Довірчий інтервал. Довірчий інтервал для математичного очікування
Довірчий інтервал прийшов до нас із галузі статистики. Це певний діапазон, який слугує для оцінки невідомого параметра з високим ступенем надійності. Найпростіше це пояснити на прикладі.
Припустимо, слід досліджувати якусь випадкову величину, наприклад, швидкість відгуку сервера на запит клієнта. Щоразу, коли користувач набирає адресу конкретного сайту, сервер реагує з різною швидкістю. Таким чином, час відгуку, що досліджується, має випадковий характер. Так ось, довірчий інтервал дозволяє визначити межі цього параметра, і потім можна буде стверджувати, що з ймовірністю 95% сервера буде знаходитися в розрахованому нами діапазоні.
Або потрібно дізнатися, якій кількості людей відомо про торгову марку фірми. Коли буде підрахований довірчий інтервал, можна буде, наприклад, сказати що з 95% часткою ймовірності частка споживачів, знають про цю перебуває у діапазоні від 27% до 34%.
З цим терміном тісно пов'язана така величина як довірча ймовірність. Вона є ймовірністю того, що шуканий параметр входить у довірчий інтервал. Від цієї величини залежить те, наскільки більшим виявиться наш пошуковий діапазон. Що більше значення вона набуває, то вже стає довірчий інтервал, і навпаки. Зазвичай її встановлюють 90%, 95% або 99%. Величина 95% найпопулярніша.
На цей показник також впливає дисперсія спостережень і Його визначення ґрунтується на тому припущенні, що досліджувана ознака підкоряється. Це твердження відоме також як Закон Гауса. Згідно з ним, нормальним називається такий розподіл усіх ймовірностей безперервної випадкової величини, який можна описати щільністю ймовірностей. Якщо припущення про нормальний розподіл виявилося помилковим, то оцінка може виявитися неправильною.
Спочатку розберемося з тим, як обчислити довірчий інтервал. Тут можливі два випадки. Дисперсія (ступінь розкиду випадкової величини) може бути відома чи ні. Якщо вона відома, то наш довірчий інтервал обчислюється за допомогою наступної формули:
хср - t*σ / (sqrt(n))<= α <= хср + t*σ / (sqrt(n)), где
α - ознака,
t - параметр таблиці розподілу Лапласа,
σ – квадратний корінь дисперсії.
Якщо дисперсія невідома, її можна розрахувати, якщо нам відомі всі значення шуканої ознаки. Для цього використовується така формула:
σ2 = х2ср - (хср)2 де
х2ср - середнє значення квадратів досліджуваної ознаки,
(ХСР)2 - квадрат даної ознаки.
Формула, за якою в цьому випадку розраховується довірчий інтервал, трохи змінюється:
хср - t * s / (sqrt (n))<= α <= хср + t*s / (sqrt(n)), где
хср - вибіркове середнє,
α - ознака,
t - параметр, який знаходять за допомогою таблиці розподілу Стьюдента t = t(?;n-1),
sqrt(n) - квадратний корінь загального обсягу вибірки,
s – квадратний корінь дисперсії.
Розглянь такий приклад. Припустимо, що за результатами 7 вимірів було визначено досліджуваного ознаки, що дорівнює 30 і дисперсія вибірки, що дорівнює 36. Потрібно знайти з ймовірністю 99% довірчий інтервал, який містить справжнє значення параметра, що вимірюється.
Спочатку визначимо чому t: t = t (0,99; 7-1) = 3.71. Використовуємо наведену вище формулу, отримуємо:
хср - t * s / (sqrt (n))<= α <= хср + t*s / (sqrt(n))
30 - 3.71*36 / (sqrt(7))<= α <= 30 + 3.71*36 / (sqrt(7))
21.587 <= α <= 38.413
Довірчий інтервал дисперсії розраховується як у випадку з відомим середнім, так і тоді, коли немає жодних даних про математичне очікування, а відомо лише значення точкової незміщеної оцінки дисперсії. Ми не наводитимемо тут формули його розрахунку, оскільки вони досить складні і за бажання їх завжди можна знайти в мережі.
Відзначимо лише, що довірчий інтервал зручно визначати за допомогою програми Excel або мережевого сервісу, що так і називається.
Ціль– навчити студентів алгоритмів обчислення довірчих інтервалів статистичних параметрів.
При статистичній обробці даних обчислені середня арифметична, коефіцієнт варіації, коефіцієнт кореляції, критерії відмінності та інші точкові статистики повинні отримати кількісні межі довіри, які позначають можливі коливання показника меншу і більшу сторону в межах довірчого інтервалу.
Приклад 3.1
.
Розподіл кальцію у сироватці крові мавп, як було встановлено раніше, характеризується такими вибірковими показниками: = 11,94 мг%;  = 0,127 мг%; n= 100. Потрібно визначити довірчий інтервал для генеральної середньої (
= 0,127 мг%; n= 100. Потрібно визначити довірчий інтервал для генеральної середньої (  ) при довірчій ймовірності P
= 0,95.
) при довірчій ймовірності P
= 0,95.
Генеральна середня знаходиться з певною ймовірністю в інтервалі:
 , де
, де 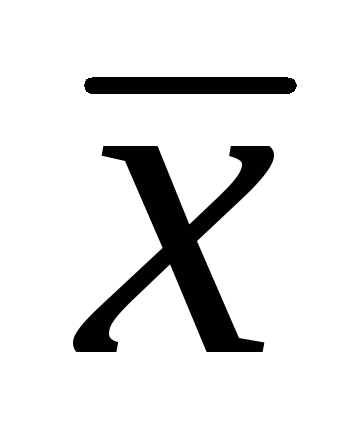 - Вибіркова середня арифметична; t– критерій Стьюдента;
- Вибіркова середня арифметична; t– критерій Стьюдента;  - Помилка середньої арифметичної.
- Помилка середньої арифметичної.
За таблицею «Значення критерію Стьюдента» знаходимо значення
 при довірчій ймовірності 0,95 та числі ступенів свободи k= 100-1 = 99. Воно дорівнює 1,982. Разом зі значеннями середньої арифметичної та статистичної помилки підставляємо його у формулу:
