте поняття вибіркової середньої. 15. Сформулюйте поняття вибіркової дисперсії. 16. Сформулюйте поняття вибіркового середньоквадратичного відхилення. 17. Сформулюйте поняття вибіркового коефіцієнта варіації. 18. Сформулюйте поняття вибіркової середньої геометричної.
Лекція 13. Поняття про статистичні оцінки випадкових величин
Нехай відомий статистичний розподіл частот кількісної ознаки X. Позначимо через число спостережень, у яких спостерігалося значення ознаки, менше x і n – загальна кількість спостережень. Очевидно, відносна частота події X< x равна и является функцией x. Так как эта функция находится эмпирическим (опытным) путем, то ее называют эмпирической.
Емпіричною функцією розподілу(функцією розподілу вибірки) називають функцію , що визначає для кожного значення x відносну частоту події X< x. Таким образом, по определению ,где - число вариант, меньших x, n – объем выборки.
На відміну від емпіричної функції розподілу вибірки, функцію розподілу генеральної сукупності називають теоретичною функцією розподілу.Відмінність між цими функціями полягає в тому, що теоретична функція визначає ймовірністьподії X< x, тогда как эмпирическая – відносну частотуцієї ж події.
У разі зростання n відносна частота події X< x, т.е. стремится по вероятности к вероятности этого события. Иными словами
Властивості емпіричної функції розподілу:
1) Значення емпіричної функції належать відрізку
2) - незнижена функція
3) Якщо - найменша варіанта, то = 0 при , якщо - найбільша варіанта, то = 1 при .
Емпірична функція розподілу вибірки служить з метою оцінки теоретичної функції розподілу генеральної сукупності.
приклад. Побудуємо емпіричну функцію щодо розподілу вибірки:
| Варіанти | |||
| Частоти |
Знайдемо обсяг вибірки: 12+18+30=60. Найменша варіанта дорівнює 2, тому =0 при x £ 2. Значення x<6, т.е. , наблюдалось 12 раз, следовательно, =12/60=0,2 при 2< x £6. Аналогично, значения X < 10, т.е. и наблюдались 12+18=30 раз, поэтому =30/60 =0,5 при 6< x £10. Так как x=10 – наибольшая варианта, то =1 при x>10. таким чином, шукана емпірична функція має вигляд:
Найважливіші властивості статистичних оцінок
Нехай потрібно вивчити деяку кількісну ознаку генеральної сукупності. Припустимо, що з теоретичних міркувань вдалося встановити, яке самерозподіл має ознаку та необхідно оцінити параметри, якими воно визначається. Наприклад, якщо досліджуваний ознака розподілено в генеральній сукупності нормально, потрібно оцінити математичне очікування і середнє квадратичне відхилення; якщо ознака має розподіл Пуассона – необхідно оцінити параметр l.
Зазвичай є дані вибірки, наприклад значення кількісного ознаки , отримані в результаті n незалежних спостережень. Розглядаючи як незалежні випадкові величини можна сказати, що знайти статистичну оцінку невідомого параметра теоретичного розподілу - означає знайти функцію від випадкових величин, що спостерігаються, яка дає наближене значення оцінюваного параметра. Наприклад, для оцінки математичного очікування нормального розподілу роль функції виконує середнє арифметичне
Для того щоб статистичні оцінки давали коректні наближення параметрів, що оцінюються, вони повинні задовольняти деяким вимогам, серед яких найважливішими є вимоги незміщеності і спроможності оцінки.
Нехай – статистична оцінка невідомого параметра теоретичного розподілу. Нехай за вибіркою обсягу n знайдено оцінку. Повторимо досвід, тобто. вилучимо з генеральної сукупності іншу вибірку того ж обсягу та за її даними отримаємо іншу оцінку. Повторюючи досвід багаторазово, отримаємо різні числа. Оцінку можна як випадкову величину, а числа - як її можливі значення.
