Генеральною сукупністю називається сукупність об'єктів. Генеральна сукупність та вибірка
Статистична сукупність- безліч одиниць, які мають масовістю, типовістю, якісною однорідністю та наявністю варіації.
Статистична сукупність складається з матеріально існуючих об'єктів (працівники, підприємства, країни, регіони), є об'єктом .
Одиниця сукупності- Кожна конкретна одиниця статистичної сукупності.
Одна і таже статистична сукупність може бути однорідною за однією ознакою і неоднорідною за іншою.
Якісна однорідність- подібність всіх одиниць сукупності за якоюсь ознакою і несхожість по всіх інших.
У статистичній сукупності відмінності однієї одиниці сукупності з іншого частіше мають кількісну природу. Кількісні зміни значень ознаки різних одиниць сукупності називаються варіацією.
Варіація ознаки- Кількісне зміна ознаки (для кількісної ознаки) при переході від однієї одиниці сукупності до іншої.
Ознака- це властивість, характерна риса або інша особливість одиниць, об'єктів та явищ, яка може бути спостережена чи виміряна. Ознаки поділяються на кількісні та якісні. Різноманітність та мінливість величини ознаки в окремих одиниць сукупності називається варіацією.
Атрибутивні (якісні) ознаки не піддаються числовому виразу (склад населення за статтю). Кількісні ознаки мають числове вираження (склад населення віком).
Показник- це узагальнююча кількісно якісна характеристика будь-якої властивості одиниць або сукупності в цільм у конкретних умовах часу та місця.
Система показників- Це сукупність показників всебічно відображають явище, що вивчається.
Наприклад, вивчається зарплата:- Ознака - оплата праці
- Статистична сукупність – усі працівники
- Одиниця сукупності – кожен працівник
- Якісна однорідність - нарахована зарплата
- Варіація ознаки – ряд цифр
Генеральна сукупність та вибірка з неї
Основу становить безліч даних, отриманих у результаті виміру однієї чи кількох ознак. Реально спостерігається сукупність об'єктів, статистично представлена рядом спостережень випадкової величини вибіркою, А гіпотетично існуюча (що домислюється) - генеральною сукупністю. Генеральна сукупність може бути кінцевою (кількість спостережень N = const) або нескінченною ( N = ∞), а вибірка з генеральної сукупності - це завжди результат обмеженого ряду спостережень. Число спостережень, що утворюють вибірку, називається обсягом вибірки. Якщо обсяг вибірки досить великий ( n → ∞) вибірка вважається великий, інакше вона називається вибіркою обмеженого обсягу. Вибірка вважається малоїякщо при вимірюванні одновимірної випадкової величини обсяг вибірки не перевищує 30 ( n<= 30 ), а при вимірі одночасно декількох ( k) ознак у багатовимірному просторі відношення nдо kне перевищує 10 (n/k< 10) . Вибірка утворює варіаційний ряд, якщо її члени є порядковими статистиками, Т. е. вибіркові значення випадкової величини Хупорядковані за зростанням (ранжовані), значення ж ознаки називаються варіантами.
приклад. Практично одна й та сама випадково відібрана сукупність об'єктів - комерційних банків одного адміністративного округу Москви, може розглядатися як вибірка з генеральної сукупності всіх комерційних банків цього округу, і як вибірка з генеральної сукупності всіх комерційних банків Москви, а також як вибірка з комерційних банків країни та і т.д.
Основні способи організації вибірки
Достовірність статистичних висновків та змістовна інтерпретація результатів залежить від репрезентативностівибірки, тобто. повноти та адекватності уявлення властивостей генеральної сукупності, стосовно якої цю вибірку вважатимуться представницької. Вивчення статистичних властивостей сукупності можна організувати двома способами: за допомогою суцільногоі несплошного. Суцільне спостереженняпередбачає обстеження всіх одиницьвивчається сукупності, а несуцільне (вибіркове) спостереження- Тільки його частини.
Існують п'ять основних способів організації вибіркового спостереження:
1. простий випадковий відбір, при якому об'єкти випадково вилучаються з генеральної сукупності об'єктів (наприклад, за допомогою таблиці або датчика випадкових чисел), причому кожна з можливих вибірок мають рівну ймовірність. Такі вибірки називаються власне-випадковими;
2. простий відбір за допомогою регулярної процедуриздійснюється за допомогою механічної складової (наприклад, дати, дня тижня, номера квартири, літери алфавіту та ін.) та отримані таким способом вибірки називаються механічними;
3. стратифікованийВідбір полягає в тому, що генеральна сукупність обсягу підрозділяється на підсукупність або шари (страти) обсягу так що . Страти є однорідними об'єктами з погляду статистичних характеристик (наприклад, населення ділиться на страти по віковим групам чи соціальної власності; підприємства — по галузях). У цьому випадку вибірки називаються стратифікованим(інакше, розшарованими, типовими, районованими);
4. методи серійноговідбору використовуються для формування серійнихабо гніздових вибірок. Вони зручні у разі, якщо необхідно обстежити відразу " блок " чи серію об'єктів (наприклад, партію товару, продукцію певної серії чи населення при територіально-адміністративному розподілі країни). Відбір серій можна здійснити власно-випадковим чи механічним способом. При цьому проводиться суцільне обстеження певної партії товару або цілої територіальної одиниці (житлового будинку чи кварталу);
5. комбінований(ступінчастий) відбір може поєднувати в собі відразу кілька способів відбору (наприклад, стратифікований та випадковий або випадковий та механічний); така вибірка називається комбінованої.
