Оцінка важливості параметрів рівняння регресії. Оцінка статистичної значущості рівняння регресії та її параметрів
Для коефіцієнтів регресійного рівняння перевірка їхнього рівня значимості здійснюється за t -критерію Стьюдента та за критерієм F Фішера. Нижче ми розглянемо оцінку достовірності показників регресії лише для лінійних рівнянь (12.1) та (12.2).
Y=a 0+ a 1 X(12.1)
Х = b 0+ b 1 Y(12.2)
Для цього типу рівнянь оцінюють за t-критерію Стьюдента лише величини коефіцієнтів а 1і b 1з використанням обчислення величини Тфза такими формулами:
Де r yxкоефіцієнт кореляції, а величину а 1можна обчислити за формулами 12.5 або 12.7.
Формула (12.27) використовується для обчислення величини Тф, а 1рівняння регресії Yпо X.

Величину b 1можна обчислити за формулами (12.6) або (12.8).
Формула (12.29) використовується для обчислення величини Тф,яка дозволяє оцінити рівень значущості коефіцієнта b 1рівняння регресії Xпо Y
приклад.Оцінимо рівень значущості коефіцієнтів регресії а 1і b 1рівнянь (12.17), та (12.18), отриманих при вирішенні задачі 12.1. Скористаємося для цього формулами (12.27), (12.28), (12.29) та (12.30).
Нагадаємо вид отриманих рівнянь регресії:
Y х = 3 + 0,06 X(12.17)
X y = 9+ 1 Y(12.19)
Величина а 1в рівнянні (12.17) дорівнює 0,06. Тому для розрахунку за формулою (12.27) слід підрахувати величину Sb y х.Відповідно до умови завдання величина п= 8. Коефіцієнт кореляції також був підрахований нами за формулою 12.9: r xy = √ 0,06 0,997 = 0,244 .
Залишилось обчислити величини Σ (у ι- y) 2 і Σ (х ι -x) 2, які у нас не підраховані. Найкраще ці розрахунки виконати в таблиці 12.2:
Таблиця 12.2
| № випробуваних п/п | х ι | у i | х ι –x | (х ι –x) 2 | у ι- y | (у ι- y) 2 |
| -4,75 | 22,56 | - 1,75 | 3,06 | |||
| -4,75 | 22,56 | -0,75 | 0,56 | |||
| -2,75 | 7,56 | 0,25 | 0,06 | |||
| -2,75 | 7,56 | 1,25 | 15,62 | |||
| 1,25 | 1,56 | 1,25 | 15,62 | |||
| 3,25 | 10,56 | 0,25 | 0,06 | |||
| 5,25 | 27,56 | -0,75 | 0,56 | |||
| 5,25 | 27,56 | 0,25 | 0,06 | |||
| Суми | 127,48 | 35,6 | ||||
| Середні | 12,75 | 3,75 |
Підставляємо отримані значення формулу (12.28), отримуємо:
Тепер розрахуємо величину Тфза формулою (12.27):

Величина Тфперевіряється до рівня значимості по таблиці 16 Додатка 1 для t-критерію Стьюдента. Число ступенів свободи в цьому випадку дорівнюватиме 8-2 = 6, тому критичні значення рівні відповідно для Р ≤ 0,05 t кр= 2,45 і для Р≤ 0,01 t кр=3,71. У прийнятій формі запису це виглядає так:

Будуємо «вісь значущості»:

Отримана величина Тф Алепро те, що величина коефіцієнта регресії рівняння (12.17) не відрізняється від нуля. Інакше кажучи, отримане рівняння регресії неадекватно вихідним експериментальним даним.
Розрахуємо тепер рівень значущості коефіцієнта b 1. Для цього необхідно обчислити величину Sb xyза формулою (12.30), на яку вже розраховані всі необхідні величини:
Тепер розрахуємо величину Тфза формулою (12.27):

Ми можемо відразу побудувати «вісь значущості», оскільки всі попередні операції були зроблені вище:

Отримана величина Тфпотрапила до зони незначущості, отже ми маємо прийняти гіпотезу Hпро те, що величина коефіцієнта регресії рівняння (12.19) не відрізняється від нуля. Інакше кажучи, отримане рівняння регресії неадекватно вихідним експериментальним даним.
Нелінійна регресія
Отриманий у попередньому розділі результат дещо бентежить: ми отримали, що обидва рівняння регресії (12.15) та (12.17) неадекватні експериментальним даним. Останнє сталося тому, що обидва ці рівняння характеризують лінійний зв'язок між ознаками, а ми у розділі 11.9 показали, що між змінними Xі Yє значна криволінійна залежність. Іншими словами, між змінними Хі Yу цій задачі необхідно шукати не лінійні, а криволінійні зв'язки. Зробимо це з використанням пакету «Стадія 6.0» (розробка А.П. Кулаїчова, реєстраційний номер 1205).
Завдання 12.2. Психолог хоче підібрати регресійну модель, адекватну експериментальним даним, отриманим у задачі 11.9.
Рішення.Це завдання вирішується простим перебором моделей криволінійної регресії, пропонованих у статистичному пакеті Стадія. Пакет організований таким чином, що до електронної таблиці, яка є вихідною для подальшої роботи, заносяться експериментальні дані у вигляді першого стовпця для змінної Xта другого стовпця для змінної Y.Потім переважно меню вибирається розділ Статистики, у ньому підрозділ - регресійний аналіз, у цьому підрозділі знову підрозділ - криволінійна регресія. В останньому меню надано формули (моделі) різних видів криволінійної регресії, згідно з якими можна обчислювати відповідні регресійні коефіцієнти і відразу ж перевіряти їх на значущість. Нижче розглянемо лише кілька прикладів роботи з готовими моделями (формулами) криволінійної регресії.
1. Перша модель - експонента . Її формула така:
![]()
При розрахунку за допомогою статпакету отримуємо а 0 = 1 і а 1 = 0,022.
Розрахунок рівня значимості для а, дав величину Р= 0,535. Вочевидь, що отримана величина незначна. Отже, ця регресійна модель неадекватна експериментальним даним.
2. Друга модель - статечна . Її формула така:
![]()
При підрахунку а про = - 5,29, а = 7,02 і а 1 = 0,0987.
Рівень значущості для а 1 - Р= 7,02 та для а 2 - Р = 0,991. Очевидно, що жоден із коефіцієнтів не значимий.