при довірчій ймовірності 0,95 та числі ступенів свободи k= 100-1 = 99. Воно дорівнює 1,982. Разом зі значеннями середньої арифметичної та статистичної помилки підставляємо його у формулу:
або 11,69  12,19
12,19
Таким чином, з ймовірністю 95%, можна стверджувати, що генеральна середня цього нормального розподілу знаходиться між 11,69 і 12,19 мг%.
Приклад 3.2
. Визначте межі 95% довірчого інтервалу для генеральної дисперсії (  ) розподілу кальцію в крові мавп, якщо відомо, що
) розподілу кальцію в крові мавп, якщо відомо, що  = 1,60, при n
= 100.
= 1,60, при n
= 100.
Для вирішення задачі можна скористатися такою формулою:
Де  - Статистична помилка дисперсії.
- Статистична помилка дисперсії.
Знаходимо помилку вибіркової дисперсії за формулою:  . Вона дорівнює 0,11. Значення t- критерію при довірчій ймовірності 0,95 та числі ступенів свободи k= 100-1 = 99 відомо з попереднього прикладу.
. Вона дорівнює 0,11. Значення t- критерію при довірчій ймовірності 0,95 та числі ступенів свободи k= 100-1 = 99 відомо з попереднього прикладу.
Скористаємося формулою та отримаємо:
або 1,38  1,82
1,82
Більш точно довірчий інтервал генеральної дисперсії можна побудувати із застосуванням  (хі-квадрат) – критерію Пірсона. Критичні точки при цьому критерію наводяться у спеціальній таблиці. При використанні критерію
(хі-квадрат) – критерію Пірсона. Критичні точки при цьому критерію наводяться у спеціальній таблиці. При використанні критерію  для побудови довірчого інтервалу застосовують двосторонній рівень значущості. Для нижньої межі рівень значущості розраховується за формулою
для побудови довірчого інтервалу застосовують двосторонній рівень значущості. Для нижньої межі рівень значущості розраховується за формулою  , для верхньої –
, для верхньої –  . Наприклад, для довірчого рівня
. Наприклад, для довірчого рівня  =
0,99
=
0,99 = 0,010,
= 0,010, = 0,990. Відповідно до таблиці розподілу критичних значень
= 0,990. Відповідно до таблиці розподілу критичних значень  , при розрахованих довірчих рівнях та числі ступенів свободи k= 100 - 1 = 99, знайдемо значення
, при розрахованих довірчих рівнях та числі ступенів свободи k= 100 - 1 = 99, знайдемо значення  і
і  . Отримуємо
. Отримуємо  одно 135,80, а
одно 135,80, а 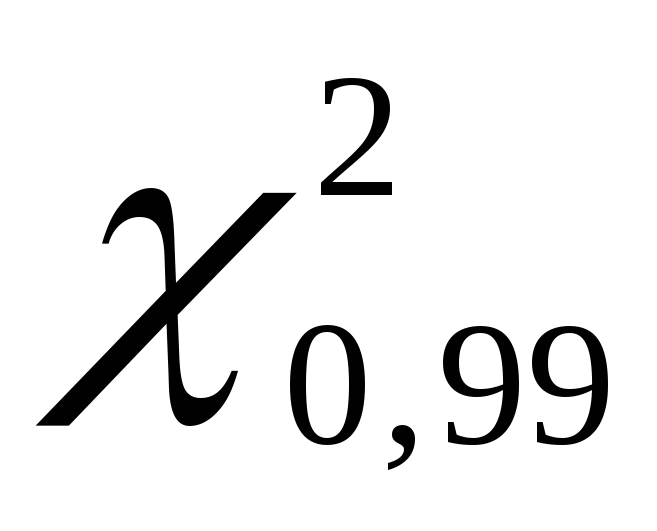 рівно70,06.
рівно70,06.
Щоб знайти довірчі межі генеральної дисперсії за допомогою  скористаємося формулами: для нижньої межі
скористаємося формулами: для нижньої межі  для верхнього кордону
для верхнього кордону  . Підставимо ці завдання знайдені значення
. Підставимо ці завдання знайдені значення  у формули:
у формули: 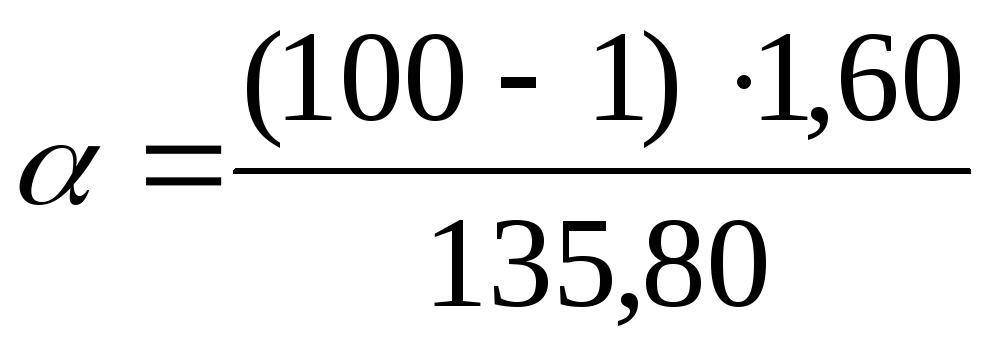 =
1,17;
=
1,17; = 2,26. Таким чином, за довірчої ймовірності P= 0,99 або 99% генеральна дисперсія лежатиме в інтервалі від 1,17 до 2,26 мг% включно.
= 2,26. Таким чином, за довірчої ймовірності P= 0,99 або 99% генеральна дисперсія лежатиме в інтервалі від 1,17 до 2,26 мг% включно.
Приклад 3.3 . Серед 1000 насіння пшениці з партії, що надійшла на елеватор, виявлено 120 насіння заражених ріжків. Необхідно визначити можливі межі генеральної частки зараженого насіння у цій партії пшениці.
Довірчі межі для генеральної частки за всіх можливих її значеннях доцільно визначати за такою формулою:
 ,
,
Де n - Число спостережень; m- Абсолютна чисельність однієї з груп; t– нормоване відхилення.
Вибіркова частка зараженого насіння дорівнює  чи 12%. За довірчої ймовірності Р= 95% нормоване відхилення ( t-критерій Стьюдента при k
=
чи 12%. За довірчої ймовірності Р= 95% нормоване відхилення ( t-критерій Стьюдента при k
=
 )t
= 1,960.
)t
= 1,960.
Підставляємо наявні дані у формулу:
Звідси межі довірчого інтервалу дорівнюють  = 0,122-0,041 = 0,081, або 8,1%;
= 0,122-0,041 = 0,081, або 8,1%;  = 0,122 + 0,041 = 0,163, чи 16,3%.
= 0,122 + 0,041 = 0,163, чи 16,3%.
Таким чином, з довірчою ймовірністю 95% можна стверджувати, що генеральна частка зараженого насіння знаходиться між 8,1 та 16,3%.
Приклад 3.4 . Коефіцієнт варіації, що характеризує варіювання кальцію (мг%) у сироватці крові мавп, дорівнював 10,6%. Обсяг вибірки n= 100. Необхідно визначити межі 95% довірчого інтервалу для генерального параметра Cv.
Кордони довірчого інтервалу для генерального коефіцієнта варіації Cv визначаються за такими формулами:
 і
і  , де K
проміжна величина, що обчислюється за формулою
, де K
проміжна величина, що обчислюється за формулою  .
.
Знаючи, що за довірчої ймовірності Р= 95% нормоване відхилення (критерій Стьюдента при k
=
 )t
= 1,960, попередньо розрахуємо величину До:
)t
= 1,960, попередньо розрахуємо величину До:
 .
.
 або 9,3%
або 9,3%
 або 12,3%
або 12,3%
Таким чином, генеральний коефіцієнт варіації з довірчою ймовірністю 95% лежить в інтервалі від 93 до 123%. При повторних вибірках коефіцієнт варіації не перевищить 12,3% і не виявиться нижчим за 9,3% у 95 випадках зі 100.
Запитання для самоконтролю:

Завдання для самостійного вирішення.
1. Середній відсоток жиру у молоці за лактацію корів холмогорських помісей був таким: 3,4; 3,6; 3,2; 3,1; 2,9; 3,7; 3,2; 3,6; 4,0; 3,4; 4,1; 3,8; 3,4; 4,0; 3,3; 3,7; 3,5; 3,6; 3,4; 3,8. Встановіть довірчі інтервали для середньої середньої при довірчій ймовірності 95% (20 балів).
2. На 400 рослинах гібридного жита перші квітки з'явилися в середньому на 70,5 день після посіву. Середнє відхилення було 6,9 дня. Визначте помилку середньої та довірчі інтервали для генеральної середньої та дисперсії при рівні значущості W= 0,05 та W= 0,01 (25 балів).
3. При вивченні довжини листя 502 екземплярів садової суниці були отримані такі дані:
 = 7,86 див; σ = 1,32 см,
= 7,86 див; σ = 1,32 см,  =± 0,06 см. Визначте довірчі інтервали для середньої арифметичної генеральної сукупності з рівнями значущості 0,01; 0,02; 0,05. (25 балів).
=± 0,06 см. Визначте довірчі інтервали для середньої арифметичної генеральної сукупності з рівнями значущості 0,01; 0,02; 0,05. (25 балів).
4. При обстеженні 150 дорослих чоловіків середній зріст дорівнював 167 см, а σ = 6 см. У яких межах знаходиться генеральна середня та генеральна дисперсія з довірчою ймовірністю 0,99 та 0,95? (25 балів).
5. Розподіл кальцію у сироватці крові мавп характеризується такими вибірковими показниками:
 = 11,94 мг%, σ
= 1,27, n
= 100. Побудуйте 95% довірчий інтервал для генеральної середньої цього розподілу. Розрахуйте коефіцієнт варіації (25 балів).
= 11,94 мг%, σ
= 1,27, n
= 100. Побудуйте 95% довірчий інтервал для генеральної середньої цього розподілу. Розрахуйте коефіцієнт варіації (25 балів).
6. Було вивчено загальний вміст азоту в плазмі крові щурів-альбіносів у віці 37 та 180 днів. Результати виражені у грамах на 100 см 3 плазми. У віці 37 днів 9 щурів мали: 0,98; 0,83; 0,99; 0,86; 0,90; 0,81; 0,94; 0,92; 0,87. У віці 180 днів 8 щурів мали: 1,20; 1,18; 1,33; 1,21; 1,20; 1,07; 1,13; 1,12. Встановіть довірчі інтервали для різниці з вірогідністю 0,95 (50 балів).
7. Визначте межі 95% довірчого інтервалу для генеральної дисперсії розподілу кальцію (мг%) у сироватці крові мавп, якщо для цього розподілу обсяг вибірки n = 100, статистична помилка вибіркової дисперсії s σ 2 = 1,60 (40 балів).
8. Визначте межі 95% довірчого інтервалу для генеральної дисперсії розподілу 40 колосків пшениці по довжині (σ 2 = 40, 87 мм 2). (25 балів).
9. Куріння вважають основним фактором, що привертає до обструктивних захворювань легень. Пасивне куріння таким фактором не вважається. Вчені засумнівалися у нешкідливості пасивного куріння та досліджували прохідність дихальних шляхів у курців, що не палять, пасивних та активних. Для характеристики стану дихальних шляхів взяли один із показників функції зовнішнього дихання – максимальну об'ємну швидкість середини видиху. Зменшення цього показника – ознака порушення прохідності дихальних шляхів. Дані обстеження наведені у таблиці.
|
Число обстежених |
Максимальна об'ємна швидкість середини видиху, л/с |
||
|
Стандартне відхилення |
|||
|
Некурці |
|||
|
працюють у приміщенні, де не курять | |||
|
працюють у накуреному приміщенні | |||
|
Курці |
|||
|
викурюють невелику кількість сигарет | |||
|
викурюють середню кількість сигарет | |||
|
викурюють велику кількість сигарет | |||
За даними таблиці знайдіть 95% довірчі інтервали для генеральної середньої та генеральної дисперсії для кожної групи. У чому різниця між групами? Результати подайте графічно (25 балів).
10. Визначте межі 95%-ного та 99%-ного довірчого інтервалу для генеральної дисперсії чисельності поросят у 64 опоросах, якщо статистична помилка вибіркової дисперсії s σ 2 = 8, 25 (30 балів).
11. Відомо, що середня маса кролів становить 2,1 кг. Визначте межі 95%-ного та 99%-ного довірчого інтервалу для генеральної середньої та дисперсії при n= 30, σ = 0,56 кг (25 балів).
12. У 100 колосків вимірювали озерненість колосу ( Х), довжину колосу ( Y) та масу зерна в колосі ( Z). Знайти довірчі інтервали для генеральної середньої та дисперсії при P 1
= 0,95, P 2
= 0,99, P 3
= 0,999, якщо
 = 19, = 6,766 см, = 0,554 м; x 2 = 29, 153, y 2 = 2, 111, z 2 = 0,064. (25 балів).
= 19, = 6,766 см, = 0,554 м; x 2 = 29, 153, y 2 = 2, 111, z 2 = 0,064. (25 балів).
13. У відібраних випадковим чином 100 колосках пшениці озимої підраховувалося число колосків. Вибіркова сукупність характеризувалася такими показниками:
 = 15 колосків та σ = 2,28 шт. Визначте, з якою точністю отримано середній результат (
= 15 колосків та σ = 2,28 шт. Визначте, з якою точністю отримано середній результат (  ) та побудуйте довірчий інтервал для генеральної середньої та дисперсії при 95% та 99% рівнях значущості (30 балів).
) та побудуйте довірчий інтервал для генеральної середньої та дисперсії при 95% та 99% рівнях значущості (30 балів).
14. Число ребер на раковинах викопного молюска Orthambonites calligramma:
Відомо що n = 19, σ = 4,25. Визначте межі довірчого інтервалу для генеральної середньої та генеральної дисперсії при рівні значущості W = 0,01 (25 балів).
15. Для визначення надої молока на молочно-товарній фермі щодня визначалася продуктивність 15 корів. За даними протягом року кожна корова давала загалом на добу таку кількість молока (л): 22; 19; 25; 20; 27; 17; 30; 21; 18; 24; 26; 23; 25; 20; 24. Побудуйте довірчі інтервали для генеральної дисперсії та середньої арифметичної. Чи можна очікувати, що середньорічний надій на кожну корову складе 10000 літрів? (50 балів).
16. З метою визначення врожаю пшениці в середньому по агрогосподарству були проведені укоси на пробних ділянках площею 1, 3, 2, 5, 2, 6, 1, 3, 2, 11 та 2 га. Урожайність (ц/га) з ділянок становила 39,4; 38; 35,8; 40; 35; 42,7; 39,3; 41,6; 33; 42; 29 відповідно. Побудуйте довірчі інтервали для генеральних дисперсії та середньої арифметичної. Чи можна очікувати, що в середньому в агрогосподарстві врожай складе 42 ц/га? (50 балів).
та інших. Усі є оцінками своїх теоретичних аналогів, які можна було б отримати, якби у розпорядженні була вибірка, а генеральна сукупність. Але на жаль, генеральна сукупність - це дуже дорого і часто недоступне.
Поняття про інтервальне оцінювання
Будь-яка вибіркова оцінка має деякий розкид, т.к. є випадковою величиною, що залежить від значень у конкретній вибірці. Отже, для надійніших статистичних висновків слід знати не лише точкову оцінку, а й інтервал, який з високою ймовірністю γ (гама) накриває оцінюваний показник θ (Тета).
Формально це два таких значення (статистики) T 1 (X)і T 2 (X), що T 1< T 2 для яких при заданому рівні ймовірності γ виконується умова:
Коротше, з ймовірністю γ або більше істинний показник знаходиться між точками T 1 (X)і T 2 (X), які називаються нижнім та верхнім кордоном довірчого інтервалу.
Однією з умов побудови довірчих інтервалів його максимальна вузькість, тобто. він має бути наскільки це можливо коротким. Бажання цілком природно, т.к. дослідник намагається точніше локалізувати знаходження шуканого параметра.
Звідси випливає, що інтервал довіри повинен накривати максимальні ймовірності розподілу. а сама оцінка бути у центрі.
![]()
Тобто ймовірність відхилення (справжнього показника від оцінки) у більшу сторону дорівнює ймовірності відхилення у менший бік. Слід зазначити, що з несиметричних розподілів інтервал справа не дорівнює інтервалу зліва.
На малюнку вище чітко видно, що чим більша довірча ймовірність, тим ширший інтервал – пряма залежність.
Це була невелика вступна частина в теорію інтервального оцінювання невідомих параметрів. Перейдемо до знаходження довірчих кордонів для математичного очікування.
Довірчий інтервал для математичного очікування
Якщо вихідні дані розподілені по , то середнє буде нормальною величиною. Це випливає з того правила, що лінійна комбінація нормальних величин також має нормальний розподіл. Отже, для розрахунку можливостей ми могли б використовувати математичний апарат нормального закону розподілу.
Однак для цього потрібно знати два параметри – матожидання та дисперсію, які зазвичай не відомі. Можна, звичайно, замість параметрів використовувати оцінки (середню арифметичну і ), але тоді розподіл середньої буде не зовсім нормальним, він буде трохи приплюснутий донизу. Цей факт спритно помітив громадянин Вільям Госсет з Ірландії, опублікувавши своє відкриття у березневому випуску журналу Biometrica за 1908 рік. З метою конспірації Держсет підписався Стьюдентом. Так виник t-розподіл Стьюдента.
Однак нормальний розподіл даних, що використовувався К. Гауссом при аналізі помилок астрономічних спостережень, у земному житті зустрічається вкрай рідко і встановити досить складно (для високої точності необхідно близько 2 тисяч спостережень). Тому припущення про нормальність найкраще відкинути та використовувати методи, які не залежать від розподілу вихідних даних.
Виникає питання: який же розподіл середньої арифметичної, якщо він розрахований за даними невідомого розподілу? Відповідь дає відома у теорії ймовірностей Центральна гранична теорема(ЦПТ). У математиці існує кілька її варіантів (протягом довгих років формулювання уточнювалися), але всі вони, грубо кажучи, зводяться до твердження, що сума великої кількості випадкових незалежних величин підпорядковується нормальному закону розподілу.
При розрахунку середньої арифметичної використовується сума випадкових величин. Звідси виходить, що середнє арифметичне має нормальний розподіл, у якого матожидання – це маточування вихідних даних, а дисперсія – .
Розумні люди вміють доводити ЦПТ, але ми переконаємося в цьому за допомогою експерименту, проведеного в Excel. Змоделюємо вибірку з 50-ти рівномірно розподілених випадкових величин (за допомогою функції Excel ПРОМІНЬ). Потім зробимо 1000 таких вибірок і кожної розрахуємо середню арифметичну. Подивимося з їхньої розподіл.