Якщо оцінка дає наближене значення з надлишком, тобто. кожне число більше істинного значення, як наслідок, математичне очікування (середнє значення) випадкової величини більше, ніж :. Аналогічно, якщо дає оцінку з нестачею, то.
Таким чином, використання статистичної оцінки, математичне очікування якої не дорівнює параметру, що оцінюється, призвело б до систематичних (одного знака) помилок. Якщо, навпаки, то це гарантує від систематичних помилок.
Незміщеною називають статистичну оцінку, математичне очікування якої дорівнює параметру, що оцінюється при будь-якому обсязі вибірки.
Зміщеноюназивають оцінку, що не задовольняє цю умову.
Несмещенность оцінки ще гарантує отримання хорошого наближення для оцінюваного параметра, оскільки можливі значення може бути сильно розпорошені довкола свого середнього значення, тобто. дисперсія може бути значною. У цьому випадку знайдена за даними однієї вибірки оцінка, наприклад, може виявитися значно віддаленою від середнього значення, а значить, і від параметра, що оцінюється.
Ефективною називають статистичну оцінку, яка, за заданого обсягу вибірки n, має найменшу можливу дисперсію .
При розгляді вибірок великого обсягу до статистичних оцінок висувається вимога спроможності .
Заможною називається статистична оцінка, яка при n®¥ прагне ймовірності оцінюваного параметра. Наприклад, якщо дисперсія незміщеної оцінки при n® прагне до нуля, то така оцінка виявляється і заможною.
Вибіркова середня.
Нехай для вивчення генеральної сукупності щодо кількісної ознаки Х вилучено вибірку обсягу n.
Вибірковою середньою називають середнє арифметичне значення ознаки вибіркової сукупності.
![]()
Вибіркова дисперсія.
Для того, щоб спостерігати розсіювання кількісної ознаки значень вибірки навколо свого середнього значення, вводять зведену характеристику - вибіркову дисперсію.
Вибірковою дисперсією називають середнє арифметичне квадратів відхилення значень ознаки, що спостерігаються, від їх середнього значення.
Якщо всі значення ознаки вибірки різні, то

Виправлена дисперсія.
Вибіркова дисперсія є зміщеною оцінкою генеральної дисперсії, тобто. математичне очікування вибіркової дисперсії не дорівнює оцінюваної генеральної дисперсії, а так само
![]()
Для виправлення вибіркової дисперсії достатньо помножити її на дріб
Вибірковий коефіцієнт кореляціїзнаходиться за формулою

де - Вибіркові середні квадратичні відхилення величин і .
Вибірковий коефіцієнт кореляції показує тісноту лінійного зв'язку між і : чим ближче до одиниці, тим сильніший лінійний зв'язок між і .
23. Полігоном частот називають ламану лінію, відрізки якої з'єднують точки. Для побудови полігону частот на осі абсцис відкладають варіанти , але в осі ординат – відповідні їм частоти і з'єднують точки відрізками прямих.
Полігон відносних частот будується аналогічно, крім того, що у осі ординат відкладаються відносні частоти .
Гістограмою частот називають ступінчасту фігуру, що складається з прямокутників, основами якої є часткові інтервали довжиною h, а висоти рівні відношенню . Для побудови гістограми частот осі абсцис відкладають часткові інтервали, а над ними проводять відрізки, паралельні осі абсцис на відстані (висоті) . Площа i–го прямокутника дорівнює – сумі частот варіант i–про інтервалу, тому площа гістограми частот дорівнює сумі всіх частот, тобто. обсягу вибірки.


Емпірична функція розподілу
де n x- кількість вибіркових значень, менших x; n- Обсяг вибірки.
22Визначимо основні поняття математичної статистики
.Основні поняття математичної статистики. Генеральна сукупність та вибірка. варіаційний ряд, статистичний ряд. Групована вибірка. Групований статистичний ряд. Полігон частот. Вибіркова функція розподілу та гістограма.
Генеральна сукупність- Все безліч наявних об'єктів.
Вибірка- Набір об'єктів, випадково відібраних з генеральної сукупності.