3. Третя модель – поліном . Її формула така:
Y= а 0 + а 1 X + а 2 X 2+ а 3 X 3
При підрахунку а 0= - 29,8, а 1 = 7,28, а 2 = - 0,488 та а 3 = 0,0103. Рівень значущості для а, - Р = 0,143, а 2 - Р = 0,2 і для а, - Р= 0,272
Висновок – дана модель неадекватна експериментальним даним.
4. Четверта модель – парабола .
Її формула така: Y = a o + a l -X 1 + а 2 Х 2
При підрахунку а 0 = - 9,88, а = 2,24 і а 1 = - 0,0839 Рівень значущості для а 1 - Р = 0,0186, для а 2 - Р = 0,0201. Обидва регресійні коефіцієнти виявилися значними. Отже, завдання вирішено – ми виявили форму криволінійної залежності між успішністю вирішення третього субтесту Векслера та рівнем знань з алгебри – це залежність параболічного виду. Цей результат підтверджує висновок, отриманий під час вирішення задачі 11.9 про наявність криволінійної залежності між змінними. Підкреслимо, що саме за допомогою криволінійної регресії було отримано точний вид залежності між змінними, що вивчаються.
Розділ 13 ФАКТОРНИЙ АНАЛІЗ
Основні поняття факторного аналізу
Факторний аналіз - статистичний метод, який використовується для обробки великих масивів експериментальних даних. Завданнями факторного аналізу є: скорочення кількості змінних (редукція даних) і структури взаємозв'язків між змінними, тобто. класифікація змінних, тому факторний аналіз використовується як метод скорочення даних чи метод структурної класифікації.
Важлива відмінність факторного аналізу від описаних вище методів у тому, що його не можна застосовувати для обробки первинних, чи, як кажуть, «сирих», експериментальних даних, тобто. отриманих безпосередньо під час обстеження піддослідних. Матеріалом для факторного аналізу є кореляційні зв'язки, а точніше - коефіцієнти кореляції Пірсона, які обчислюються між змінними (тобто психологічними ознаками), включеними в обстеження. Іншими словами, факторному аналізу піддають кореляційні матриці, або, як їх називають, матриці інтеркореляцій. Найменування стовпців і рядків у цих матрицях однакові, оскільки вони є переліком змінних, включених в аналіз. Тому матриці інтеркореляцій завжди квадратні, тобто. число рядків у яких дорівнює числу стовпців, і симетричні, тобто. на симетричних місцях щодо головної діагоналі стоять одні й самі коефіцієнти кореляції.
Необхідно наголосити, що вихідна таблиця даних, з якої виходить кореляційна матриця, не обов'язково має бути квадратною. Наприклад, психолог виміряв три показники інтелекту (вербальний, невербальний та загальний) та шкільні позначки з трьох навчальних предметів (література, математика, фізика) у 100 піддослідних - учнів дев'ятих класів. Вихідна матриця даних матиме розмір 100 × 6, а матриця інтеркореляцій розмір 6 × 6, оскільки в ній є лише 6 змінних. При такій кількості змінних матриця інтеркореляцій буде включати 15 коефіцієнтів і проаналізувати її не важко.
Однак уявімо, що станеться, якщо психолог отримає не 6, а 100 показників від кожного випробуваного. У цьому випадку він має аналізувати 4950 коефіцієнтів кореляції. Число коефіцієнтів у матриці обчислюється за формулою n (n+1)/2 і в нашому випадку дорівнює відповідно (100×99)/2=4950.
Очевидно, що провести візуальний аналіз такої матриці - завдання, яке важко реалізувати. Натомість психолог може виконати математичну процедуру факторного аналізу кореляційної матриці розміром 100 × 100 (100 випробуваних та 100 змінних) і таким чином отримати більш простий матеріал для інтерпретації експериментальних результатів.
Головне поняття факторного аналізу - фактор.Це штучний статистичний показник, що виникає в результаті спеціальних перетворень таблиці коефіцієнтів кореляції між психологічними ознаками, що вивчаються, або матриці інтеркореляцій. Процедура вилучення факторів із матриці інтеркореляцій називається факторизацією матриці. В результаті факторизації з кореляційної матриці може бути вилучено різну кількість факторів аж до числа, що дорівнює кількості вихідних змінних. Однак фактори, що виділяються внаслідок факторизації, як правило, нерівноцінні за своїм значенням.
Елементи факторної матриці називаютьсяабо вагами»; і вони є коефіцієнтами кореляції даного фактора з усіма показниками, використаними в дослідженні. Факторна матриця дуже важлива, оскільки вона показує, як досліджувані показники пов'язані з кожним виділеним фактором. При цьому факторна вага демонструє міру, або тісноту цього зв'язку.
Оскільки кожен стовпець факторної матриці (фактор) є свого роду змінною величиною, самі фактори також можуть корелювати між собою. Тут можливі два випадки: кореляція між чинниками дорівнює нулю, у разі чинники є незалежними (ортогональними). Якщо кореляція між факторами більша за нуль, то в такому разі фактори вважаються залежними (обличними). Підкреслимо, що ортогональні фактори на відміну від обличних дають простіші варіанти взаємодій усередині факторної матриці.
Як ілюстрації ортогональних чинників часто наводять завдання Л. Терстоуна, який, взявши ряд коробок різних розмірів та форми, виміряв у кожній з них більше 20 різних показників та обчислив кореляції між ними. Профакторизувавши отриману матрицю інтеркореляцій, він отримав три фактори, кореляція між якими дорівнювала нулю. Цими факторами були «довжина», «ширина» та «висота».
Щоб краще вловити сутність факторного аналізу, розберемо докладніше наступний приклад.
Припустимо, що психолог у випадкової вибірки студентів отримує такі дані:
V 1- вага тіла (у кг);
V 2 -кількість відвідувань лекцій та семінарських занять з предмета;
V 3- Довжина ноги (в см);
V 4- кількість прочитаних книг з предмета;
V 5- Довжина руки (в см);
V 6 -екзаменаційна оцінка з предмету ( V- Від англійського слова variable - змінна).
При аналізі цих ознак не позбавлено підстав припущення про те, що змінні V 1 ,До 3 і V 5- будуть пов'язані між собою, оскільки, чим більше людина, тим більше вона важить і тим довша її кінцівка. Сказане означає, що між цими змінними повинні вийти статистично значущі коефіцієнти кореляції, оскільки ці три змінні вимірюють деяку фундаментальну властивість індивідуумів у вибірці, а саме їх розміри. Так само ймовірно, що при обчисленні кореляцій між V 2 , V 4і V 6теж будуть отримані досить високі коефіцієнти кореляції, оскільки відвідування лекцій та самостійні заняття сприятимуть отриманню більш високих оцінок з предмета, що вивчається.