Видно, що розподіл середньої близько до нормального закону. Якщо обсяг вибірок та їх кількість зробити ще більше, то подібність буде ще кращою.
Тепер, коли ми переконалися в справедливості ЦПТ, можна, використовуючи , розрахувати довірчі інтервали для середньої арифметичної, які із заданою ймовірністю накривають справжнє середнє чи математичне очікування.
Для встановлення верхньої та нижньої межі потрібно знати параметри нормального розподілу. Як правило, їх немає, тому використовують оцінки: середню арифметичнуі вибіркову дисперсію. Повторюся, такий спосіб дає гарне наближення лише за великих вибірках. Коли вибірки малі, часто рекомендують використовувати розподіл Стьюдента. Не вірте! Розподіл Стьюдента для середньої буває лише тоді, коли вихідні дані мають нормальний розподіл, тобто майже ніколи. Тому краще відразу поставити мінімальну планку за кількістю необхідних даних та використовувати асимптотично коректні методи. Говорять, достатньо 30 спостережень. Беріть 50 – не помилитеся.
![]()
T 1,2– нижня та верхня межа довірчого інтервалу
– вибіркове середнє арифметичне
s 0- Середнє квадратичне відхилення за вибіркою (незміщене)
n - Розмір вибірки
γ - Довірча ймовірність (зазвичай дорівнює 0,9, 0,95 або 0,99)
c γ =Φ -1 ((1+γ)/2)- Зворотне значення функції стандартного нормального розподілу. Простіше кажучи, це кількість стандартних помилок від середньої арифметичної до нижньої або верхньої межі (вказаним трьома ймовірностями відповідають значення 1,64, 1,96 і 2,58).
Суть формули в тому, що береться середнє арифметичне і далі від неї відкладається кілька ( з γ) стандартних помилок ( s 0 /√n). Все відомо, бери і рахуй.
До масового використання ПЕОМ для отримання значень функції нормального розподілу та зворотної їй використовували. Їх і зараз використовують, але ефективніше звернутися до готових формул Excel. Всі елементи формули вище ( , і ) можна легко розрахувати в Excel. Але є і готова формула для розрахунку довірчого інтервалу ДОВІР.НОРМ. Її синтаксис наступний.
ДОВІР.НОРМ(альфа;стандартне_вимк.;розмір)
альфа– рівень значущості чи довірчий рівень, що у прийнятих вище позначеннях дорівнює 1- γ, тобто. ймовірність того, що математичнеочікування опиниться поза довірчого інтервалу. За довірчої ймовірності 0,95, альфа дорівнює 0,05 і т.д.
стандартне_відкл- Середнє квадратичне відхилення вибіркових даних. Стандартну помилку не треба розраховувати, Excel сам розділить на корінь з n.
розмір- Розмір вибірки (n).
Результат функції ДОВЕРИТ.НОРМ – це другий доданок з формули розрахунку довірчого інтервалу, тобто. напівінтервал. Відповідно, нижня та верхня точка – це середнє ± отримане значення.
Отже, можна побудувати універсальний алгоритм розрахунку довірчих інтервалів для середньої арифметичної, який залежить від розподілу вихідних даних. Платою за універсальність є його асимптотичність, тобто. необхідність використання щодо великих вибірок. Однак у століття сучасних технологій зібрати потрібну кількість даних зазвичай не становить труднощів.
Перевірка статистичних гіпотез за допомогою довірчого інтервалу
(Module 111)
Однією з основних завдань, вирішуваних у статистиці, є . Її суть коротко така. Висувається припущення, наприклад, що матожидання генеральної сукупності дорівнює якомусь значенню. Потім будується розподіл вибіркових середніх, які можуть спостерігатися при даному матожиданні. Далі дивляться, де цього умовного розподілу перебуває справжня середня. Якщо вона виходить за допустимі межі, то поява такого середнього дуже малоймовірна, а при одноразовому повторенні експерименту майже неможливо, що суперечить висунутій гіпотезі, яка успішно відхиляється. Якщо ж середнє не виходить за критичний рівень, то гіпотеза не відхиляється (але й доводиться!).
Так ось за допомогою довірчих інтервалів, у нашому випадку для матожидання, також можна перевіряти деякі гіпотези. Це дуже просто зробити. Припустимо, середня арифметична за деякою вибіркою дорівнює 100. Перевіряється гіпотеза про те, що матожидання одно, припустимо, 90. Тобто, якщо поставити питання примітивно, то він звучить так: чи може таке бути, щоб при істинному значенні середньої рівної 90, спостерігається середня виявилася дорівнює 100?
Для відповіді на це питання додатково знадобиться інформація про середнє квадратичне відхилення та розмір вибірки. Допустимо середньоквадратичне відхилення дорівнює 30, а кількість спостережень 64 (щоб легко витягти корінь). Тоді стандартна помилка середньої дорівнює 30/8 чи 3,75. Для розрахунку 95% довірчого інтервалу потрібно відкласти в обидві сторони від середньої по дві стандартні помилки (точніше, 1,96). Довірчий інтервал вийде приблизно 100±7,5 або 92,5 до 107,5.
Далі міркування такі. Якщо перевірене значення потрапляє у довірчий інтервал, воно не суперечить гіпотезі, т.к. укладається у межі випадкових коливань (з ймовірністю 95%). Якщо точка, що перевіряється, виходить за межі довірчого інтервалу, то ймовірність такої події дуже маленька, принаймні нижче допустимого рівня. Отже, гіпотезу відхиляють, як таку, що суперечить спостережуваним даним. У нашому випадку гіпотеза про маточування знаходиться за межами довірчого інтервалу (перевірене значення 90 не входить до інтервалу 100±7,5), тому її слід відхилити. Відповідаючи на примітивне питання вище, слід сказати: ні не може, принаймні таке трапляється вкрай рідко. Часто при цьому вказують конкретну ймовірність помилкового відхилення гіпотези (p-level), а не заданий рівень, яким будувався довірчий інтервал, але про це в інший раз.
Як бачимо, побудувати довірчий інтервал для середнього (або математичного очікування) нескладно. Головне, вловити суть, а далі йтиметься. На практиці в більшості випадків використовуються 95% довірчий інтервал, який має завширшки приблизно дві стандартні помилки по обидва боки від середньої.
На цьому поки що все. Всіх благ!
Часто оцінювачу доводиться аналізувати ринок нерухомості того сегмента, в якому знаходиться об'єкт оцінки. Якщо ринок розвинений, проаналізувати всю сукупність представлених об'єктів буває складно, для аналізу використовується вибірка об'єктів. Не завжди ця вибірка виходить однорідною, іноді потрібно очистити її від екстремумів - надто високих чи надто низьких пропозицій ринку. Для цієї мети застосовується довірчий інтервал. Мета даного дослідження - провести порівняльний аналіз двох способів розрахунку довірчого інтервалу та вибрати оптимальний варіант розрахунку під час роботи з різними вибірками у системі estimatica.pro.
Довірчий інтервал - обчислений з урахуванням вибірки інтервал значень ознаки, що з певною ймовірністю містить оцінюваний параметр генеральної сукупності.
Сенс обчислення довірчого інтервалу полягає в побудові за даними вибірки такого інтервалу, щоб можна було стверджувати із заданою ймовірністю, що значення параметра, що оцінюється, знаходиться в цьому інтервалі. Іншими словами, довірчий інтервал з певною ймовірністю містить невідоме значення величини, що оцінюється. Чим ширший інтервал, тим вища неточність.
Існують різні способи визначення довірчого інтервалу. У цій статті розглянемо 2 способи:
- через медіану та середньоквадратичне відхилення;
- через критичне значення t-статистики (коефіцієнт Стьюдента).
Етапи порівняльного аналізу різних способів розрахунку ДІ:
1. формуємо вибірку даних;
2. обробляємо її статистичними методами: розраховуємо середнє значення, медіану, дисперсію тощо;
3. розраховуємо довірчий інтервал двома способами;
4. аналізуємо очищені вибірки та отримані довірчі інтервали.
Етап 1. Вибірка даних
Вибірку сформовано за допомогою системи estimatica.pro. У вибірку увійшла 91 пропозиція про продаж 1 кімнатних квартир у 3-му ціновому поясі з типом планування «Хрущовка».
Таблиця 1. Вихідна вибірка
|
Ціна 1 кв.м., д.е. |
|
Рис.1. Вихідна вибірка

