Oracle case when опис. Умовні вирази CASE
Дерево — одна з структур даних, що найчастіше використовуються у веб-розробці. Кожен веб-розробник, який писав HTML-код і завантажував його в браузер, створював дерево, яке називають об'єктною моделлю документа (DOM).
Наприклад, стаття, яку ви читаєте зараз, відображається у браузері у вигляді дерева. Абзаци представлені у вигляді елементів
; елементи
Вкладені в елемент
; а вкладено в елемент .Вкладення даних схоже на генеалогічне дерево. Елемент є батьківським,
є дочірнім від нього, а елемент<р>є дочірнім від елемента .У цій статті ми використовуємо два різні методи проходження дерева: пошук у глибину ( DFS) та пошук завширшки ( BFS). Обидва ці типи проходження мають на увазі різні способи взаємодії з деревом і включають використання структур даних, які ми розглянули в цій серії статей. DFS використовує стек, а BFS використовує чергу.
Дерево (пошук у глибину та пошук у ширину)
В інформатиці дерево є структурою, яка задає ієрархічні дані з вузлами. Кожен вузол дерева містить власні дані та вказівники на інші вузли.
Порівняємо дерево зі структурою організації. Ця структура має посаду верхнього рівня (кореневий вузол), наприклад, генерального директора. Нижче на цій посаді розташовуються інші посади, такі як віце-президент ( VP).
Для представлення їхньої підпорядкованості ми використовуємо стрілки, які вказують від генерального директора на віце-президента. Такі посади як генеральний директор є вузлами; зв'язки, які ми позначили від генерального директора до віце-президента, є вказівниками. Для створення інших зв'язків у нашій структурі організації ми повторюємо цей процес – додаємо покажчики інші вузли.
Давайте розглянемо DOM. DOM містить елемент який є елементом верхнього рівня (кореневий вузол). Цей вузол вказує на елементи
і . Цей процес повторюється всім вузлів в DOM .Однією з переваг цієї конструкції є можливість вкладати вузли: елемент
- наприклад, може містити безліч елементів
- , вкладених у нього; крім того, кожен елемент
- може мати вузли
- того ж рівня.
Операції дерева
Будь-яке дерево містить вузли, які можуть бути окремими конструкторами дерева, і ми визначимо операції для обох конструкторів: Node та Tree.
Node
- data - тут зберігаються значення;
- parent - вказує на батьківський елемент вузла;
- children - Вказує на наступний вузол у списку.
Tree
- _root - Вказує на кореневий вузол дерева;
- traverseDF(callback)- Проходить вузли дерева за допомогою методу DFS;
- traverseBF(callback) - проходить вузли дерева за допомогою методу BFS;
- contains(data, traversal) - шукає вузол дерева;
- add(data, toData, traverse) - додає вузол до дерева;
- remove (child, parent) – видаляє вузол дерева.
Реалізація дерева
Тепер напишемо код дерева.
Властивості Node
Для реалізації ми спочатку визначимо функцію з ім'ям Node, а потім конструктор з ім'ям Tree:
function Node(data) ( this.data = data; this.parent = null; this.children = ; )
Кожен екземпляр Node містить три властивості: data, parent і children. Перша властивість використовується для зберігання даних, пов'язаних із вузлом. Друга властивість вказує на один вузол. Третя властивість свідчить про дочірні вузли.
Властивості Tree
Визначимо наш конструктор для Tree, який у своєму тілі містить конструктор Node:
function Tree(data) ( var node = новий Node(data); this._root = node; )
Tree містить два рядки коду. Перший рядок створює новий екземпляр Node; другий рядок призначає node як кореневий елемент дерева.
Для визначення Tree та Node потрібно лише кілька рядків коду. Але цього достатньо, щоб допомогти нам задати ієрархічні дані. Щоб довести це, давайте використовуємо кілька прикладів для створення екземпляра Tree :
var tree = new Tree("CEO"); // (Data: "CEO", parent: null, children: ) tree._root;
Завдяки parent і children ми можемо додавати вузли як дочірні елементи для _root , а також призначати _root як батьківський елемент для цих вузлів. Інакше кажучи, ми можемо поставити ієрархію даних.