Послідовність варіант, записаних у порядку зростання, називають варіаційнимпоряд, а перелік варіантів і відповідних їм частот або відносних частот – статистичним рядом: чайно відібраних із генеральної сукупності.
Полігономчастот називають ламану лінію, відрізки якої з'єднують точки.
Гістограмою частотназивають ступінчасту фігуру, що складається з прямокутників, основами якої є часткові інтервали довжиною h, а висоти рівні відношенню .
Вибірковою (емпіричною) функцією розподілуназивають функцію F*(x), визначальну для кожного значення хвідносну частоту події X< x.
Якщо досліджується деяка безперервна ознака, то варіаційний ряд може складатися з великої кількості чисел. У цьому випадку зручніше використовувати груповану вибірку. Для її отримання інтервал, в якому укладені всі значення ознаки, що спостерігаються, розбивають на кілька рівних часткових інтервалів завдовжки h, а потім знаходять для кожного часткового інтервалу n i- Суму частот варіант, що потрапили в i-і інтервал.
20. Під законом великих чисел не слід розуміти один загальний закон, пов'язаний з великими числами. Закон великих чисел - це узагальнена назва кількох теорем, у тому числі випливає, що з необмеженому збільшенні числа випробувань середні величини прагнуть деяким постійним.
До них відносяться теореми Чебишева та Бернуллі. Теорема Чебишева є найбільш загальним законом великих чисел.
В основі доказу теорем, об'єднаних терміном "закон великих чисел", лежить нерівність Чебишева, за якою встановлюється можливість відхилення від її математичного очікування:
![]()
19Розподіл Пірсона (хі - квадрат) – розподіл випадкової величини
де випадкові величини X 1 , X 2 ,…, X nнезалежні і мають один і той же розподіл N(0,1). У цьому кількість доданків, тобто. n, називається «числом ступенів свободи» розподілу хі – квадрат.
Розподіл хі-квадрат використовують при оцінюванні дисперсії (за допомогою довірчого інтервалу), при перевірці гіпотез згоди, однорідності, незалежності,
Розподіл tСтьюдента - це розподіл випадкової величини
де випадкові величини Uі Xнезалежні, Uмає розподіл стандартний нормальний розподіл N(0,1), а X– розподіл хі – квадрат з nступенями свободи. При цьому nназивається "числом ступенів свободи" розподілу Стьюдента.
Його застосовують при оцінюванні математичного очікування, прогнозного значення та інших характеристик за допомогою довірчих інтервалів, перевірки гіпотез про значення математичних очікувань, коефіцієнтів регресійної залежності,
Розподіл Фішера – це розподіл випадкової величини
Розподіл Фішера використовують під час перевірки гіпотез про адекватність моделі в регресійному аналізі, про рівність дисперсій та інших завданнях прикладної статистики
18Лінійна регресіяє статистичним інструментом, який використовується для прогнозування майбутніх цін виходячи з минулих даних, і зазвичай застосовується, щоб визначити, коли ціни є перегрітими. Використовується метод найменшого квадрата для побудови «найбільш підходящої» прямої лінії через низку точок цінових значень. Ціновими точками, що використовуються як вхідні дані, може бути будь-яке з наступних значень: відкриття, закриття, максимум, мінімум,
17. Двовимірною випадковою величиною називають упорядкований набір з двох випадкових величин або .
Приклад. Підкидаються два гральні кубики. – кількість очок, що випали на першому та другому кубиках відповідно
Універсальний спосіб завдання закону розподілу двовимірної випадкової величини – це функція розподілу.
15.м.о Дискретні випадкові величини
Властивості:
1) M(C) = C, C- Постійна;
2) M(CX) = CM(X);
3) M(X 1 + X 2) = M(X 1) + M(X 2), де X 1, X 2- незалежні випадкові величини;
4) M(X 1 X 2) = M(X 1)M(X 2).
Математичне очікування суми випадкових величин дорівнює сумі їх математичних очікувань, тобто.