Етап 2. Обробка вихідної вибірки
Обробка вибірки методами статистики потребує обчислення наступних значень:
1. Середнє арифметичне значення

2. Медіана - число, що характеризує вибірку: рівно половина елементів вибірки більше медіани, інша половина менше медіани
 (Для вибірки, що має непарне число значень)
(Для вибірки, що має непарне число значень)
3. Розмах - різниця між максимальним та мінімальним значеннями у вибірці

4. Дисперсія – використовується для більш точного оцінювання варіації даних

5. Середньоквадратичне відхилення за вибіркою (далі - СКО) - найпоширеніший показник розсіювання значень коригування навколо середнього арифметичного значення.

6. Коефіцієнт варіації - відбиває ступінь розкиданості значень коригувань

7. коефіцієнт осциляції - відбиває відносне коливання крайніх значень цін у вибірці навколо середньої

Таблиця 2. Статистичні показники вихідної вибірки
Коефіцієнт варіації, що характеризує однорідність даних, становить 12,29%, проте коефіцієнт осциляції занадто великий. Таким чином ми можемо стверджувати, що вихідна вибірка не є однорідною, тому перейдемо до розрахунку довірчого інтервалу.
Етап 3. Розрахунок довірчого інтервалу
Спосіб 1. Розрахунок через медіану та середньоквадратичне відхилення.
Довірчий інтервал визначається так: мінімальне значення - з медіани віднімається СКО; максимальне значення - до медіани додається СКО.

Таким чином, довірчий інтервал (47179 д.е.; 60689 д.е.)
Мал. 2. Значення, що потрапили в інтервал довіри 1.