Таким чином, з усього можливого масиву коефіцієнтів, який виходить шляхом перебору пар ознак, що корелюються V 1і V 2 , V tі V 3і т.д., імовірно виділяться два блоки статистично значимих кореляцій. Решта кореляцій - між ознаками, які входять у різні блоки, навряд матиме статистично значимі коефіцієнти, оскільки зв'язок між такими ознаками, як розмір кінцівки і успішність з предмету, мають, швидше за все, випадковий характер. Отже, змістовний аналіз 6 наших змінних показує, що вони, по суті, вимірюють лише дві узагальнені характеристики, а саме: розміри тіла та ступінь підготовленості по предмету.
До матриці інтеркореляцій, тобто. обчисленим попарно коефіцієнтам кореляцій між усіма шістьма змінними V 1 - V 6допустимо застосувати факторний аналіз. Його можна проводити і вручну, за допомогою калькулятора, проте процедура подібної статистичної обробки дуже трудомістка. З цієї причини факторний аналіз проводиться на комп'ютерах, як правило, за допомогою стандартних статистичних пакетів. У всіх сучасних статистичних пакетах є програми для кореляційного та факторного аналізів. Комп'ютерна програма факторного аналізу по суті намагається «пояснити» кореляції між змінними в термінах невеликої кількості факторів (у нашому прикладі двох).
Припустимо, що, використовуючи комп'ютерну програму, ми отримали матрицю інтеркореляції всіх шести змінних і її факторного аналізу. В результаті факторного аналізу вийшла таблиця 13.1, яку називають "факторною матрицею", або "факторною структурною матрицею".
Таблиця 13.1
| Змінна | Чинник 1 | Фактор 2 |
| V 1 | 0,91 | 0,01 |
| V 2 | 0,20 | 0,96 |
| V 3 | 0,94 | -0,15 |
| V 4 | 0,11 | 0,85 |
| V 5 | 0,89 | 0,07 |
| V 6 | -0,13 | 0,93 |
За традицією фактори подаються у таблиці у вигляді стовпців, а змінні у вигляді рядків. Заголовки стовпців таблиці 13.1 відповідають номерам виділених факторів, але більш точно було б їх називати «факторні навантаження», або «ваги», за фактором 1, те саме за фактором 2. Як зазначалося вище, факторні навантаження, або ваги, є кореляціями між відповідною змінною та даним фактором. Наприклад, перше число 0,91 у першому факторі означає, що кореляція між першим фактором та змінною V 1дорівнює 0,91. Чим вище факторне навантаження по абсолютній величині, тим більший її зв'язок із фактором.
З таблиці 13.1 видно, що змінні V 1 V 3і V 5мають великі кореляції з фактором 1 (фактично змінна 3 має кореляцію близьку до 1 з фактором 1). Водночас змінні V 2 ,V 3 та У 5мають кореляції близькі до 0 з фактором 2. Подібно до цього фактор 2 високо корелює зі змінними V 2 , V 4і V 6і фактично не корелює зі змінними V 1,V 3 та V 5
В даному прикладі очевидно, що існують дві структури кореляцій, і, отже, вся інформація таблиці 13.1 визначається двома факторами. Тепер розпочинається заключний етап роботи – інтерпретація отриманих даних. Аналізуючи факторну матрицю, дуже важливо враховувати знаки факторних навантажень у кожному факторі. Якщо в тому самому факторі зустрічаються навантаження з протилежними знаками, це означає, що між змінними, що мають протилежні знаки, існує обернено пропорційна залежність.
Зазначимо, що з інтерпретації чинника для зручності можна змінити знаки всіх навантажень з цього чинника на протилежні.
Факторна матриця показує також які змінні утворюють кожен фактор. Це пов'язано насамперед із рівнем значущості факторної ваги. За традицією мінімальний рівень значущості коефіцієнтів кореляції в факторному аналізі береться рівним 0,4 або навіть 0,3 (за абсолютною величиною), оскільки немає спеціальних таблиць, за якими можна було б визначити критичні значення для рівня значущості факторної матриці. Отже, найпростіший спосіб побачити які змінні "належать" фактору - це означає відзначити ті з них, які мають навантаження вище, ніж 0,4 (або менше ніж - 0,4). Вкажемо, що в комп'ютерних пакетах іноді рівень значущості факторної ваги визначається самою програмою та встановлюється на вищому рівні, наприклад, 0,7.
Так, з таблиці 13.1 слід висновок, що фактор 1 - це поєднання змінних V 1До 3 і V 5(але не V 1 , K 4 і V 6 ,оскільки їх факторні навантаження за модулем менше ніж 0,4). Подібно до цього фактор 2 являє собою поєднання змінних V 2 , V 4і V 6 .
Виділений внаслідок факторизації чинник є сукупність тих змінних у складі включених до аналізу, які мають значні навантаження. Нерідко трапляється, однак, що в фактор входить тільки одна змінна зі значною факторною вагою, а інші мають незначне факторне навантаження. У цьому випадку фактор визначатиметься за назвою єдиною значущою змінною.
По суті фактор можна розглядати як штучну «одиницю» угруповання змінних (ознак) на основі наявних між ними зв'язків. Ця одиниця є умовною, тому що змінивши певні умови процедури факторизації матриці інтеркореляцій можна отримати іншу факторну матрицю (структуру). У новій матриці може бути іншим розподіл змінних за чинниками та його факторні навантаження.
У зв'язку з цим у факторному аналізі існує поняття "проста структура". Простий називають структуру факторної матриці, у якій кожна змінна має значні навантаження лише з одному з чинників, а самі чинники ортогональні, тобто. не залежать один від одного. У нашому прикладі два загальні чинники незалежні. Факторна матриця із простою структурою дозволяє провести інтерпретацію отриманого результату та дати найменування кожному фактору. У нашому випадку фактор перший – «розміри тіла», фактор другий – «рівень підготовленості».
Сказане вище не вичерпує змістовних можливостей факторної матриці. З неї можна отримати додаткові характеристики, що дозволяють детальніше досліджувати зв'язки змінних та факторів. Ці характеристики називаються «спільність» та «власне значення» фактора.
Проте, як уявити їх опис, вкажемо одне принципово важливе властивість коефіцієнта кореляції, завдяки якому отримують ці характеристики. Коефіцієнт кореляції, зведений у квадрат (тобто помножений сам на себе), показує, яка частина дисперсії (варіативності) ознаки є загальною для двох змінних, або, простіше кажучи, наскільки сильно ці змінні перекриваються. Так, наприклад, дві змінні з кореляцією 0,9 перекриваються зі ступенем 0,9 х 0,9 = 0,81. Це означає, що 81% дисперсії тієї та іншої змінної є загальними, тобто. збігаються. Нагадаємо, що факторні навантаження у факторній матриці - це коефіцієнти кореляції між факторами та змінними, тому, зведене у квадрат факторне навантаження характеризує ступінь спільності (або перекриття) дисперсій даної змінної та даного фактором.