Методи дерева
Ми створимо такі п'ять методів:
- traverseDF(callback) ;
- traverseBF(callback);
- contains(data, traversal);
- add(child, parent);
- remove(node, parent) .
Так як для кожного методу потрібно проходження дерева, ми спочатку реалізуємо методи, які визначають різні види дерева.
Метод traverseDF(callback)
Метод для проходження дерева за допомогою пошуку у глибину:
Tree.prototype.traverseDF = function(callback) ( // це рекурсивна і миттєво викликана функція (function recurse(currentNode)) ( // крок 2 for (var i = 0, length = currentNode.children.length; i< length; i++) { // шаг 3 recurse(currentNode.children[i]); } // шаг 4 callback(currentNode); // шаг 1 })(this._root); };
traverseDF(callback) містить параметр з ім'ям зворотного дзвінка. (callback) - функція, яка буде викликатися пізніше в traverseDF(callback).
Тіло traverseDF(callback) включає ще одну функцію з ім'ям recurse . Ця рекурсивна функція, що посилається сама на себе і автоматично закінчується. Використовуючи кроки, описані в коментарях до функції recurse, я опишу весь процес, який використовує recurse, щоб пройти все дерево.
Ось ці кроки:
- Ми викликаємо recurse з кореневим вузлом дерева як аргумент. На даний момент currentNode вказує на поточний вузол;
- Входимо в цикл for і повторюємо його один раз для кожного дочірнього вузла для currentNode, починаючи з першого;
- Всередині тіла циклу for викликаємо рекурсивну функцію з дочірнім вузлом для вузла currentNode. Який саме це вузол залежить від поточної ітерації циклу for ;
- Коли currentNode більше не має дочірніх елементів, ми виходимо з циклу for і викликаємо ( callback), який ми передали під час виклику traverseDF(callback) .
Кроки 2 ( завершує себе), 3 (що викликає себе) і 4 (зворотний виклик) повторюються до проходження кожного вузла дерева.
Рекурсія – це дуже складна тема. Для її розуміння можна поекспериментувати з нашою поточною реалізацією traverseDF( callback)та спробувати зрозуміти, як це працює.
Наступний приклад демонструє прохід по дереву за допомогою traverseDF(callback). Для цього прикладу спочатку створимо дерево. Підхід, який я використовуватиму, не є ідеальним, але він працює. Краще було б використовувати метод add(value), який ми реалізуємо в кроці 4:
var tree = новий Tree ("one"); tree._root.children.push(new Node("two")); tree._root.children.parent = tree; tree._root.children.push(new Node("three")); tree._root.children.parent = tree; tree._root.children.push(new Node("four")); tree._root.children.parent = tree; tree._root.children.children.push(new Node("five")); tree._root.children.children.parent = tree._root.children; tree._root.children.children.push(new Node("six")); tree._root.children.children.parent = tree._root.children; tree._root.children.children.push(new Node("seven")); tree._root.children.children.parent = tree._root.children; /* створюємо наступне дерево one ├── two │ ├── five │ └── six ├── three └── four └── seven */
Тепер, давайте викликаємо traverseDF(callback) :
tree.traverseDF(function(node) (console.log(node.data))); /* виводимо наступні рядки на консоль "five" "six" "two" "three" "seven" "four" "one" */
Метод traverseBF(callback)
Метод проходження дерева по ширині. Різниця між пошуком у глибину та пошуком у ширину полягає в послідовності проходження вузлів дерева. Щоб проілюструвати це, використовуємо дерево, яке ми створили для реалізації методу traverseDF(callback) :
/* tree one (depth: 0) ├── two (depth: 1) │ ├── five (depth: 2) │ └── six (depth: 2) ├── three (depth: 1) └── four (depth: 1) └── seven (depth: 2) */
Тепер давайте передамо в traverseBF(callback) той самий зворотний виклик, який ми використовували для traverseDF(callback) :
tree.traverseBF(function(node) (console.log(node.data))); /* виводимо наступні рядки на консоль "one" "two" "three" "four" "five" "six" "seven" */