Спосіб 2. Побудова довірчого інтервалу через критичне значення t-статистики (коефіцієнт Стьюдента)
С.В. Грибовський у книзі «Математичні методи оцінки вартості майна» визначає спосіб обчислення довірчого інтервалу через коефіцієнт Стьюдента. При розрахунку цим методом оцінювач повинен сам задати рівень значущості ∝, що визначає ймовірність, з якою буде побудовано довірчий інтервал. Зазвичай використовуються рівні значення 0,1; 0,05 та 0,01. Їм відповідають довірчі ймовірності 0,9; 0,95 та 0,99. При такому методі вважають справжні значення математичного очікування та дисперсії практично невідомими (що майже завжди є вірним при вирішенні практичних завдань оцінки).
Формула довірчого інтервалу:

n – обсяг вибірки;
Критичне значення t-статистики (розподілу Стьюдента) з рівнем значимості ∝, числом ступенів свободи n-1, яке визначається за спеціальними статистичними таблицями або за допомогою MS Excel (→ "Статистичні" → СТЬЮДРАСПОБР);
∝ – рівень значущості, приймаємо ∝=0,01.

Мал. 2. Значення, що потрапили в інтервал довіри 2.

Етап 4. Аналіз різних способів розрахунку довірчого інтервалу
Два способи розрахунку довірчого інтервалу – через медіану та коефіцієнт Стьюдента – привели до різних значень інтервалів. Відповідно, вийшло дві різні очищені вибірки.
Таблиця 3. Статистичні показники за трьома вибірками.
|
Показник |
Вихідна вибірка |
1 варіант |
2 варіант |
|
Середнє значення |
|||
|
Дисперсія |
|||
|
Коеф. варіації |
|||
|
Коеф. осциляції |
|||
|
Кількість об'єктів, що вибули, шт. |
|||
З виконаних розрахунків можна сказати, що отримані різними методами значення довірчих інтервалів перетинаються, тому можна використовувати будь-який із способів розрахунку розсуд оцінювача.
Однак ми вважаємо, що при роботі в системі estimatica.pro доцільно вибирати метод розрахунку довірчого інтервалу в залежності від рівня розвиненості ринку:
- якщо ринок нерозвинений, застосовувати метод розрахунку через медіану і середньоквадратичне відхилення, оскільки кількість об'єктів, що вибули, у цьому випадку невелика;
- якщо ринок розвинений, застосовувати розрахунок через критичне значення t-статистики (коефіцієнт Стьюдента), оскільки є можливість сформувати велику вихідну вибірку.
Під час підготовки статті було використано:
1. Грибовський С.В., Сівець С.А., Левикіна І.А. Математичні методи оцінки вартості майна. Москва, 2014 р.
2. Дані системи estimatica.pro
Побудуємо в MS EXCEL довірчий інтервал з метою оцінки середнього значення розподілу у разі відомого значення дисперсії.
Зрозуміло, вибір рівня довіриповністю залежить від розв'язуваного завдання. Так, ступінь довіри авіапасажира до надійності літака, безсумнівно, має бути вищим за ступінь довіри покупця до надійності електричної лампочки.
Формулювання завдання
Припустимо, що з генеральної сукупностімає взята вибіркарозміру n. Передбачається, що стандартне відхиленняцього розподілу відомо. Необхідно на підставі цієї вибіркиоцінити невідоме середнє значення розподілу(μ, ) та побудувати відповідний двосторонній довірчий інтервал.
Точкова оцінка
Як відомо з , статистика(позначимо її Х ср) є незміщеною оцінкою середньогоцією генеральної сукупностіта має розподіл N(μ;σ 2 /n).
Примітка: Що робити, якщо потрібно збудувати довірчий інтервалу разі розподілу, який не є нормальним?У цьому випадку на допомогу приходить , яка говорить, що за досить великого розміру вибірки n із розподілу що не є нормальним, вибірковий розподіл статистики Х порбуде приблизновідповідати нормальному розподілуіз параметрами N(μ;σ 2 /n).
Отже, точкова оцінка середнього значення розподілуу нас є – це середнє значення вибірки, тобто. Х ср. Тепер займемося довірчим інтервалом.
Побудова довірчого інтервалу
Зазвичай, знаючи розподіл та його параметри, ми можемо обчислити ймовірність того, що випадкова величина набуде значення заданого нами інтервалу. Зараз зробимо навпаки: знайдемо інтервал, у який випадкова величина потрапить із заданою ймовірністю. Наприклад, із властивостей нормального розподілувідомо, що з ймовірністю 95%, випадкова величина, розподілена по нормальному закону, потрапить в інтервал приблизно +/- 2 від середнього значення(Див. статтю про ). Цей інтервал, послужить нам прототипом для довірчого інтервалу.
Тепер розберемося, чи ми знаємо розподіл , щоб визначити цей інтервал? Для відповіді на запитання ми маємо вказати форму розподілу та його параметри.
Форму розподілу ми знаємо – це нормальний розподіл(нагадаємо, що йдеться про вибірковому розподілі статистики Х ср).
Параметр μ нам невідомий (його якраз потрібно оцінити за допомогою довірчого інтервалу), але у нас є його оцінка Х пор,обчислена на основі вибірки,яку можна використати.
Другий параметр – стандартне відхилення вибіркового середнього будемо вважати відомим, Він дорівнює σ/√n.
Т.к. ми не знаємо μ, то будуватимемо інтервал +/- 2 стандартних відхиленьне від середнього значення, а від відомої його оцінки Х ср. Тобто. при розрахунку довірчого інтервалуми не будемо вважати, що Х српотрапить в інтервал +/- 2 стандартних відхиленьвід μ з ймовірністю 95%, а вважатимемо, що інтервал +/- 2 стандартних відхиленьвід Х срз ймовірністю 95% накриє μ - Середня генеральна сукупність,з якого взято вибірка. Ці два твердження еквівалентні, але друге твердження нам дозволяє побудувати довірчий інтервал.
Крім того, уточнимо інтервал: випадкова величина, розподілена по нормальному закону, з ймовірністю 95% потрапляє в інтервал +/- 1,960 стандартних відхилень,а не+/- 2 стандартних відхилень. Це можна розрахувати за допомогою формули =НОРМ.СТ.ОБР((1+0,95)/2), Див. файл прикладу Лист Інтервал.