Якщо отримані фактори не залежать один від одного («ортогональне» рішення), за ваги факторної матриці можна визначити, яка частина дисперсії є загальною для змінної та фактора. Обчислити, яка частина варіативності кожної змінної збігається з варіативністю факторів, можна простим підсумовуванням квадратів факторних навантажень за всіма факторами. З таблиці 13.1, наприклад, слід, що 0,91 × 0,91 + + 0,01 × 0,01 = 0,8282, тобто. близько 82% варіативності першої змінної «пояснюється» двома першими чинниками. Отримана величина називається спільністю змінної, у разі змінної V 1
Змінні можуть мати різний ступінь спільності з факторами. Змінна з більшою спільністю має значний ступінь перекриття (велику частку дисперсії) з одним чи кількома факторами. Низька спільність має на увазі, що всі кореляції між змінними та факторами невеликі. Це означає, що жоден із факторів не має збігаючої частки варіативності з даною змінною. Низька спільність може свідчити, що змінна вимірює щось якісно відрізняється від інших змінних, включених у аналіз. Наприклад, одна змінна, пов'язана з оцінкою мотивації серед завдань, що оцінюють здібності, матиме спільність з факторами здібностей, близьку до нуля.
Мала спільність може означати, що певне завдання відчуває на собі сильний вплив помилки вимірювання або вкрай складно для випробуваного. Можливо, навпаки, також, що завдання настільки просто, що кожен випробуваний дає на нього правильну відповідь, або завдання настільки нечітке за змістом, що випробуваний не розуміє суть питання. Таким чином, низька спільність має на увазі, що дана змінна не поєднується з факторами з однієї з причин: або змінна вимірює інше поняття, або змінна має велику помилку виміру, або існують спотворюють дисперсію ознаки відмінності між випробуваними у випадках відповіді на це завдання.
Зрештою, за допомогою такої характеристики, як власне значення фактора, можна визначити відносну значущість кожного з виділених факторів. І тому треба обчислити, яку частину дисперсії (варіативності) пояснює кожен чинник. Той фактор, який пояснює 45% дисперсії (перекриття) між змінними у вихідній кореляційній матриці, очевидно, є більш значущим, ніж інший, який пояснює лише 25% дисперсії. Ці міркування, однак, допустимі, якщо фактори ортогональні, інакше кажучи, не залежать один від одного.
Для того щоб обчислити власне значення фактора, потрібно звести в квадрат факторні навантаження і скласти їх по стовпцю. Використовуючи дані таблиці 13.1 можна переконатися, що власне значення фактора 1 складає 0,84 + (- 0,13) ×
× (-0,13)) = 2,4863. Якщо власне значення чинника розділити число змінних (6 у прикладі), то отримане число покаже, яка частка дисперсії пояснюється цим фактором. У разі вийде 2,4863∙100%/6 = 41,4%. Іншими словами, фактор 1 пояснює близько 41% інформації (дисперсії) вихідної кореляційної матриці. Аналогічний підрахунок другого фактора дасть 41,5%. У сумі це становитиме 82,9%.
Таким чином, два загальні фактори, об'єднані, пояснюють лише 82,9% дисперсії показників вихідної кореляційної матриці. Що трапилося з «залишилися» 17,1%? Справа в тому, що, розглядаючи кореляції між 6 змінними, ми зазначали, що кореляції розпадаються на два окремі блоки, і тому вирішили, що логічно аналізувати матеріал у поняттях двох факторів, а не 6, як і кількість вихідних змінних. Іншими словами, кількість конструктів, необхідних для опису даних, зменшилася з 6 (число змінних) до 2 (число загальних факторів). В результаті факторизації частина інформації у вихідній кореляційній матриці була принесена в жертву побудови двофакторної моделі. Єдиною умовою, за якої інформація не втрачається, був би розгляд шестифакторної моделі.
Оцінка значущості параметрів рівняння регресії
Оцінка значущості параметрів рівняння лінійної регресії провадиться за допомогою критерію Стьюдента:
якщо tрозрах. > tкр, то приймається основна гіпотеза ( H o), що свідчить про статистичну значущість параметрів регресії;
якщо tрозрах.< tкр, то приймається альтернативна гіпотеза ( H 1), що свідчить про статистичну незначущість параметрів регресії.
де m a , m b– стандартні помилки параметрів aі b:
 (2.19)
(2.19)
 (2.20)
(2.20)
Критичне (табличне) значення критерію знаходиться за допомогою статистичних таблиць розподілу Стьюдента (додаток Б) або за таблицями Excel(Розділ майстра функцій «Статистичні»):
tкр = СТЬЮДРАСПОБР( α=1-P; k=n-2), (2.21)
де k=n-2також являє собою число ступенів свободи .
Оцінка статистичної значимості може бути застосована і до лінійного коефіцієнта кореляції
де m r– стандартна помилка визначення значень коефіцієнта кореляції r yx
 (2.23)
(2.23)
Нижче наведено варіанти завдань для практичних та лабораторних робіт з тематики другого розділу.
Запитання для самоперевірки по 2 розділу
1. Вкажіть основні складові економетричної моделі та їхню сутність.
2. Основний зміст етапів економетричного дослідження.
3. Сутність підходів щодо визначення параметрів лінійної регресії.
4. Сутність та особливість застосування методу найменших квадратів при визначенні параметрів рівняння регресії.
5. Які показники використовуються для оцінки тісноти взаємозв'язку досліджуваних факторів?
6. Сутність лінійного коефіцієнта кореляції.
7. Сутність коефіцієнта детермінації.
8. Сутність та основні особливості процедур оцінки адекватності (статистичної значущості) регресійних моделей.
9. Оцінка адекватності лінійних регресійних моделей за коефіцієнтом апроксимації.
10. Сутність підходу оцінки адекватності регресійних моделей за критерієм Фішера. Визначення емпіричних та критичних значень критерію.
11. Сутність поняття «дисперсійний аналіз» стосовно економетричним дослідженням.
12. Сутність та основні особливості процедури оцінки значущості параметрів лінійного рівняння регресії.
13. Особливості застосування розподілу Стьюдента в оцінці значущості параметрів лінійного рівняння регресії.