Виводимо рядки на консоль, і діаграма дерева покаже нам картину, що відображає принцип пошуку в ширину. Почніть із кореневого вузла; потім пройдіть один рівень і відвідайте кожен вузол цього рівня зліва направо. Повторіть цей процес, поки всі рівні не будуть пройдені. Реалізуємо код, за допомогою якого цей приклад працюватиме:
Tree.prototype.traverseBF = function(callback) ( var queue = new Queue(); queue.enqueue(this._root); currentTree = queue.dequeue(); while(currentTree)( for (var i = 0, length = currentTree.children.length;i< length; i++) { queue.enqueue(currentTree.children[i]); } callback(currentTree); currentTree = queue.dequeue(); } };
Визначення traverseBF(callback) поясню покроково:
- Створюємо екземпляр Queue;
- Додаємо вузол, який викликається traverseBF(callback) для екземпляра Queue;
- Оголошуємо змінну currentNode і ініціалізуємо її для node , який ми щойно додали до черги;
- Поки currentNode вказує на вузол, виконуємо код всередині циклу while;
- Використовуємо цикл for для проходження дочірніх вузлів currentNode;
- У тілі циклу for додаємо кожен дочірній вузол у чергу;
- Приймаємо currentNode і передаємо його як аргумент для callback;
- Встановлюємо як currentNode вузол, що видаляється з черги;
- До тих пір, поки поточнийNode вказує на вузол, повинен бути пройдений кожен вузол дерева. Для цього повторюємо кроки з 4 до 8.
Метод contains(callback, traversal)
Визначимо метод, який дозволить нам знаходити конкретне значення у дереві. Щоб використовувати будь-який з методів проходження дерева, я встановлюю для contains(callback, traversal) два аргументи, що приймаються: дані, які ми шукаємо, і тип проходження:
Tree.prototype.contains = function(callback, traversal) ( traversal.call(this, callback); );
У тілі contains(callback, traversal) для передачі this і callback ми використовуємо метод під назвою call . Перший аргумент пов'язує traversal з деревом, для якого викликається contains(callback, traversal); Другий аргумент - це функція, що викликається на кожному вузлі дерева.
Уявіть, що ми хочемо вивести на консоль всі вузли, які містять дані з непарним числом і пройти кожен вузол дерева за допомогою методу BFS. Для цього потрібно написати наступний код:
// Дерево - це приклад кореневого вузла tree.contains(function(node)( if (node.data === "two") ( console.log(node); ) ), tree.traverseBF);
Метод add(data, toData, traversal)
Тепер ми маємо метод для пошуку вузла в дереві. Давайте визначимо метод, який дозволить нам додати вузол до конкретного сайту:
Tree.prototype.add = function(data, toData, traversal) ( var child = new Node(data), parent = null, callback = function(node) ( if (node.data === toData) ( parent = node); ) );this.contains(callback, traversal);if (parent) (parent.children.push(child); child.parent = parent; ) else ( throw new Error("Cannot add node to a non-existent parent. "); )));
add(data, toData, traversal) визначає три параметри. data використовується для створення нового екземпляра вузла. toData використовується для порівняння кожного вузла в дереві. Третій параметр, traversal – це тип проходження дерева, що використовується у цьому методі.
У тілі add(data, toData, traversal) ми оголошуємо три змінні. Перша змінна, child, ініціалізується як новий екземпляр Node. Друга змінна, parent, ініціалізується як null; але пізніше вона буде вказувати на будь-який вузол у дереві, який відповідає значенню toData. Перепризначення parent виконується у третій змінній - callback.
callback - це функція, яка порівнює toData з властивістю data кожного вузла. Якщо вузол задовольняє умові оператора if, він призначається як parent.
Саме порівняння кожного вузла з toData здійснюється всередині add(data, toData, traversal). Тип проходження і callback повинні передаватися як аргументи add(data, toData, traversal).
Якщо parent у дереві немає, ми поміщаємо child в parent.children ; ми також призначаємо як parent батьківський елемент для child, інакше видається помилка.