Види відбору
за видурозрізняються індивідуальний, груповий та комбінований відбір. При індивідуальному відборіу вибіркову сукупність відбираються окремі одиниці генеральної сукупності, груповий відбір- якісно однорідні групи (серії) одиниць, а комбінований відбірпередбачає поєднання першого та другого видів.
за методомвідбору розрізняють повторну та безповторнувибірку.
Безповторнимназивається відбір, у якому що потрапила вибірку одиниця не повертається у вихідну сукупність й у подальшому виборі бере участь; при цьому чисельність одиниць генеральної сукупності Nскорочується у процесі відбору. При повторномувідборі потрапилау вибірку одиниця після реєстрації повертається в генеральну сукупність і таким чином зберігає рівну можливість поряд з іншими одиницями використовуватися в подальшій процедурі відбору; при цьому чисельність одиниць генеральної сукупності Nзалишається незмінною (метод у соціально-економічних дослідженнях застосовується рідко). Однак, за великого N (N → ∞)формули для безповторноговідбору наближаються до аналогічних для повторноговідбору та практично частіше використовуються останні ( N = const).
Основні характеристики параметрів генеральної та вибіркової сукупності
В основі статистичних висновків проведеного дослідження лежить розподіл випадкової величини (х 1, х 2, …, х n)називаються реалізаціями випадкової величини Х(n - Обсяг вибірки). Розподіл випадкової величини в генеральній сукупності має теоретичний, ідеальний характер, а її вибірковий аналог є емпіричнимрозподілом. Деякі теоретичні розподіли задані аналітично, тобто. їх параметривизначають значення функції розподілу у кожній точці простору можливих значень випадкової величини. Для вибірки функцію розподілу визначити важко, а іноді неможливо, тому параметриоцінюють за емпіричними даними, а потім їх підставляють в аналітичний вираз, що описує теоретичний розподіл. При цьому припущення (або гіпотеза) Про вид розподілу може бути як статистично вірним, так і хибним. Але в будь-якому випадку відновлений за вибіркою емпіричний розподіл лише грубо характеризує справжнє. Найважливішими параметрами розподілу є математичне очікуваннята дисперсія.
За своєю природою розподілу бувають безперервнимиі дискретними. Найбільш відомим безперервним розподілом є нормальне. Вибірковими аналогами параметрів і для нього є: середнє значення та емпірична дисперсія. Серед дискретних у соціально-економічних дослідженнях найчастіше застосовується альтернативне (дихотомічне)Розподіл. Параметр математичного очікування цього розподілу виражає відносну величину (чи частку) одиниць сукупності, які мають досліджувану ознаку (вона позначена буквою ); частка сукупності, що не має цієї ознаки, позначається буквою q (q = 1 - p). Дисперсія альтернативного розподілу також має емпіричний аналог .
Залежно від виду розподілу та від способу відбору одиниць сукупності по-різному обчислюються характеристики параметрів розподілу. Основні з них для теоретичного та емпіричного розподілів наведені у табл. 9.1.
Часткою вибірки k nназивається відношення числа одиниць вибіркової сукупності до одиниць генеральної сукупності:
k n = n/N.
Вибіркова частка w- Це відношення одиниць, що володіють ознакою, що вивчається xдо обсягу вибірки n:
w = n n /n.
приклад.У партії товару, що містить 1000 од., при 5% вибірці частка вибірки k nв абсолютній величині складає 50 од. (n = N * 0,05); якщо ж у цій вибірці виявлено 2 браковані вироби, то вибіркова частка шлюбу wстановитиме 0,04 (w = 2/50 = 0,04 або 4%).
Так як вибіркова сукупність відмінна від генеральної, то виникають помилки вибірки.
Таблиця 9.1 Основні параметри генеральної та вибіркової сукупностей
Помилки вибірки
При будь-якому (суцільному та вибірковому) можуть зустрітися помилки двох видів: реєстрації та репрезентативності. Помилки реєстраціїможуть мати випадковийі систематичнийхарактер. Випадковіпомилки складаються з безлічі різних неконтрольованих причин, носять ненавмисний характер і зазвичай за сукупністю врівноважують один одного (наприклад, зміни показників приладу при температурних коливаннях у приміщенні).
Систематичніпомилки тенденційні, тому що порушують правила відбору об'єктів у вибірку (наприклад, відхилення у вимірах при зміні налаштування вимірювального приладу).
приклад.Для оцінки соціального становища населення місті передбачено обстежити 25% сімей. Якщо при цьому вибір кожної четвертої квартири ґрунтується на її номері, то існує небезпека відібрати всі квартири лише одного типу (наприклад, однокімнатні), що забезпечить систематичну помилку та спотворить результати; вибір же номера квартири за жеребом кращий, оскільки помилка буде випадковою.
Помилки репрезентативностіпритаманні лише вибірковому спостереженню, їх неможливо уникнути і вони виникають внаслідок того, що вибіркова сукупність в повному обсязі відтворює генеральну. Значення показників, одержуваних за вибіркою, відрізняються від показників цих самих величин у генеральній сукупності (або одержуваних при суцільному спостереженні).
Помилка вибіркового спостереженняє різниця між значенням параметра в генеральній сукупності та її вибірковим значенням. Для середнього значення кількісної ознаки вона дорівнює: , а частки (альтернативного ознаки) — .
Помилки вибірки властиві лише вибірковим спостереженням. Чим більше ці помилки, тим більше емпіричний розподіл відрізняється від теоретичного. Параметри емпіричного розподілу і є випадковими величинами, отже, помилки вибірки також є випадковими величинами, можуть приймати різні вибірки різні значення і тому прийнято обчислювати середню помилку.