14. У чому завдання прогнозу поодиноких значень досліджуваного соціально-економічного явища?
1. Побудувати поле кореляції та сформулювати припущення про форму рівняння взаємозв'язку досліджуваних факторів;
2. Записати основні рівняння методу найменших квадратів, зробити необхідні перетворення, скласти таблицю для проміжних розрахунків та визначити параметри лінійного рівняння регресії;
3. Здійснити перевірку правильності проведених обчислень за допомогою стандартних процедур та функцій електронних таблиць Excel.
4. Провести аналіз результатів, сформулювати висновки та рекомендації.
1. Розрахунок значення лінійного коефіцієнта кореляції;
2. Побудова таблиці дисперсійного аналізу;
3. Оцінка коефіцієнта детермінації;
4. Здійснити перевірку правильності проведених обчислень за допомогою стандартних процедур та функцій електронних таблиць Excel.
5. Провести аналіз результатів, сформулювати висновки та рекомендації.
4. Провести загальну оцінку адекватності обраного рівняння регресії;
1. Оцінка адекватності рівняння за значеннями коефіцієнта апроксимації;
2. Оцінка адекватності рівняння за значеннями коефіцієнта детермінації;
3. Оцінка адекватності рівняння за критерієм Фішера;
4. Провести загальну оцінку адекватності параметрів рівняння регресії;
5. Здійснити перевірку правильності проведених обчислень за допомогою стандартних процедур та функцій електронних таблиць Excel.
6. Провести аналіз результатів, сформулювати висновки та рекомендації.
1. Використання стандартних процедур майстра функцій електронних таблиць Excel (з розділів «Математичні» та «Статистичні»);
2. Підготовка даних та особливості застосування функції «ЛІНЕЙН»;
3. Підготовка даних та особливості застосування функції «ПЕРЕДСКАЗ».
1. Використання стандартних процедур пакету аналізу даних електронних таблиць Excel;
2. Підготовка даних та особливості застосування процедури «РЕГРЕСІЯ»;
3. Інтерпретація та узагальнення даних таблиці регресійного аналізу;
4. Інтерпретація та узагальнення даних таблиці дисперсійного аналізу;
5. Інтерпретація та узагальнення даних таблиці оцінки значущості параметрів рівняння регресії;
При виконанні лабораторної роботи за даними одного з варіантів необхідно виконати такі окремі завдання:
1. Здійснити вибір форми рівняння взаємозв'язку досліджуваних чинників;
2. Визначити параметри рівняння регресії;
3. Провести оцінку тісноти взаємозв'язку досліджуваних чинників;
4. Провести оцінку адекватності обраного рівняння регресії;
5. Здійснити оцінку статистичної значущості параметрів рівняння регресії.
6. Здійснити перевірку правильності проведених обчислень за допомогою стандартних процедур та функцій електронних таблиць Excel.
7. Провести аналіз результатів, сформулювати висновки та рекомендації.
Завдання для практичних та лабораторних робіт на тему «Парна лінійна регресія та кореляція в економетричних дослідженнях».
| Варіант 1 | Варіант 2 | Варіант 3 | Варіант 4 | Варіант 5 | |||||
| x | y | x | y | x | y | x | y | x | y |
| Варіант 6 | Варіант 7 | Варіант 8 | Варіант 9 | Варіант 10 | |||||
| x | y | x | y | x | y | x | y | x | y |
Після того як рівняння регресії побудовано та за допомогою коефіцієнта детермінації оцінено його точність, залишається відкритим питання за рахунок чого досягнуто цієї точності і відповідно чи можна цьому рівнянню довіряти. Справа в тому, що рівняння регресії будувалося не за генеральною сукупністю, яка невідома, а щодо вибірки з неї. Крапки з генеральної сукупності потрапляють у вибірку випадковим чином, тому відповідно до теорії ймовірності серед інших випадків можливий варіант, коли вибірка з “широкої” генеральної сукупності виявиться “вузькою” (рис. 15).
Мал. 15. Можливий варіант влучення точок у вибірку з генеральної сукупності.
В цьому випадку:
а) рівняння регресії, побудоване на вибірку, може значно відрізнятися від рівняння регресії для генеральної сукупності, що призведе до помилок прогнозу;
б) коефіцієнт детермінації та інші характеристики точності виявляться невиправдано високими і вводитимуть в оману про прогнозні якості рівняння.
У граничному випадку не виключений варіант, коли з генеральної сукупності хмара з головною віссю паралельної горизонтальної осі (відсутня зв'язок між змінними) за рахунок випадкового відбору буде отримана вибірка, головна вісь якої виявиться нахиленою до осі. Таким чином, спроби прогнозувати чергові значення генеральної сукупності спираючись на дані вибірки з неї загрожують не тільки помилками в оцінці сили та напряму зв'язку між залежною та незалежною змінними, але й небезпекою знайти зв'язок між змінними там, де насправді її немає.
В умовах відсутності інформації про всі точки генеральної сукупності єдиний спосіб зменшити помилки в першому випадку полягає у використанні при оцінці коефіцієнтів рівняння регресії методу, що забезпечує їх незміщеність та ефективність. А ймовірність настання другого випадку може бути значно знижена завдяки тому, що апріорі відома одна властивість генеральної сукупності з двома незалежними один від одного змінними – в ній відсутня саме цей зв'язок. Досягається це зниження з допомогою перевірки статистичної значимості отриманого рівняння регресії.
Один з варіантів перевірки, що найчастіше використовуються, полягає в наступному. Для отриманого рівняння регресії визначається -статистика - характеристика точності рівняння регресії, що є відношенням тієї частини дисперсії залежною змінною яка пояснена рівнянням регресії до непоясненої (залишкової) частини дисперсії. Рівняння для визначення статистики у разі багатовимірної регресії має вигляд:

де: - Пояснена дисперсія - частина дисперсії залежною змінною Y яка пояснена рівнянням регресії;
Залишкова дисперсія - частина дисперсії залежною змінною Y яка не пояснена рівнянням регресії, її наявність є наслідком дії випадкової складової;
Число точок у вибірці;
Число змінних у рівнянні регресії.
Як видно з наведеної формули, дисперсії визначаються як окреме від поділу відповідної суми квадратів на число ступенів свободи. Число ступенів свободи це мінімально необхідне число значень залежної змінної, яких достатньо для отримання шуканої характеристики вибірки і які можуть вільно змінюватись з урахуванням того, що для цієї вибірки відомі всі інші величини, що використовуються для розрахунку потрібної характеристики.