Давайте використовуємо add(data, toData, traversal) у нашому прикладі:
var tree = new Tree("CEO"); tree.add("VP of Happiness", "CEO", tree.traverseBF); /* наше дерево "CEO" └── "VP of Happiness" */
Ось складніший приклад використання add(data, toData, traversal) :
var tree = new Tree("CEO"); tree.add("VP of Happiness", "CEO", tree.traverseBF); tree.add("VP of Finance", "CEO", tree.traverseBF); tree.add("VP of Sadness", "CEO", tree.traverseBF); tree.add("Director of Puppies", "VP of Finance", tree.traverseBF); tree.add("Manager of Puppies", "Director of Puppies", tree.traverseBF); /* дерево "CEO" ├── "VP of Happiness" ├── "VP of Finance" │ ├── "Director of Puppies" │ └── "Manager of Puppies" └── "VP of Sadness" */
Метод remove(data, fromData, traversal)
Для повної реалізації Tree нам потрібно додати метод із ім'ям remove(data, fromData, traversal). Аналогічно видаленню вузла з DOM цей метод видалятиме вузол і всі його дочірні вузли:
Tree.prototype.remove = function(data, fromData, traversal) ( var tree = this, parent = null, childToRemove = null, index; var callback = function(node) ( if (node.data === fromData) ( parent = node; ) );, this.contains(callback, traversal); exist."); ) else ( childToRemove = parent.children.splice(index, 1); ) ) else ( throw new Error("Parent does not exist."); ) return childToRemove; );
Так само, як add(data, toData, traversal) , метод видалення проходить все дерево, щоб знайти вузол, який містить другий аргумент, рівний в даний час відData . Якщо цей вузол знайдено, то parent вказує на нього першому операторі if .
У цьому syntax, Oracle compares the input expression (e) to each comparison expression e1, e2, …, en.
Якщо введення екземплярів еквівалентів будь-якого comparison expression, the case expression returns the corresponding result expression (r).
Якщо введення дзвінка не відображається в будь-який період повторення дзвінка, з'єднання CASE повторить дзвінок у послідовності ELSE, якщо функція ELSE exists, otherwise, it returns a null value.
Oracle використовує Short-circuit evaluation for the simple CASE expression. Це означає, що Oracle виявляє, що їх comparison expression (e1, e2, .. en) тільки перед тим, як comparing one of them with the input expression (e). Oracle не усвідомлює всі загальні запитання перед тим, як comparing any of them with the expression (e). Як результат, Oracle не визнає, що comparison expression if a previous one equals the input expression (e).
Simple CASE expression example
We will use the products table in the for demonstration.
Наступні методи використання CASE expression для калькуляції discount для кожного продукту категорії i.e., CPU 5%, відеокарта 10%, і інших продуктів категорії 8%
SELECT
CASE category_id
WHEN 1
THEN ROUND (list_price*0.05,2)-- CPU
WHEN 2
THEN ROUND (List_price*0.1,2)-- Video Card
ELSE ROUND (list_price*0.08,2)-- other categories
END discount
FROM
ORDER BY
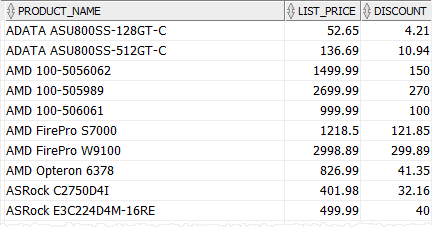
Зверніть увагу, що ми використовуємо ROUND () функцію до кінця дисконту до двох decimal places.
Searched CASE expression
У Oracle searched CASE expression evaluates list of Boolean expressions to determine the result.
Searched CASE statement has following syntax:
CASE
WHEN e1THEN r1
, COUNT(DISTINCT DepartmentID) [Кількість унікальних відділів], COUNT(DISTINCT PositionID) [Кількість унікальних посад], COUNT(BonusPercent) [Кількість співробітників яких вказано % бонусу], MAX(BonusPercent) [Максимальний відсоток бонусу], MIN (BonusPercent) [Мінімальний відсоток бонусу], SUM(Salary/100*BonusPercent) [Сума всіх бонусів], AVG(Salary/100*BonusPercent) [Середній розмір бонусу], AVG(Salary) [Середній розмір ЗП] FROM Employees
Для більшої наочності я вирішив зробити виняток і скористався синтаксисом […] для завдання псевдонімів колонок.Розберемо яким чином вийшло кожне повернене значення, а за одне згадаємо конструкції базового синтаксису оператора SELECT.