Середня помилка вибіркиє величина, що виражає середнє квадратичне відхилення вибіркової середньої від математичного очікування. Ця величина за дотримання принципу випадкового відбору залежить передусім від обсягу вибірки і зажадав від ступеня варіювання ознаки: що більше і менше варіація ознаки (отже, і значення ), тим менше величина середньої помилки вибірки . Співвідношення між дисперсіями генеральної та вибіркової сукупностей виражається формулою:
тобто. при досить великих вважатимуться, що . Середня помилка вибірки показує можливі відхилення параметра вибіркової сукупності від генерального параметра. У табл. 9.2 наведено вирази для обчислення середньої помилки вибірки за різних методів організації спостереження.
Таблиця 9.2 Середня помилка (m) вибіркових середньої та частки для різних видів вибірки
Де - середня із внутрішньогрупових вибіркових дисперсій для безперервної ознаки;
Середня із внутрішньогрупових дисперсій частки;
- Кількість відібраних серій, - Загальна кількість серій;
 ,
,
де - Середня серії;
- загальна середня по всій вибірковій сукупності для безперервної ознаки;
 ,
,
де - частка ознаки в серії;
- Загальна частка ознаки по всій вибірковій сукупності.
Однак про величину середньої помилки можна судити лише з певною ймовірністю Р (Р ≤ 1). Ляпунов О.М. довів, що розподіл вибіркових середніх , а отже, та його відхилень від генеральної середньої, за досить великому числі приблизно підпорядковується нормальному закону розподілу за умови, що генеральна сукупність має кінцевої середньої та обмеженої дисперсією.
Математично це твердження для середньої виражається у вигляді:

а для частки вираз (1) набуде вигляду:
де  -
є гранична помилка вибіркияка кратна величині середньої помилки вибірки ,
а коефіцієнт кратності - є критерій Стьюдента ("коефіцієнт довіри"), запропонований У.С. Держсетом (псевдонім "Student"); значення для різного обсягу вибірки зберігаються у спеціальній таблиці.
-
є гранична помилка вибіркияка кратна величині середньої помилки вибірки ,
а коефіцієнт кратності - є критерій Стьюдента ("коефіцієнт довіри"), запропонований У.С. Держсетом (псевдонім "Student"); значення для різного обсягу вибірки зберігаються у спеціальній таблиці.

Отже, вираз (3) може бути прочитаний так: з ймовірністю Р = 0,683 (68,3%)можна стверджувати, що різниця між вибірковою та генеральною середньою не перевищить однієї величини середньої помилки m (t = 1)з ймовірністю Р = 0,954 (95,4%)що вона не перевищить величини двох середніх помилок m (t = 2) ,з ймовірністю Р = 0,997 (99,7%)- не перевищить трьох значень m (t = 3).Таким чином, ймовірність того, що ця різниця перевищить триразову величину середньої помилки, визначає рівень помилкиі становить не більше 0,3% .
У табл. 9.3 наведено формули для обчислення граничної помилки вибірки.
Таблиця 9.3 Гранична помилка (D) вибірки для середньої та частки (р) для різних видів вибіркового спостереження
Поширення вибіркових результатів на генеральну сукупність
Кінцевою метою вибіркового спостереження є характеристика генеральної сукупності. При малих обсягах вибірки емпіричні оцінки параметрів (і) можуть суттєво відхилятися від їх справжніх значень (і). Тому виникає необхідність встановити межі, у яких для вибіркових значень параметрів ( і ) лежать справжні значення ( і ).
Довірчим інтерваломбудь-якого параметра θгенеральної сукупності називається випадкова область значень цього параметра, яка з ймовірністю близькою до 1 ( надійністю) містить справжнє значення цього параметра.
Гранична помилкавибірки Δ дозволяє визначити граничні значення характеристик генеральної сукупності та їх довірчі інтервали, які рівні:
Нижня межа довірчого інтервалуотримана шляхом віднімання граничної помилкиз вибіркового середнього (частки), а верхня – шляхом її додавання.
Довірчий інтервалдля середньої використовує граничну помилку вибірки та для заданого рівня достовірності визначається за формулою:
Це означає, що із заданою ймовірністю Ряка називається довірчим рівнем і однозначно визначається значенням t, можна стверджувати, що справжнє значення середньої лежить у межах від ![]() а справжнє значення частки - в межах від
а справжнє значення частки - в межах від
Під час розрахунку довірчого інтервалу для трьох стандартних довірчих рівнів Р = 95%, Р = 99% та Р = 99,9%значення вибирається за . Програми в залежності від числа ступенів свободи. Якщо обсяг вибірки досить великий, то відповідні цим імовірностям значення tрівні: 1,96, 2,58 і 3,29 . Таким чином, гранична помилка вибірки дозволяє визначити граничні значення характеристик генеральної сукупності та їх довірчі інтервали:
Поширення результатів вибіркового спостереження на генеральну сукупність у соціально-економічних дослідженнях має свої особливості, оскільки потребує повноти представництва всіх її типів та груп. Основою для можливості такого розповсюдження є розрахунок відносної помилки:

де Δ % - відносна гранична помилка вибірки; , .
Існують два основні методи поширення вибіркового спостереження на генеральну сукупність: прямий перерахунок та спосіб коефіцієнтів.
Сутність прямого перерахункуполягає у множенні вибіркового середнього значення!! \ overline (x) на обсяг генеральної сукупності .
приклад. Нехай середня кількість дітей ясельного віку в місті оцінена вибірковим методом і склала людину. Якщо місті 1000 молодих сімей, кількість необхідних місць у муніципальних дитячих яслах отримують множенням цієї середньої чисельність генеральної сукупності N = 1000, тобто. становитиме 1200 місць.