Для отримання залишкової дисперсії потрібні коефіцієнти рівняння регресії. У разі парної лінійної регресії коефіцієнтів два, тому відповідно до формули (беручи ) число ступенів свободи дорівнює . Мається на увазі, що для визначення залишкової дисперсії достатньо знати коефіцієнти рівняння регресії і лише значень залежної змінної вибірки. Два значення, що залишилися, можуть бути обчислені на підставі цих даних, а значить, не є вільно варіюються.
Для обчислення поясненої дисперсії значень залежної змінної взагалі не потрібні, оскільки її можна обчислити, знаючи коефіцієнти регресії при незалежних змінних та дисперсію незалежної змінної. Для того щоб переконатися в цьому, достатньо згадати вираз, що наводився раніше. ![]() . Тому число ступенів свободи для залишкової дисперсії дорівнює числу незалежних змінних у рівнянні регресії (для парної лінійної регресії).
. Тому число ступенів свободи для залишкової дисперсії дорівнює числу незалежних змінних у рівнянні регресії (для парної лінійної регресії).
В результаті критерій для рівняння парної лінійної регресії визначається за формулою:
 .
.
Теоретично ймовірності доведено, що критерій рівняння регресії, отриманого для вибірки з генеральної сукупності, у якої відсутній зв'язок між залежною і незалежною змінною має розподіл Фішера, досить добре вивчений. Завдяки цьому для будь-якого значення критерію можна розрахувати ймовірність його появи і навпаки, визначити те значення критерію яке він не зможе перевищити із заданою ймовірністю.
Для здійснення статистичної перевірки значущості рівняння регресії формулюється нульова гіпотеза про відсутність зв'язку між змінними (всі коефіцієнти при змінних дорівнюють нулю) і вибирається рівень значущості.
Рівень значущості – це припустима можливість зробити помилку першого роду – відкинути внаслідок перевірки правильну нульову гіпотезу. У даному випадку зробити помилку першого роду означає визнати за вибіркою наявність зв'язку між змінними в генеральній сукупності, коли насправді її там немає.
Зазвичай рівень значущості приймається рівним 5% чи 1%. Що рівень значимості (що менше ), то вище рівень надійності тесту, рівний , тобто. Тим більше шанс уникнути помилки визнання щодо вибірки наявності зв'язку у генеральної сукупності насправді незв'язаних між собою змінних. Але зі зростанням рівня значущості зростає небезпека скоєння помилки другого роду – відкинути правильну нульову гіпотезу, тобто. не помітити за вибіркою наявний насправді зв'язок змінних у генеральній сукупності. Тому залежно від того, яка помилка має великі негативні наслідки, вибирають той чи інший рівень значущості.
Для обраного рівня значущості за розподілом Фішера визначається табличне значення ймовірність перевищення, якого у вибірці потужністю, отриманої з генеральної сукупності без зв'язку між змінними, не перевищує рівня значущості. порівнюється з фактичним значенням критерію для регресійного рівняння.
Якщо виконується умова, то помилкове виявлення зв'язку зі значенням -критерію рівним або більшим за вибіркою з генеральної сукупності з незв'язаними між собою змінними відбуватиметься з ймовірністю меншою за рівень значущості. Відповідно до правила "дуже рідкісних подій не буває", приходимо до висновку, що встановлений за вибіркою зв'язок між змінними є і в генеральній сукупності, з якої вона отримана.
Якщо виявляється , то рівняння регресії статистично не значимо. Іншими словами існує реальна ймовірність того, що за вибіркою встановлено не існує в реальності зв'язок між змінними. До рівняння, що не витримало перевірку на статистичну значущість, ставляться так само, як і до ліків з терміном, що минув термін придатності.
Ті – такі ліки не обов'язково зіпсовані, але якщо немає впевненості у їхній якості, то їх вважають за краще не використовувати. Це правило не вберігає від усіх помилок, але дозволяє уникнути найбільш грубих, що також досить важливо.
Другий варіант перевірки, зручніший у разі використання електронних таблиць, це зіставлення ймовірності появи отриманого значення -критерію з рівнем значущості. Якщо ця можливість виявляється нижче рівня значимості , отже рівняння статистично значуще, інакше немає.
Після того, як виконано перевірку статистичної значущості регресійного рівняння в цілому корисно, особливо для багатовимірних залежностей здійснити перевірку на статистичну значущість отриманих коефіцієнтів регресії. Ідеологія перевірки така ж як і при перевірці рівняння в цілому але як критерій використовується - критерій Стьюдента, що визначається за формулами:
 і
і 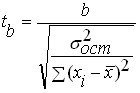
де: - значення критерію Стьюдента для коефіцієнтів і відповідно;
 - Залишкова дисперсія рівняння регресії;
- Залишкова дисперсія рівняння регресії;
Число точок у вибірці;
Число змінних у вибірці, для парної лінійної регресії.
Отримані фактичні значення критерію Стьюдента порівнюються з табличними значеннями ![]() отриманими з розподілу Стьюдента. Якщо виявляється, що , то відповідний коефіцієнт статистично значущий, інакше немає. Другий варіант перевірки статистичної значущості коефіцієнтів - визначити ймовірність появи критерію Стьюдента і порівняти з рівнем значущості.
отриманими з розподілу Стьюдента. Якщо виявляється, що , то відповідний коефіцієнт статистично значущий, інакше немає. Другий варіант перевірки статистичної значущості коефіцієнтів - визначити ймовірність появи критерію Стьюдента і порівняти з рівнем значущості.
Для змінних, чиї коефіцієнти виявилися статистично не значущими, велика ймовірність того, що їх вплив на залежну змінну в генеральній сукупності взагалі відсутній. Тому або необхідно збільшити кількість точок у вибірці, тоді можливо коефіцієнт стане статистично значущим і заодно уточниться його значення, або як незалежні змінні знайти інші, більш тісно пов'язані з залежною змінною. Точність прогнозування у разі обох випадках зросте.
Як експресний метод оцінки значущості коефіцієнтів рівняння регресії можна застосовувати таке правило - якщо критерій Стьюдента більше 3, то такий коефіцієнт, як правило, виявляється статистично значущим. А взагалі вважається, що для отримання статистично значимих рівнянь регресії необхідно, щоб виконувалася умова.
Стандартна помилка прогнозування отриманого рівняння регресії невідомого значення при відомому оцінюють за формулою:

Таким чином, прогноз з довірчою ймовірністю 68% може бути представлений у вигляді:
Якщо потрібна інша довірча ймовірність, то для рівня значущості необхідно знайти критерій Стьюдента і довірчий інтервал для прогнозу з рівнем надійності дорівнюватиме ![]() .