По-перше, т.к. ми в запиті не вказали WHERE-умови, то підсумки будуть вважатися для детальних даних, які виходять запитом:
SELECT * FROM Employees
Тобто. всім рядків таблиці Employees.
Для наочності виберемо лише поля та вирази, які використовуються в агрегатних функціях:
SELECT DepartmentID, PositionID, BonusPercent, Salary/100*BonusPercent , Salary FROM Employees
DepartmentID PositionID BonusPercent Salary/100*BonusPercent Salary 1 2 50 2500 5000 3 3 15 225 1500 2 1 NULL NULL 2500 3 4 30 600 2000 3 3 NULL NULL 1500 NULL NULL NULL NULL 2000
Це вихідні дані (детальні рядки), за якими і будуть рахуватися підсумки агрегованого запиту.Тепер розберемо кожне агреговане значення:
COUNT(*)- Т.к. ми запитали умови фільтрації у блоці WHERE, то COUNT(*) дало нам загальну кількість записів у таблиці, тобто. це кількість рядків, яка повертає запит: SELECT * FROM Employees
COUNT(DISTINCT DepartmentID)– повернуло значення 3, тобто. це число відповідає числу унікальних значень департаментів, зазначених у стовпці DepartmentID без урахування NULL значень. Пройдемося за значеннями колонки DepartmentID і розфарбуємо однакові значення в один колір (не соромтеся, для навчання всі методи хороші): Відкидаємо NULL, після чого ми отримали 3 унікальні значення (1, 2 і 3). Тобто. значення, що отримується COUNT(DISTINCT DepartmentID), у розгорнутому вигляді можна представити наступною вибіркою:
SELECT DISTINCT DepartmentID -- 2. беремо тільки унікальні значення FROM Employees WHERE DepartmentID IS NOT NULL -- 1. відкидаємо значення NULL

COUNT(DISTINCT PositionID)– те саме, що було сказано про COUNT(DISTINCT DepartmentID), лише полю PositionID. Дивимося на значення колонки PositionID і не шкодуємо фарб: 
COUNT(BonusPercent)– повертає кількість рядків, які мають значення BonusPercent, тобто. підраховується кількість записів, які BonusPercent IS NOT NULL. Тут буде простіше, т.к. не потрібно рахувати унікальні значення, досить просто відкинути записи з NULL значеннями. Беремо значення колонки BonusPercent і викреслюємо всі значення NULL: Залишається 3 значення. Тобто. у розгорнутому вигляді вибірку можна так:
SELECT BonusPercent - 2. беремо всі значення FROM Employees WHERE BonusPercent IS NOT NULL - 1. відкидаємо значення NULL

Т.к. ми не використовували слова DISTINCT, то вважатимуться і повторювані BonusPercent у разі їх наявності, без урахування BonusPercent рівних NULL. Для прикладу зробимо порівняння результату з використанням DISTINCT і без нього. Для більшої наочності скористаємось значеннями поля DepartmentID:
SELECT COUNT(*), -- 6 COUNT(DISTINCT DepartmentID), -- 3 COUNT(DepartmentID) -- 5 FROM Employees

MAX(BonusPercent)- Повертає максимальне значення BonusPercent, знову ж таки без урахування NULL значень.