Математичне очікування різниці випадкових величин дорівнює різниці їх математичних очікувань, тобто.
Математичне очікування добутку випадкових величин дорівнює добутку їх математичних очікувань, тобто.
Якщо всі значення випадкової величини збільшити (зменшити) на те саме число С, то її математичне очікування збільшиться (зменшитися) на це ж число
14. Показовий(експоненційний)закон розподілу Xмає показовий (експоненційний) закон розподілу з параметром >0, якщо її щільність ймовірності має вигляд:
![]()
Математичне очікування: .
Дисперсія: .
Показовий закон розподілу грає велику роль теорії масового обслуговування і теорії надійності.
13. Нормальний закон розподілу характеризується частотою відмов a(t) або щільністю ймовірності відмов f(t) виду:
 , (5.36)
, (5.36)
де σ– середньоквадратичне відхилення СВ x;
m x– математичне очікування СВ x. Цей параметр часто називають центром розсіювання або найімовірнішим значенням СВ Х.
x- Випадкова величина, за яку можна прийняти час, значення струму, значення електричної напруги та інших аргументів.
Нормальний закон – це двопараметричний закон, для запису якого потрібно знати m xта σ.
Нормальний розподіл (розподіл Гауса) використовується при оцінці надійності виробів, на які впливає ряд випадкових факторів, кожен з яких незначно впливає на результуючий ефект.
12. Рівномірний закон розподілу. Безперервна випадкова величина Xмає рівномірний закон розподілу на відрізку [ a, b], якщо її щільність ймовірності постійна цьому відрізку і дорівнює нулю поза ним, тобто.

Позначення: .
Математичне очікування: .
Дисперсія: .
Випадкова величина Х, розподілена за рівномірним законом на відрізку називається випадковим числомвід 0 до 1. Вона є вихідним матеріалом для отримання випадкових величин з будь-яким законом розподілу. Рівномірний закон розподілу використовується під час аналізу помилок округлення під час проведення числових розрахунків, у низці завдання масового обслуговування, при статистичному моделюванні спостережень, підпорядкованих заданому розподілу.
11. Визначення.Щільністю розподілуймовірностей безперервної випадкової величини Х називається функція f(x)– перша похідна функції розподілу F(x).
Щільність розподілу також називають диференціальною функцією. Для опису дискретної випадкової величини щільність розподілу неприйнятна.
Сенс щільності розподілу полягає в тому, що вона показує як часто з'являється випадкова величина Х в околиці точки хпри повторенні дослідів.
Після введення функцій розподілу та густини розподілу можна дати наступне визначення безперервної випадкової величини.
10. Щільність ймовірності, густина розподілу ймовірностей випадкової величини x, - функція p(x) така, що 
і за будь-яких a< b вероятность события a < x < b равна
.
Якщо p(x) безперервна, то за досить малих ∆x ймовірність нерівності x< X < x+∆x приближенно равна p(x) ∆x (с точностью до малых более высокого порядка). Функция распределения F(x) случайной величины x, связана с плотностью распределения соотношениями
і, якщо F(x) диференційована, то ![]()
Методи обробки ЕД спираються на базові поняття теорії ймовірностей та математичної статистики. До них належать поняття генеральної сукупності, вибірки, емпіричної функції розподілу.
Під генеральною сукупністюрозуміють всі можливі значення параметра, які можуть бути зареєстровані в ході необмеженого спостереження за об'єктом.Така сукупність складається з безлічі елементів. Внаслідок спостереження за об'єктом формується обмежена за обсягом сукупність значень параметра x 1 , x 2 , …, xn. З формальної точки зору такі дані є вибірку із генеральної сукупності.
Вважатимемо, що вибірка містить повні напрацювання до системних подій (цензурування відсутнє). Значення, що спостерігаються x i називають варіантами , а їх кількість – обсягом вибірки n. Для того, щоб за результатами спостереження можна було робити будь-які висновки, вибірка повинна бути репрезентативної(представницької), тобто правильно представляти пропорції генеральної сукупності. Ця вимога виконується, якщо обсяг вибірки досить великий, а кожен елемент генеральної сукупності має однакову можливість потрапити у вибірку.