Спосіб коефіцієнтівдоцільно використовувати у разі, коли вибіркове спостереження проводиться з метою уточнення даних суцільного спостереження.
При цьому використовують формулу:
де всі змінні - це чисельність сукупності:
Необхідний обсяг вибірки
Таблиця 9.4 Необхідний обсяг (n) вибірки для різних видів організації вибіркового спостереження
При плануванні вибіркового спостереження із заздалегідь заданим значенням припустимої помилки вибірки необхідно правильно оцінити необхідний обсяг вибірки. Цей обсяг може бути визначений на основі припустимої помилки при вибірковому спостереженні, виходячи із заданої ймовірності, що гарантує допустиму величину рівня помилки (з урахуванням способу організації спостереження). Формули визначення необхідної чисельності вибірки n легко отримати безпосередньо з формул граничної помилки вибірки. Так, з висловлювання для граничної помилки:
безпосередньо визначається обсяг вибірки n:
Ця формула показує, що зі зменшенням граничної помилки вибірки Δ істотно збільшується необхідний обсяг вибірки, який пропорційний дисперсії та квадрату критерію Стьюдента.
Для конкретного способу організації спостереження необхідний обсяг вибірки обчислюється згідно з формулами, наведеними в таблиці. 9.4.
Практичні приклади розрахунку
Приклад 1. Обчислення середнього значення та довірчого інтервалу для безперервної кількісної ознаки.
Для оцінки швидкості розрахунку з кредиторами у банку проведено випадкову вибірку 10 платіжних документів. Їх значення виявилися рівними (у днях): 10; 3; 15; 15; 22; 7; 8; 1; 19; 20.
Необхідно з ймовірністю Р = 0,954визначити граничну помилку Δ вибіркової середньої та довірчі межі середнього часу розрахунків.
Рішення.Середнє значення обчислюється за такою формулою з табл. 9.1 для вибіркової сукупності
![]()
Дисперсія обчислюється за такою формулою з табл. 9.1.
![]()
Середня квадратична похибка дня.
Помилка середньої обчислюється за такою формулою:
![]()
тобто. середнє значення дорівнює x ± m = 12,0 ± 2,3 дні.
Достовірність середнього склала
![]()
Граничну помилку обчислимо за такою формулою з табл. 9.3 для повторного відбору, оскільки чисельність генеральної сукупності невідома, та Р = 0,954рівня достовірності.
Таким чином, середнє значення дорівнює x ± D = x ± 2m = 12,0 ± 4,6, тобто. його справжнє значення лежить у межах від 7,4 до 16,6 днів.
Використання таблиці Стьюдента. Додатки дозволяє зробити висновок, що з n = 10 — 1 = 9 ступенів свободи отримане значення достовірно з рівнем значимості a £ 0,001, тобто. отримане значення середнього вірогідно відрізняється від 0.
Приклад 2. Оцінка ймовірності (генеральної частки) нар.
При механічному вибірковому способі обстеження соціального стану 1000 сімей виявлено, що частка малозабезпечених сімей склала w = 0,3 (30%)(вибірка була 2% , тобто. n/N = 0,02). Необхідно з рівнем достовірності р = 0,997визначити показник рмалозабезпечених сімей у всьому регіоні.
Рішення.За представленими значеннями функції Ф(t)знайдемо для заданого рівня достовірності Р = 0,997значення t = 3(Див. формулу 3). Граничну помилку частки wвизначимо за формулою із табл. 9.3 для безповторного відбору (механічна вибірка завжди є безповторною):
Гранична відносна помилка вибірки в % складе:
Імовірність (генеральна частка) малозабезпечених сімей у регіоні становитиме р=w±Δw, а довірчі межі р обчислюються виходячи з подвійної нерівності:
w - Δ w ≤ p ≤ w - Δ w, тобто. справжнє значення р лежить у межах:
0,3 — 0,014 < p <0,3 + 0,014, а именно от 28,6% до 31,4%.
Таким чином, із ймовірністю 0,997 можна стверджувати, що частка малозабезпечених сімей серед усіх сімей регіону становить від 28,6% до 31,4%.
приклад 3.Обчислення середнього значення та довірчого інтервалу для дискретної ознаки, заданої інтервальним рядом.
У табл. 9.5. подано розподіл заявок на виготовлення замовлень за термінами їх виконання підприємством.
Таблиця 9.5 Розподіл спостережень щодо термінів появиРішення. Середній термін виконання заявок обчислюється за такою формулою:
Середній термін складе:
= (3 * 20 + 9 * 80 + 24 * 60 + 48 * 20 + 72 * 20) / 200 = 23,1 міс.
Та ж відповідь отримаємо, якщо використовуємо дані про р i з передостанньої колонки табл. 9.5, використовуючи формулу:
Зауважимо, що середина інтервалу для останньої градації знаходиться шляхом її штучного доповнення шириною інтервалу попередньої градації, що дорівнює 60 - 36 = 24 міс.
Дисперсія обчислюється за формулою
![]()
де х i- Середина інтервального ряду.
Отже!!\sigma = \frac (20 2 + 14 2 + 1 + 25 2 + 49 2) (4), а середня квадратична похибка .
Помилка середньої обчислюється за такою формулою міс., тобто. середнє значення дорівнює!! \ overline (x) ± m = 23,1 ± 13,4.
Граничну помилку обчислимо за такою формулою з табл. 9.3 для повторного відбору, оскільки чисельність генеральної сукупності невідома, для 0,954 рівня достовірності:
Таким чином, середнє значення дорівнює:
тобто. його справжнє значення лежить у межах від 0 до 50 місяців.