.
Прогнозування багатовимірних та нелінійних залежностей
Якщо прогнозована величина залежить від кількох незалежних змінних, то цьому випадку є багатовимірна регресія виду:
де: - Коефіцієнти регресії, що описують вплив змінних на прогнозовану величину.
Методика визначення коефіцієнтів регресії не відрізняється від парної лінійної регресії, особливо при використанні електронної таблиці, так як там застосовується та сама функція і для парної і для багатовимірної лінійної регресії. У цьому бажано щоб між незалежними змінними були відсутні взаємозв'язки, тобто. зміна однієї змінної не позначалося на значення інших змінних. Але ця вимога не є обов'язковою, важливо щоб між змінними були відсутні функціональні лінійні залежності. Описані вище процедури перевірки статистичної значущості отриманого рівняння регресії та її окремих коефіцієнтів, оцінка точності прогнозування залишається як і для випадку парної лінійної регресії. У той же час застосування багатомірних регресій замість парної зазвичай дозволяє при належному виборі змінних суттєво підвищити точність опису поведінки залежної змінної, а отже, і точність прогнозування.
Крім цього, рівняння багатовимірної лінійної регресії дозволяють описати і нелінійну залежність прогнозованої величини від незалежних змінних. Процедура приведення нелінійного рівняння до лінійного виду називається лінеаризацією. Зокрема, якщо ця залежність описується поліномом ступеня відмінного від 1, то, здійснивши заміну змінних зі ступенями відмінними від одиниці на нові змінні в першому ступені, отримуємо завдання багатовимірної лінійної регресії замість нелінійної. Так, наприклад, якщо вплив незалежної змінної описується параболою виду
![]()
то заміна дозволяє перетворити нелінійне завдання до багатовимірного лінійного вигляду
![]()
Так само легко можуть бути перетворені нелінійні завдання, у яких нелінійність виникає внаслідок того, що прогнозована величина залежить від твору незалежних змінних. Для обліку такого впливу необхідно запровадити нову змінну, що дорівнює цьому твору.
У тих випадках, коли нелінійність описується складнішими залежностями, лінеаризація можлива за рахунок перетворення координат. Для цього розраховуються значення ![]() та будуються графіки залежності вихідних точок у різних комбінаціях перетворених змінних. Та комбінація перетворених координат або перетворених і не перетворених координат, в якій залежність найближче до прямої лінії підказує заміну змінних, яка призведе до перетворення нелінійної залежності до лінійного вигляду. Наприклад, нелінійна залежність виду
та будуються графіки залежності вихідних точок у різних комбінаціях перетворених змінних. Та комбінація перетворених координат або перетворених і не перетворених координат, в якій залежність найближче до прямої лінії підказує заміну змінних, яка призведе до перетворення нелінійної залежності до лінійного вигляду. Наприклад, нелінійна залежність виду
перетворюється на лінійну вигляду
Отримані коефіцієнти регресії для перетвореного рівняння залишаються незміщеними та ефективними, але перевірка статистичної значущості рівняння та коефіцієнтів неможлива
Перевірка обґрунтованості застосування методу найменших квадратів
Застосування методу найменших квадратів забезпечує ефективність та несмещенность оцінок коефіцієнтів рівняння регресії за дотримання наступних умов (умов Гауса-Маркова):
3. значення не залежать один від одного
4. значення не залежать від незалежних змінних
Найбільш просто можна перевірити дотримання цих умов шляхом побудови графіків залишків залежно від , Потім від незалежної (незалежних) змінних. Якщо точки на цих графіках розташовані в коридорі розташованому симетрично осі абсцис і розташування точок не проглядаються закономірності, то умови Гауса-Маркова виконані і можливості підвищити точність рівняння регресії відсутні. Якщо це не так, то існує можливість суттєво підвищити точність рівняння і для цього необхідно звернутись до спеціальної літератури.
100 рбонус за перше замовлення
Оберіть тип роботи Дипломна робота Курсова робота Реферат Магістерська дисертація Звіт з практики Стаття Доповідь Рецензія Контрольна робота Монографія Рішення задач Бізнес-план Відповіді на запитання Творча робота Есе Чертеж Твори Переклад Презентації Набір тексту Інше Підвищення унікальності тексту
Дізнатись ціну
Після того, як знайдено рівняння лінійної регресії, проводиться оцінка значущості як рівнянняв цілому, так і окремих його параметрів. Перевірити значущість рівняння регресії– означає встановити, чи відповідає математична модель, що виражає залежність між змінними, експериментальним даним і чи достатньо включених до рівняння пояснюючих змінних (однієї або кількох) для опису залежної змінної. Щоб мати загальне судження про якість моделі з відносних відхилень щодо кожного спостереження, визначають середню помилку апроксимації: Середня помилка апроксимації не повинна перевищувати 8–10%.
Оцінка значущості рівняння регресії загалом проводиться на основі F-критерія Фішера, якому передує дисперсійний аналіз Відповідно до основної ідеї дисперсійного аналізу, загальна сума квадратів відхилень змінної yвід середнього значення yрозкладається на дві частини - "пояснену" і "непояснену": де - загальна сума квадратів відхилень; - Сума квадратів відхилень, пояснена регресією (або факторна сума квадратів відхилень); ![]() - Залишкова сума квадратів відхилень, що характеризує вплив неврахованих в моделі факторів. Визначення дисперсії однією ступінь свободи призводить дисперсії до порівняльного виду. Зіставляючи факторну та залишкову дисперсії в розрахунку на один ступінь свободи, отримаємо величину F-критерія Фішера:
- Залишкова сума квадратів відхилень, що характеризує вплив неврахованих в моделі факторів. Визначення дисперсії однією ступінь свободи призводить дисперсії до порівняльного виду. Зіставляючи факторну та залишкову дисперсії в розрахунку на один ступінь свободи, отримаємо величину F-критерія Фішера:  Фактичне значення F-критерія Фішера порівнюється з
Фактичне значення F-критерія Фішера порівнюється з
табличним значенням Fтабл(a; k 1; k 2) при рівні значимості a та ступенях свободи k 1 = mі k 2= n-m-1.При цьому, якщо фактичне значення F- критерію більше табличного, то визнається статистична значущість рівняння загалом.