Нехай у отриманій вибірці значення x 1 параметра спостерігалося n 1 раз, значення x 2 – n 2 разів, значення xk – nk раз, n 1 +n 2 + … +nk=n.
Сукупність значень, записаних у порядку їх зростання, називають варіаційним рядом, величини n i – частотами, а їхнє ставлення до обсягу вибірки ni =n i /n – відносними частотами(частинами). Очевидно, що сума відносних частот дорівнює одиниці.
Під розподілом розуміють відповідність між варіантами, що спостерігаються, і їх частотами або частотами. Нехай nx
– кількість спостережень, у яких випадкові значення параметра Хменше x.Частина події X
розподілу: Fn(x) Незменшуюча функція, її значення належать відрізку;
якщо x 1 – найменше значення параметра, а xk - Найбільше, то Fn(x)= 0, коли x<x 1 , і Fп(xk)= 1, коли x>=xk.
Функція Fn(x) визначається за ЕД, тому її називають емпіричною функцією розподілу. На відміну від емпіричної функції Fn(x) функцію розподілу F (x) генеральної сукупності називають теоретичною функцією розподілу,вона характеризує нечастість, а ймовірність події X<x. З теореми Бернуллі випливає, що часто Fn(x) прагне по ймовірності до ймовірності F(x) при необмеженому збільшенні n. Отже, при великому обсязі спостережень теоретичну функцію розподілу F(x) можна замінити емпіричною функцією Fn(x).
Графік емпіричної функції Fn(x) являє собою ламану лінію. У проміжках між сусідніми членами варіаційного ряду Fn(x) Зберігає постійне значення. При переході через осі x, рівні членам вибірки, Fn(x) зазнає розриву, стрибком зростаючи на величину 1/ n, а при збігу lспостережень – на l/n.
Приклад 2.1. Побудувати варіаційний ряд та графік емпіричної функції розподілу за результатами спостережень, табл. 2.1.
Таблиця 2.1
Шукана емпірична функція, рис. 2.1:

Рис. 2.1. Емпірична функція розподілу
При великому обсязі вибірки (поняття «великий об'єм» залежить від цілей та методів обробки, в даному випадку вважатимемо пвеликим, якщо n>40) з метою зручності обробки та зберігання відомостей вдаються до групування ЕД в інтервали.Кількість інтервалів слід вибрати так, щоб у необхідній мірі відбилося розмаїття значень параметра в сукупності і водночас закономірність розподілу не спотворювалася випадковими коливаннями частот за окремими розрядами. Існують несуворі рекомендації щодо вибору кількості yі розміру h таких інтервалів, зокрема:
у кожному інтервалі має бути щонайменше 5 – 7 елементів. У крайніх розрядах допустимо лише два елементи;
кількість інтервалів не повинна бути дуже великою чи дуже маленькою. Мінімальне значення y має бути не менше 6 - 7.При обсязі вибірки, що не перевищує кілька сотень елементів, величину y задають у межах від 10 до 20.Для дуже великого обсягу вибірки ( n>1000) кількість інтервалів може перевищувати зазначені значення. Деякі дослідники рекомендують користуватися співвідношенням y=1,441*ln( n)+1;
при відносно невеликій нерівномірності довжини інтервалів зручно вибирати однаковими і рівними величині
h= (x max – x min)/y,
де x max – максимальне та x min – мінімальне значення параметра. При суттєвій нерівномірності закону розподілу довжини інтервалів можна задавати меншого розміру в області швидкої зміни густини розподілу;
при значній нерівномірності краще кожен розряд призначати приблизно однакову кількість елементів вибірки. Тоді довжина конкретного інтервалу визначатиме крайніми значеннями елементів вибірки, згрупованими цей інтервал, тобто. буде різна для різних інтервалів (у разі при побудові гістограми нормування по довжині інтервалу обов'язкова - інакше висота кожного елемента гістограми буде однакова).