приклад 4.Для визначення швидкості розрахунків із кредиторами N = 500 підприємств корпорації у комерційному банку необхідно провести вибіркове дослідження методом випадкового безповторного відбору. Визначити необхідний обсяг вибірки n, щоб із ймовірністю Р = 0,954 помилка середнього значення вибірки не перевищувала 3-х днів, якщо пробні оцінки показали, що середнє відхилення квадратне s склало 10 днів.
Рішення. Для визначення кількості необхідних досліджень n скористаємося формулою для відбору безповторного з табл. 9.4:

У ній значення t визначається з рівня достовірності Р = 0,954. Воно дорівнює 2. Середнє квадратичне значення s = 10, обсяг генеральної сукупності N = 500, а гранична помилка середнього значення Δ x = 3. Підставляючи ці значення формулу, отримаємо:
![]()
тобто. вибірку достатньо скласти із 41 підприємства, щоб оцінити необхідний параметр — швидкість розрахунків із кредиторами.
Генеральна сукупність(В англ. - population) - сукупність всіх об'єктів (одиниць), щодо яких вчений має намір робити висновки щодо конкретної проблеми.
Генеральна сукупність складається із усіх об'єктів, які підлягають вивченню. Склад генеральної сукупності залежить від цілей дослідження. Іноді генеральна сукупність - це населення певного регіону (наприклад, коли вивчається ставлення потенційних виборців до кандидата), найчастіше задається кілька критеріїв, визначальних об'єкт дослідження. Наприклад, чоловіки 30-50 років, які використовують бритву певної марки не рідше одного разу на тиждень, і мають дохід не нижче $100 на одного члена сім'ї.
Вибіркаабо вибіркова сукупність- безліч випадків (випробуваних, об'єктів, подій, зразків), за допомогою певної процедури обраних із генеральної сукупності для участі у дослідженні.
Характеристики вибірки:
Якісна характеристика вибірки – кого саме ми вибираємо та які способи побудови вибірки ми для цього використовуємо.
Кількісна характеристика вибірки – скільки випадків вибираємо, тобто обсяг вибірки.
Необхідність вибірки
Об'єкт дослідження дуже великий. Наприклад, споживачі продукції глобальної компанії – величезна кількість територіально розкиданих ринків.
Існує необхідність збору первинної інформації.
Обсяг вибірки
Обсяг вибірки- Число випадків, включених у вибіркову сукупність. Зі статистичних міркувань рекомендується, щоб кількість випадків становила не менше 30 – 35.
17. Основні способи формування вибірки
Формування вибіркиНасамперед ґрунтується на знанні контуру вибірки, під яким розуміється список усіх одиниць сукупності, з якого вибираються одиниці вибірки. Наприклад, якщо як сукупність розглядати всі автосервісні майстерні міста Москви, то треба мати список таких майстерень, що розглядається як контур, в межах якого формується вибірка.
Контур вибірки неминуче містить помилку, яка називається помилкою контуру вибірки і характеризує ступінь відхилення від справжніх розмірів сукупності. Вочевидь, що немає повно офіційного списку всіх автосервісних майстерень м. Москви. Дослідник повинен інформувати замовника роботи про розмір помилки контуру вибірки.
При формуванні вибірки використовуються імовірнісні (випадкові) та неймовірні (невипадкові) методи.
Якщо всі одиниці вибірки мають відомий шанс (імовірність) бути включеними у вибірку, то вибірка називається імовірнісною. Якщо ця можливість невідома, то вибірка називається неймовірною. На жаль, у більшості маркетингових досліджень через неможливість точного визначення розміру сукупності неможливо точно розрахувати ймовірності. Тому термін «відома ймовірність» скоріш грунтується на використанні певних методів формування вибірки, ніж знанні точних розмірів сукупності.
Імовірнісні методи включають:
Простий випадковий відбір;
Систематичний відбір;
кластерний відбір;
Стратифікований відбір.
Неймовірні методи:
Відбір з урахуванням принципу зручності;
Відбір з урахуванням суджень;
Формування вибірки у процесі опитування;
Формування вибірки з урахуванням квот.
Сенс методу відбору з урахуванням принципу зручності у тому, що формування вибірки здійснюється найзручнішим з позицій дослідника чином, наприклад з позицій мінімальних витрат часу і зусиль, з позицій доступності респондентів. Вибір місця дослідження та складу вибірки проводиться суб'єктивним чином, наприклад, опитування покупців здійснюється у магазині, найближчому до місця проживання дослідника. Очевидно, що багато представників сукупності не беруть участі в опитуванні.
Формування вибірки на основі судження ґрунтується на використанні думки кваліфікованих фахівців, експертів щодо складу вибірки. На основі такого підходу часто формується склад фокус-групи.
Формування вибірки в процесі опитування засноване на розширенні числа опитуваних, виходячи з пропозицій респондентів, які вже взяли участь в обстеженні. Спочатку дослідник формує вибірку набагато меншу, ніж потрібно для дослідження, потім у міру проведення розширюється.
Формування вибірки з урахуванням квот (квотний відбір) передбачає попереднє, з цілей дослідження, визначення чисельності груп респондентів, відповідальних певним вимогам (ознакам). Наприклад, з метою дослідження було ухвалено рішення, що в універмазі має бути опитано п'ятдесят чоловіків та п'ятдесят жінок. Інтерв'юер проводить опитування, доки не вибере встановлену квоту.