Беремо значення колонки BonusPercent і шукаємо серед них максимальне значення, на значення NULL не звертаємо уваги:
SELECT TOP 1 BonusPercent FROM Employees WHERE BonusPercent IS NOT NULL ORDER BY BonusPercent DESC -- сортуємо за спаданням
MIN(BonusPercent)- Повертає мінімальне значення BonusPercent, знову ж таки без урахування NULL значень. Як у випадку з MAX, тільки шукаємо мінімальне значення, ігноруючи NULL: 
Тобто. ми отримуємо наступне значення:
SELECT TOP 1 BonusPercent FROM Employees WHERE BonusPercent IS NOT NULL ORDER BY BonusPercent - сортуємо за зростанням
Наочне уявлення MIN(BonusPercent) та MAX(BonusPercent):

SUM(Salary/100*BonusPercent)- Повертає суму всіх не NULL значень. Розбираємо значення виразу (Salary/100*BonusPercent): 
Тобто. відбувається підсумовування наступних значень:
SELECT Salary/100*BonusPercent FROM Employees WHERE Salary/100*BonusPercent IS NOT NULL

AVG(Salary/100*BonusPercent)- Повертає середнє значень. NULL-вирази не враховуються, тобто. це відповідає другому виразу: SELECT AVG(Salary/100*BonusPercent), -- 1108.33333333333 SUM(Salary/100*BonusPercent)/COUNT(Salary/100*BonusPercent), -- 1108.33333333336 SUM(S6(Salary/100*BonusPercent)) FROM Employees

Тобто. знову ж таки NULL-значення не враховуються при підрахунку кількості.
Якщо ж вам необхідно обчислити середнє за всіма співробітниками, як у третьому виразі, що дає 554.166666666667, то використовуйте попереднє перетворення NULL значень у нуль:
SELECT AVG(ISNULL(Salary/100*BonusPercent,0)), -- 554.166666666667 SUM(Salary/100*BonusPercent)/COUNT(*) -- 554.166666666667 FROM Employees
AVG(Salary)- Власне, тут все те саме що і в попередньому випадку, тобто. якщо у співробітника Salary дорівнює NULL, він не врахується. Щоб врахувати всіх співробітників, відповідно робите попереднє перетворення значення NULL AVG(ISNULL(Salary,0))
Підіб'ємо деякі підсумки:- COUNT(*) – служить для підрахунку загальної кількості рядків, отриманих оператором «SELECT … WHERE …»
- у всіх інших перерахованих вище агрегатних функціях при розрахунку підсумку, NULL-значення не враховуються
- якщо нам потрібно врахувати всі рядки, це більше актуально для функції AVG, то попередньо необхідно здійснити обробку значень NULL, наприклад, як було показано вище «AVG(ISNULL(Salary,0))»
Відповідно при завданні з агрегатними функціями додаткової умови в блоці WHERE, будуть підраховані лише підсумки, що за рядками задовольняють умові. Тобто. Розрахунок агрегатних значень відбувається для підсумкового набору, отриманого за допомогою конструкції SELECT. Наприклад, зробимо все те саме, але тільки в розрізі ІТ-відділу:
SELECT COUNT(*) [Загальна кількість співробітників], COUNT(DISTINCT DepartmentID) [Кількість унікальних відділів], COUNT(DISTINCT PositionID) [Кількість унікальних посад], COUNT(BonusPercent) [Кількість співробітників, у яких вказано % бонуса] , MAX(BonusPercent) [Максимальний відсоток бонусу], MIN(BonusPercent) [Мінімальний відсоток бонусу], SUM(Salary/100*BonusPercent) [Сума всіх бонусів], AVG(Salary/100*BonusPercent) [Середній розмір бонусу], AVG (Salary) [Середній розмір ЗП] FROM Employees WHERE DepartmentID=3 -- врахувати лише ІТ-відділ
Пропоную вам для більшого розуміння роботи агрегатних функцій самостійно проаналізувати кожне отримане значення. Розрахунки тут ведемо, відповідно, за детальними даними отриманим запитом:SELECT DepartmentID, PositionID, BonusPercent, Salary/100*BonusPercent , Salary FROM Employees WHERE DepartmentID=3 -- врахувати лише ІТ-відділ
DepartmentID PositionID BonusPercent Salary/100*BonusPercent Salary 3 3 15 225 1500 3 4 30 600 2000 3 3 NULL NULL 1500 Йдемо далі. У випадку, якщо агрегатна функція повертає NULL (наприклад, у всіх співробітників не вказано значення Salary), або у вибірку не потрапило жодного запису, а у звіті для такого випадку нам потрібно показати 0, то функцією ISNULL можна обернути агрегатний вираз:
SELECT SUM (Salary), AVG (Salary), - обробляємо результат за допомогою ISNULL ISNULL (SUM (Salary), 0), ISNULL (AVG (Salary), 0) FROM Employees WHERE DepartmentID = 10 - тут спеціально вказаний неіснуючий відділ , щоб запит не повернув записів
(No column name) (No column name) (No column name) (No column name) NULL NULL 0 0 Я вважаю, що дуже важливо розуміти призначення кожної агрегатної функції і як вони роблять розрахунок, т.к. SQL це головний інструмент, який служить для розрахунку підсумкових значень.