Групування результатів спостережень за інтервалами передбачає: визначення розмаху змін параметра х; вибір кількості інтервалів та їх величини; підрахунок для кожного i-го інтервалу [ xi–xi+1] частоти ni або відносної частоти (частини n i) Попадання варіанти в інтервал. В результаті формується подання ЕД у вигляді інтервального чи статистичного ряду.
Графічно статистичний ряд відображають у вигляді гістограми, полігону та східчастої лінії. Часто гістограмупредставляють як фігуру, що складається з прямокутників, основами яких є інтервали довжиною h, А висоти дорівнюють відповідної частоти.Однак такий підхід неточний. Висоту i-го прямокутника z iслід вибрати рівною ni/ (nh). Таку гістограму можна інтерпретувати як графічне уявлення емпіричної функції густини розподілу. fn(x), у ній сумарна площа всіх прямокутників становитиме одиницю. Гістограма допомагає підібрати вид теоретичної функції розподілу для апроксимації ЕД.
Полігономназивають ламану лінію, відрізки якої з'єднують точки з координатами по осі абсцис, рівними середин інтервалів, а по осі ординат - відповідним частотам. Емпірична функція розподілу відображається ступінчастою ламаною лінією: над кожним інтервалом проводиться відрізок горизонтальної лінії на висоті, накопиченої пропорційної частоти в поточному інтервалі. Накопичена частина дорівнює сумі всіх частостей, починаючи з першого і до цього інтервалу включно.
Приклад 2.2. Є результати реєстрації значень загасання сигналу xi на частоті 1000 Гц комутованого каналу телефонної мережі. Ці значення, виміряні в дБ, як варіаційного ряду представлені в табл. 2.3. Потрібно побудувати статистичний ряд.
Таблиця 2.3
| i | |||||||||||
| xi | 25,79 | 25,98 | 25,98 | 26,12 | 26,13 | 26,49 | 26,52 | 26,60 | 26,66 | 26,69 | 26,74 |
| i | |||||||||||
| xi | 26,85 | 26,90 | 26,91 | 26,96 | 27,02 | 27,11 | 27,19 | 27,21 | 27,28 | 27,30 | 27,38 |
| i | |||||||||||
| xi | 27,40 | 27,49 | 27,64 | 27,66 | 27,71 | 27,78 | 27,89 | 27,89 | 28,01 | 28,10 | 28,11 |
| i | |||||||||||
| xi | 28,37 | 28,38 | 28,50 | 28,63 | 28,67 | 28,90 | 28,99 | 28,99 | 29,03 | 29,12 | 29,28 |
Рішення. Кількість розрядів статистичного ряду слід вибрати мінімальною, щоб забезпечити достатню кількість попадань у кожен із них, візьмемо y = 6. Визначимо розмір розряду
h =(x max – x min) / y = (29,28 - 25,79) / 6 = 0,58.
Згрупуємо спостереження за розрядами, табл. 2.4.
Таблиця 2.4
| i | ||||||
| xi | 25,79 | 26,37 | 26,95 | 27,5 3 | 28,12 | 28,70 |
| ni | ||||||
| n i =ni/n | 0,114 | 0,205 | 0,227 | 0,205 | 0,11 4 | 0,136 |
| z i =n i /h | 0,196 | 0,353 | 0,392 | 0,353 | 0,196 | 0,235 |
На основі статистичного ряду збудуємо гістограму, рис. 2.2, та графік емпіричної функції розподілу, рис. 2.3.
Графік емпіричної функції розподілу, рис. 2.3 відрізняється від графіка, представленого на рис. 2.1 рівністю кроку зміни варіанти та величиною кроку збільшення функції (при побудові по варіаційному ряду крок збільшення кратен
1/ n, а за статистичним рядом – залежить від частоти у конкретному розряді).

Розглянуті уявлення ЕД є вихідними для подальшої обробки та обчислення різних параметрів.