Дослідження зазвичай починається з деякого припущення, що вимагає перевірки із залученням фактів. Це припущення - гіпотеза - формулюється щодо зв'язку явищ чи властивостей у певній сукупності об'єктів. Для перевірки подібних припущень на фактах необхідно виміряти відповідні властивості їх носіїв. Але неможливо виміряти, наприклад, тривожність у всіх підлітків. Тому при проведенні дослідження обмежуються лише відносно невеликою групою представників відповідних сукупностей людей.
Генеральна сукупність- це безліч об'єктів, щодо якого формулюється дослідницька гіпотеза. Теоретично вважається, що обсяг генеральної сукупності не обмежений. Практично обсяг генеральної сукупності завжди обмежений і може бути різним залежно від предмета спостереження і того завдання, яке належить вирішувати психологу. Зазвичай генеральна сукупність включає у собі дуже багато об'єктів- студентів вузу, школярів, працівників підприємства, пенсіонерів тощо. Суцільне дослідження генеральних сукупностей надзвичайно важко, тому, зазвичай, вивчається невелика частина генеральної сукупності, звана вибірковою сукупністю, чи вибіркою.
Вибірка -це обмежена за чисельністю група об'єктів (у психології - випробуваних, респондентів), що спеціально відбирається з генеральної сукупності для вивчення її властивостей. Відповідно, вивчення вибірці властивостей генеральної сукупності називається вибірковим дослідженням. Майже всі психологічні дослідження є вибірковими, які висновки поширюються на генеральні сукупності.
До вибірки застосовується низка обов'язкових вимог, визначених насамперед цілями та завданнями дослідження. Вона має бути такою, щоб обгрунтувалася генералізація висновків вибіркового дослідження - узагальнення, поширення їх у генеральну сукупність.
Вибірка повинна задовольняти такі умови:
1. Це група об'єктів, доступна вивчення. Обсяг вибірки визначається завданнями та можливостями спостереження та експерименту.
2. Це частина наперед наміченої генеральної сукупності.
3. Це група, відібрана випадково так, щоб будь-який об'єкт генеральної сукупності мав однакову можливість потрапити у вибірку.
Основні критерії обґрунтованості висновків дослідження – це репрезентативність вибірки та статистична достовірність (емпіричних) результатів.
Репрезентативність -іншими словами, її представництво - це здатність характеризувати відповідну генеральну сукупність з певною точністю та достатньою надійністю. Якщо вибірка піддослідних за своїми характеристиками репрезентативна генеральної сукупності, тобто підстави, отримані під час вивчення результати поширити всю генеральну сукупність.
В ідеалі репрезентативна вибірка повинна бути такою, щоб кожна з основних характеристик, що вивчаються психологом, рис, особливостей особистості і т. п. представлялася в ній пропорційно цим же особливостям в генеральній сукупності.
Помилки репрезентативності виникають у двох випадках:
1. Мінімальна вибірка, що характеризує генеральну сукупність.
2. Розбіжність властивостей (параметрів) вибірки з параметрами генеральної сукупності.
Статистична достовірність, чи статистична значимість, результатів дослідження визначається з допомогою методів статистичного висновку. Ці методи будуть докладніше розглянуті у темі «Перевірка гіпотез». Зазначимо, що вони пред'являють певні вимоги до чисельності чи обсягу вибірки.
Найбільший обсяг вибірки необхідний розробки діагностичної методики - від 200 до 1000-2500 людина.
Якщо необхідно порівняти 2 вибірки, їхня загальна чисельність має бути не менше 50 осіб; чисельність порівнюваних вибірок має бути приблизно однаковою.
Якщо вивчається взаємозв'язок між будь-якими властивостями, то обсяг вибірки має бути не менше 30-35 осіб.
Чим більша мінливість досліджуваної властивості, тим більше має бути обсяг вибірки. Тому мінливість можна зменшити, збільшуючи однорідність вибірки, наприклад, за статтю, віком і т.д. При цьому, звісно, зменшуються можливості генералізації висновків.
Залежні та незалежні вибірки.Звичайна ситуація дослідження, коли дослідника, що цікавить, властивість вивчається на двох або більше вибірках з метою їх подальшого порівняння. Ці вибірки можуть у різних співвідношеннях - залежно від процедури їх організації. Незалежні вибірки характеризуються тим, що можливість відбору будь-якого випробуваного однієї вибірки залежить від відбору будь-якого з випробуваних іншої вибірки. Навпаки, залежні вибірки характеризуються тим, що кожному випробуваному однієї вибірки поставлено у відповідність за певним критерієм випробуваний з іншої вибірки.
Найбільш типовим прикладом незалежної вибірки є, наприклад, порівняння чоловіків та жінок за рівнем інтелекту.
Розподіл випадкової величини містить всю інформацію про її статистичні властивості. Чи багато знати значень випадкової величини, щоб побудувати її розподіл? Для цього слід досліджувати її генеральну сукупність.
Генеральна сукупність - безліч всіх значень, які може набувати дана випадкова величина.
Число одиниць у генеральній сукупності називається її обсягом N. Ця величина може бути кінцевою та нескінченною. Наприклад, якщо досліджується зростання жителів деякого міста, то обсяг генеральної сукупності дорівнюватиме кількості жителів міста. Якщо виконується будь-який фізичний експеримент, обсяг генеральної сукупності буде нескінченним, т.к. число всіх можливих значень будь-якого фізичного параметра дорівнює нескінченності.