У разі ми розглянули, як кожна агрегатна функція поводиться самостійно, тобто. вона застосовувалася до значень всього набору записів, отриманих командою SELECT. Далі ми розглянемо, як ці функції застосовуються для обчислення підсумків по групах, за допомогою конструкції GROUP BY.
GROUP BY – угруповання даних
До цього ми вже обчислювали підсумки для конкретного відділу приблизно таким чином:SELECT COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=3 -- дані лише по ІТ відділу
А тепер уявіть, що нас попросили отримати такі ж цифри у розрізі кожного відділу. Звичайно, ми можемо засукати рукави і виконати цей же запит для кожного відділу. Отже, сказано-зроблено, пишемо 4 запити:
SELECT "Адміністрація" Info, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=1 -- дані по Адміністрації SELECT "Бухгалтерія" Info, COUNT(DISTINCT PositionID) Position *) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=2 -- дані по Бухгалтерії SELECT "ІТ" Info, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE - дані по ІТ відділу SELECT "Інші" Info, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) Salary
В результаті ми отримаємо 4 набори даних:

Зверніть увагу, що ми можемо використовувати поля, задані у вигляді констант – "Адміністрація", "Бухгалтерія", …
Загалом усі цифри, про які нас просили, ми здобули, поєднуємо все в Excel і віддаємо директорові.
Звіт директору сподобався, і він каже: «а додайте ще колонку з інформацією щодо середнього окладу». І як завжди, це потрібно зробити дуже терміново.
Мда, що робити? До того ж уявимо ще відділів у нас не 3, а 15.
Ось якраз приблизно для таких випадків служить конструкція GROUP BY:
SELECT DepartmentID, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount, AVG(Salary) SalaryAvg - плюс виконуємо побажання директора FROM Employees GROUP BY DepartmentID
DepartmentID PositionCount EmplCount SalaryAmount SalaryAvg NULL 0 1 2000 2000 1 1 1 5000 5000 2 1 1 2500 2500 3 2 3 5000 1666.66666666667
Ми отримали ті самі дані, але тепер використовуючи тільки один запит!Поки не звертайте увагу, що департаменти у нас вивелися у вигляді цифр, далі ми навчимося виводити все красиво.
У пропозиції GROUP BY можна вказувати декілька полів «GROUP BY поле1, поле2, …, поле N», у цьому випадку угруповання відбудеться за групами, які утворюють значення даних полів «поле1, поле2, …, поле N».