Для парної лінійної регресії m=1, тому 
Величина F-критерія пов'язана з коефіцієнтом детермінації R2 її можна розрахувати за такою формулою: 
У парній лінійній регресії оцінюється значимість як рівняння загалом, а й окремих його. параметрів. З цією метою щодо кожного з параметрів визначається його стандартна помилка: m bі m a. Стандартна помилка коефіцієнта регресії визначається за такою формулою:  , де
, де 
Величина стандартної помилки спільно з t-розподілом Стьюдента при n-2 ступенях свободи застосовується для перевірки суттєвості коефіцієнта регресії та для розрахунку його довірчого інтервалу. Для оцінки суттєвості коефіцієнта регресії його величина порівнюється зі стандартною помилкою, тобто. визначається фактичне значення t-критерія Стьюдента: яке потім порівнюється з табличним значенням при певному рівні значущості a та числі ступенів свободи (n-2). Довірчий інтервал для коефіцієнта регресії визначається як b± tтабл × mb. Оскільки знак коефіцієнта регресії вказує на зростання результативної ознаки yзі збільшенням ознаки-фактора x(b>0), зменшення результативної ознаки зі збільшенням ознаки-фактора ( b<0) или его независимость от независимой переменной (b=0), то межі довірчого інтервалу для коефіцієнта регресії не повинні містити суперечливих результатів, наприклад -1,5 £ b£0,8. Такі запис вказує, що справжнє значення коефіцієнта регресії одночасно містить позитивні і негативні величини і навіть нуль, чого може бути.
Стандартна помилка параметра a
визначається за формулою:  Процедура оцінювання суттєвості даного параметра не відрізняється від розглянутої вище коефіцієнта регресії. Обчислюється t-Критерій: , Його величина порівнюється з табличним значенням при n- 2 степенях свободи.
Процедура оцінювання суттєвості даного параметра не відрізняється від розглянутої вище коефіцієнта регресії. Обчислюється t-Критерій: , Його величина порівнюється з табличним значенням при n- 2 степенях свободи.
Перевірку значущості рівняння регресії зробимо на основі
F-критерія Фішера:
Значення F-критерію Фішера можна знайти у таблиці Дисперсійний аналіз протоколу Еxcel. Табличне значення F-критерію при довірчій ймовірності α = 0,95 і числі ступенів свободи, що дорівнює v1 = k = 2 і v2 = n - k - 1 = 50 - 2 - 1 = 47, становить 0,051.
Оскільки Fрасч > Fтабл, рівняння регресії слід визнати значним, тобто його можна використовуватиме аналізу та прогнозування.
Оцінку значимості коефіцієнтів отриманої моделі, використовуючи результати звіту Excel, можна здійснити трьома способами.
Коефіцієнт рівняння регресії визнається значущим у тому разі, якщо:
1) спостерігається значення t-статистики Стьюдента для цього коефіцієнта більше, ніж критичне (табличне) значення статистики Стьюдента (для заданого рівня значущості, наприклад α = 0,05, та числа ступенів свободи df = n – k – 1, де n – число спостережень, а k – число чинників моделі);
2) Р-значення t-статистики Стьюдента для цього коефіцієнта менше, ніж рівень значущості, наприклад α = 0,05;
3) довірчий інтервал для цього коефіцієнта, обчислений з деякою довірчою ймовірністю (наприклад, 95%), не містить нуль у собі, тобто нижня 95% і верхня 95% межі довірчого інтервалу мають однакові знаки.
Значення коефіцієнтів a1 і a2 перевіримо по другому та третьому способам:
P-значення ( a1 ) = 0,00 < 0,01 < 0,05.
Р-значення ( a2 ) = 0,00 < 0,01 < 0,05.
Отже, коефіцієнти a1 і a2 значущі за 1%-ном рівні, а тим паче при 5%-ном рівні значимості. Нижні та верхні 95% межі довірчого інтервалу мають однакові знаки, отже, коефіцієнти a1 і a2 значущі.
Визначення пояснюючої змінної, від якої
Може залежати дисперсія випадкових збурень.
Перевірка виконання умови гомоскедастичності
Залишків по тесту Гольдфельда-Квандта
При перевірці передумови МНК про гомоскедастичність залишків у моделі множинної регресії слід спочатку визначити, стосовно якого з факторів дисперсія залишків найбільше порушена. Це можна зробити в результаті візуального дослідження графіків залишків, побудованих за кожним із факторів, включених у модель. Та з пояснюючих змінних, від якої більше залежить дисперсія випадкових обурень, і буде впорядкована за зростанням фактичних значень під час перевірки тесту Гольдфельда-Квандта. Графіки легко отримати у звіті, який формується в результаті використання інструменту Регресія у пакеті Аналіз даних).


Графіки залишків по кожному з факторів двофакторної моделі
З представлених графіків видно, що дисперсія залишків найбільше порушена стосовно фактора Короткострокова дебіторська заборгованість.
Перевіримо наявність гомоскедастичності у залишках двофакторної моделі на основі тесту Гольдфельда-Квандта.
Приберемо із середини впорядкованої сукупності С = 1/4 · n = 1/4 · 50 = 12,5 (12) значення. В результаті отримаємо дві сукупності відповідно з малими та великими значеннями Х4.
Для кожної сукупності виконаємо розрахунки:
Упорядкуємо змінні Y і X2 за зростанням фактора Х4 (в Excel для цього можна використовувати команду Дані - Сортування за зростанням Х4):
|
Дані відсортовані за зростанням X4: |
||
|
Сума |
111234876536,511 |
||||
|
966570797682,068 |
|||||
|
455748832843,413 |
|||||
|
232578961097,877 |
|||||
|
834043911651,192 |
|||||
|
193722998259,505 |
|||||
|
1246409153509,290 |
|||||
|
31419681912489,100 |
|||||
|
2172804245053,280 |
|||||
|
768665257272,099 |
|||||
|
2732445494273,330 |
|||||
|
163253156450,331 |
|||||
|
18379855056009,900 |
|||||
|
10336693841766,000 |
|||||
|
Сума |
69977593738424,600 |
Рівняння для сукупностей
Y = -27275,746 + 0,126 X2 + 1,817 X4
Y = 61439,511 + 0,228 X2 + 0,140 X4
Результати даної таблиці отримано за допомогою інструмента Регресія по черзі до кожної з отриманих сукупностей.
4. Знайдемо ставлення отриманих залишкових сум квадратів
(у чисельнику має бути велика сума):
5. Висновок про наявність гомоскедастичності залишків робимо за допомогою F-критерію Фішера з рівнем значущості α = 0,05 та двома однаковими ступенями свободи k1 = k2 = == 17
де р - Число параметрів рівняння регресії:
Fтабл (0,05; 17; 17) = 9,28.
Так як Fтабл> R, то підтверджується гомоскедастичність в залишках двофакторної регресії.