Дослідження генеральної сукупності який завжди можливе і доцільно. Воно неможливе, якщо обсяг генеральної сукупності нескінченний. Але і при кінцевих обсягах повне дослідження не завжди виправдане, оскільки потребує великих витрат часу та праці, а абсолютна точність результатів зазвичай не потрібна. Менш точні результати, але із значно меншими витратами сил і коштів можна одержати щодо лише частини генеральної сукупності. Такі дослідження називаються вибірковими.
Статистичні дослідження, що проводяться тільки на частині генеральної сукупності, називаються вибірковими, а частина генеральної сукупності, що досліджується, називається вибіркою.
На малюнку 7.2 символічно показані генеральна сукупність та вибірка у вигляді множини та її підмножини.
Малюнок 7.2 Генеральна сукупність та вибірка
Працюючи з деяким підмножиною даної генеральної сукупності, що часто становить незначну її частину, ми отримуємо результати, за цілком цілком задовільні для практичних цілей. Дослідження здебільшого генеральної сукупності лише збільшує точність, але з змінює суті результатів, якщо вибірка взято правильно зі статистичної погляду.
Для того, щоб вибірка відображала властивості генеральної сукупності та результати були достовірними, вона має бути репрезентативної(представницькою).
У деяких генеральних сукупностей будь-яка їх частина є репрезентативною через їхню природу. Однак у більшості випадків необхідно вживати спеціальних заходів для забезпечення репрезентативності вибірок.
Однимз головних досягнень сучасної математичної статистики вважається розробка теорії та практики методу випадкових вибірок, що забезпечують репрезентативність відбору даних.
Вибіркові дослідження завжди програють точно порівняно з дослідженням всієї генеральної сукупності. Однак з цим можна змиритися, якщо величина похибки буде відомою. Очевидно, що чим більший обсяг вибірки наближатиметься до обсягу генеральної сукупності, тим похибка буде меншою. Звідси ясно, що проблеми статистичного висновку стають особливо актуальними під час роботи з малими вибірками ( N ? 10-50).
Необхідність проводити вибіркові дослідження може бути викликана різними причинами:
часто повне дослідження досліджуваного явища занадто дороге і тривале;
іноді можливість використання отриманої інформації при повному дослідженні може вичерпатися раніше, ніж завершиться процес підготовки;
у деяких випадках в результаті перевірки якості виробу відбувається знищення об'єкта, що досліджується.
Приклад:
припустимо, сукупність - це всі учні школи (600 осіб із 20 класів, по 30 осіб у кожному класі). Предмет вивчення – ставлення до куріння.
Генеральна сукупність- Це набір об'єктів, про які необхідно отримати інформацію.
Генеральна сукупність складається з усіх об'єктів, які мають якості, властивості, що цікавлять дослідника. Іноді генеральна сукупність — це все доросле населення певного регіону (наприклад, коли вивчається ставлення потенційних виборців до кандидата), найчастіше задається кілька критеріїв, які визначають об'єкти дослідження. Наприклад, жінки 10-89 років, використовують крем для рук певної марки не рідше одного разу на тиждень, і мають дохід не нижче 5 тисяч рублів на одного члена сім'ї.
Вибірка- Це невеликий набір об'єктів, витягнутих із генеральної сукупності.
Вибіркова сукупність — це необхідний дослідження мінімум результатів (випадків, випробуваних, об'єктів, подій, зразків) відібраних з допомогою певної процедури з генеральної сукупності.
Приклади:
виявлення реакції клієнтів фірми на нововведення, всі клієнти фірми є генеральною сукупністю. Ті клієнти, яких зателефонували, утворюють вибірку.
При аудиторської перевірки фірм із великою кількістю угод доводиться задовольнятися вивченням відібраного числа угод. Усі угоди фірми утворюють генеральну сукупність, відібрані вибірку.
Генеральну сукупність утворюють всі призовники певного року.
всі лампи, виготовлені певний час на деякому підприємстві, утворюють генеральну сукупність. Ті лампи, які відібрано для контролю, — вибір.
Вибірка може розглядатися як репрезентативна або нерепрезентативна. Вибірка буде репрезентативною під час обстеження великої групи людей, якщо всередині цієї групи є представники різних підгруп, тільки так можна зробити правильні висновки. .
Репрезентативність - відповідність характеристик вибірки характеристик популяції або генеральної сукупності в цілому.Репрезентативність визначає наскільки можливо узагальнювати результати дослідження із залученням певної вибірки на всю генеральну сукупність, з якої вона була зібрана.
Також репрезентативність можна визначити, як властивість вибіркової сукупності представляти параметри генеральної сукупності, значущі з погляду завдань дослідження.
Приклад:вибірка, що складається з 60 учнів старших класів, набагато гірше уявляє сукупність, ніж вибірка з тих же 60 осіб, до якої увійдуть по 3 учні з кожного класу. Головною причиною цього є нерівний віковий розподіл у класах. Отже, у першому випадку репрезентативність вибірки низька, а в другому репрезентативність висока (за інших рівних умов) .
Завдання 1.У місті, що налічує 253 000 мешканців, які мають право голосувати, досліджуйте політичні симпатії майбутніх виборців.
Рішення
Вибірку можна побудувати, опитуючи кожного 15 покупця, що виходить з великого торгового центру. Така вибірка відображатиме думку відвідувачів торговельного центру, але навряд чи представлятиме думку всіх мешканців міста.
Інший метод побудови вибірки – провести опитування за телефоном кожного 100-го мешканця міста, взявши номери з телефонного довідника. Така систематична вибірка дасть інформацію про точку зору групи людей, які мають телефон, знаходяться вдома та відповідають на телефонні дзвінки. Але вона не відбиває думки всіх мешканців міста.