Тепер ми можемо сформулювати ймовірнісне твердження, яке послужить нам для формування довірчого інтервалу:
«Ймовірність того, що середня генеральна сукупністьзнаходиться від середньої вибіркив межах 1,960 « стандартних відхилень вибіркового середнього», Дорівнює 95% ».
Значення ймовірності, згадане у твердженні, має спеціальну назву , який пов'язаний зрівнем значимості α (альфа) простим виразом рівень довіри =1 -α . У нашому випадку рівень значущості α =1-0,95=0,05 .
Тепер на основі цього ймовірнісного твердження запишемо вираз для обчислення довірчого інтервалу:

де Z α/2 – стандартного нормального розподілу(Таке значення випадкової величини z, що P(z>=Z α/2 )=α/2).
Примітка: Верхній α/2-квантильвизначає ширину довірчого інтервалув стандартних відхиленнях вибіркового середнього. Верхній α/2-квантиль стандартного нормального розподілузавжди більше 0, що дуже зручно.
У нашому випадку при α=0,05, верхній α/2-квантиль дорівнює 1,960. Для інших рівнів значення α (10%; 1%) верхній α/2-квантиль Z α/2 можна обчислити за допомогою формули =НОРМ.СТ.ОБР(1-α/2) або, якщо відомий рівень довіри, =НОРМ.СТ.ОБР((1+ур.довіри)/2).
Зазвичай при побудові довірчих інтервалів для оцінки середньоговикористовують тільки верхній α/2-квантильі не використовують нижній α/2-квантиль. Це можливо тому, що стандартне нормальний розподілсиметрично щодо осі х ( щільність його розподілусиметрична щодо середнього, тобто. 0). Тому немає потреби обчислювати нижній α/2-квантиль(його називають просто α /2-квантиль), т.к. він дорівнює верхньому α/2-квантилюзі знаком мінус.
Нагадаємо, що, незважаючи на форму розподілу величини х, відповідна випадкова величина Х сррозподілено приблизно нормально N(μ;σ 2 /n) (див. статтю про ). Отже, у загальному випадку, вищезгадане вираз для довірчого інтервалує лише наближеним. Якщо величина х розподілена по нормальному закону N(μ;σ 2 /n), то вираз для довірчого інтервалує точним.
Розрахунок довірчого інтервалу в MS EXCEL
Розв'яжемо завдання.
Час відгуку електронного компонента на вхідний сигнал є важливою характеристикою пристрою. Інженер хоче побудувати довірчий інтервал для середнього відгуку при рівні довіри 95%. З попереднього досвіду інженер знає, що стандартне відхилення часу відгуку складає 8 мсек. Відомо, що з оцінки часу відгуку інженер зробив 25 вимірів, середнє значення становило 78 мсек.
Рішення: Інженер хоче знати час відгуку електронного пристрою, але він розуміє, що час відгуку є не фіксованою, а випадковою величиною, яка має свій розподіл. Отже, найкраще, на що він може розраховувати, це визначити параметри та форму цього розподілу.
На жаль, з умови завдання форма розподілу часу відгуку нам не відома (вона не обов'язково має бути нормальним). , цього розподілу також невідомо. Відомо лише його стандартне відхиленняσ=8. Тому, поки ми не можемо порахувати ймовірності та побудувати довірчий інтервал.
Однак, незважаючи на те, що ми не знаємо розподілу часу окремого відгуку, ми знаємо, що згідно ЦПТ, вибірковий розподіл середнього часу відгукує приблизно нормальним(вважатимемо, що умови ЦПТвиконуються, т.к. розмір вибіркидосить великий (n=25)) .
Більш того, середняцього розподілу дорівнює середнього значеннярозподілу одиничного відгуку, тобто. μ. А стандартне відхиленняцього розподілу (σ/√n) можна обчислити за формулою =8/КОРІНЬ(25) .
Також відомо, що інженером було отримано точкова оцінкапараметра μ дорівнює 78 мсек (Х пор). Тому, ми можемо обчислювати ймовірності, т.к. нам відома форма розподілу ( нормальне) та його параметри (Х ср і σ/√n).
Інженер хоче знати математичне очікуванняμ розподілу часу відгуку. Як було сказано вище, це μ дорівнює математичному очікуванню вибіркового розподілу середнього часу відгуку. Якщо ми скористаємося нормальним розподілом N(Х ср; σ/√n), то шукане μ перебуватиме в інтервалі +/-2*σ/√n з ймовірністю приблизно 95%.
Рівень значущостідорівнює 1-0,95 = 0,05.
Нарешті, знайдемо лівий та правий кордон довірчого інтервалу.
Ліва межа: =78-НОРМ.СТ.ОБР(1-0,05/2)*8/КОРІНЬ(25) =
74,864
Права межа: =78+НОРМ.СТ.ОБР(1-0,05/2)*8/КОРІНЬ(25)=81,136
Ліва межа: =НОРМ.ОБР(0,05/2; 78; 8/КОРІНЬ(25))
Права межа: =НОРМ.ОБР(1-0,05/2; 78; 8/КОРІНЬ(25))
Відповідь: довірчий інтервалпри рівні довіри 95% та σ=8мсекдорівнює 78+/-3,136 мсек.
У файл прикладу на аркуші Сигмавідома створена форма для розрахунку та побудови двостороннього довірчого інтервалудля довільних вибірокіз заданим σ та рівнем значимості.

Функція ДОВЕРИТ.НОРМ()
Якщо значення вибіркизнаходяться в діапазоні B20: B79
, а рівень значущостідорівнює 0,05; то формула MS EXCEL:
=СРЗНАЧ(B20:B79)-ДОВЕРИТ.НОРМ(0,05;σ; РАХУНОК(B20:B79))
поверне лівий кордон довірчого інтервалу.
Цей же кордон можна обчислити за допомогою формули:
=СРЗНАЧ(B20:B79)-НОРМ.СТ.ОБР(1-0,05/2)*σ/КОРІНЬ(РАХУНОК(B20:B79))
Примітка: Функція ДОВЕРИТ.НОРМ() з'явилася в MS EXCEL 2010. У попередніх версіях MS EXCEL використовувалася функція ДОВЕРИТ() .