Ще один спосіб побудувати вибірку може полягати в тому, щоб опитати учасників мітингу, організованого кількома політичними партіями. Така вибірка дасть інформацію про жителів, які беруть активну участь у політичному житті міста.
Отже, потрібні такі способи утворення вибірки, які представляли б усю генеральну сукупність, тобто вибірка має бути репрезентативною (представницькою).
Завдання 2.Визначити, чи є репрезентативною вибірка:
1) число автомобільних аварій у червні, якщо необхідно скласти статистичний звіт щодо аварій у місті за рік;
2) міські жителі при підрахунку числа автомобілів на душу населення країни;
3) люди віком від 40 до 50 років при з'ясуванні рейтингу молодіжної телепрограми.
Рішення
1) Вибірка не є репрезентативною. Влітку немає снігу та криги на дорогах, а це одна з основних причин аварій.
2) Вибірка не є репрезентативною. Зрозуміло, що у місті машин набагато більше, ніж у сільських районах. Це потрібно враховувати.
3) Вибірка не є репрезентативною. Люди віком від 40 до 50 років навряд чи виявлять інтерес до програми, орієнтованої на молодіжну аудиторію. При використанні такої вибірки рейтинг може сильно впасти, але це не відобразить реального стану речей. Для формування вибіркової сукупності застосовують різні способи відбору. Статистичні дані мають бути представлені так, щоб ними можна було скористатися.
Параметри генеральної сукупності та вибірки
N - генеральна сукупність, яка поділяється на страти N 1 , N 2 і таке інше.
Втратиє однорідними об'єктами з погляду статистичних характеристик (наприклад, населення ділиться на страти за віковими групами або соціальною приналежністю; підприємства — за галузями). І тут вибірки називаються стратифікованими.
N – обсяг вибірки.
В основі статистичних висновків проведеного дослідження лежить розподіл випадкової величини Х, спостерігаються значення х 1 , х 2 , х 3 називаються реалізаціями випадкової величини x.
Розподіл випадкової величини X у генеральній сукупності має теоретичний, ідеальний характер, а її вибірковий аналог є емпіричним розподілом
Для вибірки функцію розподілу визначити важко, а іноді неможливо, тому параметри оцінюють за емпіричними даними, а потім їх підставляють в аналітичний вираз, що описує теоретичний розподіл. При цьому припущення про вид розподілу може бути як статистично вірним, і помилковим.
Але в будь-якому випадку відновлений за вибіркою емпіричний розподіл лише грубо характеризує справжнє.
Найважливішими параметрами розподілів є математичне очікуванняата дисперсія σ 2- міра розкиду даних.
Стандартне відхиленняσ - ступінь відхилення даних спостережень чи множин від середнього значення.
Завдання 3.Михайло разом із своїми друзями вирішив виміряти зростання своїх собак (по холці). Знайдіть: - середнє значення; відхилення зростання.

Рішення
Математичне очікування чи середнє значення можна знайти за такою формулою:
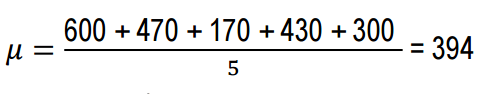
Тепер порахуємо відхилення зростання кожного собаки від середнього чи математичного очікування, тобто порахуємо дисперсію.


Стандартне відхилення це лише квадратний корінь з дисперсії.
σ \ = 147,32
Таким чином, знаючи стандартне відхилення ми знаємо, що означає «нормальне зростання», і що є дуже високим і дуже маленьким собакою.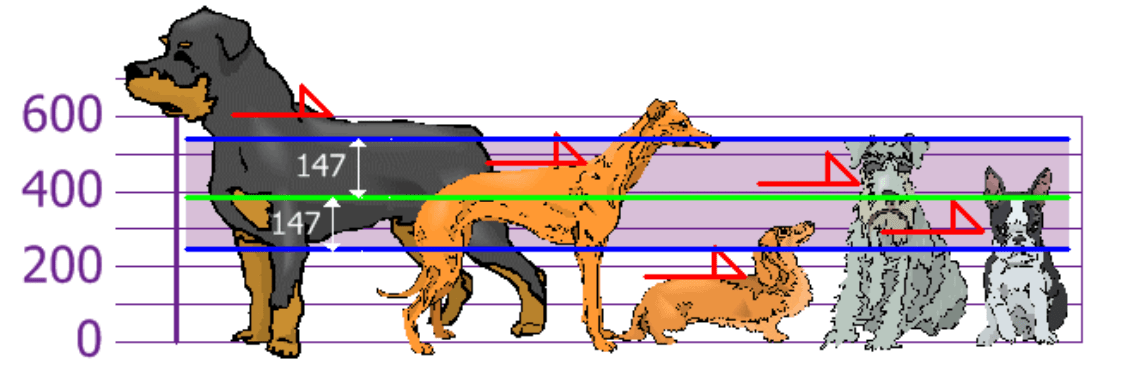
Відповідь: 394, 21,704; 147,32.
Завдання 4.Спостереження в контрольній лабораторії за терміном придатності 50 електроламп однакової потужності, взятих навмання з великої партії випущених заводом ламп цієї ж потужності, призвело до таких даних про порушення встановленого гарантійноготерміну горіння:
|
Відхилення у Ч |
10 мального розподілу, який відображає відхилення фактично готерміну горіння ламп від гарантійного. Рішення. Середнє відхилення
Таким чином, нормальний розподіл, що шукається, характеризується наступними значеннями параметрів: а = 0,4;σ 2 = 318; σ = 17,8. Звідси щільність ймовірності: Відповідна цій щільності функція розподілу виглядатиме: |