Для прикладу зробимо групування даних у розрізі Відділів та Посад:
SELECT DepartmentID,PositionID, COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees GROUP BY DepartmentID,PositionID
Після чого робиться пробіжка по кожній комбінації та робляться обчислення агрегатних функцій:SELECT COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID NULL AND PositionID IS NULL SELECT COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=1 AND Position COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=3 AND PositionID=4
А потім всі ці результати поєднуються разом і віддаються нам у вигляді одного набору:

З основного, слід зазначити, що у разі угруповання (GROUP BY), у переліку колонок у блоці SELECT:
- Ми можемо використовувати лише колонки, перелічені у блоці GROUP BY
- Можна використовувати вирази з полями із блоку GROUP BY
- Можна використовувати константи, т.к. вони не впливають на результат угруповання
- Усі інші поля (не перелічені в блоці GROUP BY) можна використовувати лише з агрегатними функціями (COUNT, SUM, MIN, MAX, …)
- Не обов'язково перераховувати всі колонки із блоку GROUP BY у списку колонок SELECT
І демонстрація всього сказаного:
SELECT "Рядок константа" Const1, - константа у вигляді рядка 1 Const2, - константа у вигляді числа - вираз з використанням полів, що беруть участь у групуванні CONCAT("Відділ №",DepartmentID) ConstAndGroupField, CONCAT("Відділ №",DepartmentID ,", Посада № ",PositionID) ConstAndGroupFields, DepartmentID, -- поле зі списку полів що у групуванні -- PositionID, -- поле що у групуванні, необов'язково дублювати тут COUNT(*) EmplCount, -- у рядків в кожній групі - інші поля можна використовувати тільки з агрегатними функціями: COUNT, SUM, MIN, MAX, … SUM (Salary) SalaryAmount, MIN (ID)
Так само варто відзначити, що угруповання можна робити не лише по полях, але й за виразами. Наприклад згрупуємо дані по співробітникам, за роками народження:
SELECT CONCAT("Рік народження - ",YEAR(Birthday)) YearOfBirthday, COUNT(*) EmplCount FROM Employees GROUP BY YEAR(Birthday)
Розглянемо приклад із складнішим виразом. Наприклад, отримаємо градацію співробітників за роками народження:
SELECT CASE WHEN YEAR(Birthday)>=2000 THEN "від 2000" WHEN YEAR(Birthday)>=1990 THEN "1999-1990" WHEN YEAR(Birthday)>=1980 THEN "1989-19 1970 THEN "1979-1970" WHEN Birthday IS NOT NULL THEN "раніше 1970" ELSE "не вказано" END RangeName, COUNT(*) (Birthday)>=1990 THEN "1999-1990" WHEN YEAR(Birthday)>=1980 THEN "1989-1980" WHEN YEAR(Birthday)>=1970 THEN "1979-1970" WHEN ELSE "не вказано" END
RangeName EmplCount 1979-1970 1 1989-1980 2 не вказано 2 раніше 1970 1
Тобто. у цьому випадку угруповання проводиться за попередньо обчисленим для кожного співробітника CASE-виразом:SELECT ID, CASE WHEN YEAR(Birthday)>=2000 THEN "від 2000" WHEN YEAR(Birthday)>=1990 THEN "1999-1990" WHEN YEAR(Birthday)>=1980 THEN "1989 >=1970 THEN "1979-1970" WHEN Birthday IS NOT NULL THEN "раніше 1970" ELSE "не вказано" END FROM Employees

Ну і звичайно ви можете об'єднувати в блоці GROUP BY вирази з полями:
SELECT DepartmentID, CONCAT("Рік народження - ",YEAR(Birthday)) YearOfBirthday, COUNT(*) EmplCount FROM Employees GROUP BY YEAR(Birthday),DepartmentID -- порядок може не збігатися з порядком їх використання в блоці SELECT ORDER YearOfBirthday - наостанок ми можемо застосувати до результату сортування
Повернемося до нашого початкового завдання. Як ми вже знаємо, звіт дуже сподобався директору, і він попросив нас робити його щотижня, щоб він міг моніторити зміни компанії. Щоб, не перебивати щоразу в Excel цифрове значення відділу на його найменування, скористаємося знаннями, які ми вже маємо, і вдосконалимо наш запит:
SELECT CASE DepartmentID WHEN 1 THEN "Адміністрація" WHEN 2 THEN "Бухгалтерія" WHEN 3 THEN "ІТ" ELSE "Інші" END Info, COUNT(DISTINCT PositionID) ) SalaryAvg -- плюс виконуємо побажання директора FROM Employees GROUP BY DepartmentID ORDER BY Info -- додамо для більшої зручності сортування по колонці Info
Хоча з боку може виглядати і страшно, але все одно це краще, ніж було спочатку. Недоліком є те, що якщо заведуть новий відділ та його співробітників, то вираз CASE нам потрібно буде дописувати, щоб співробітники нового відділу не потрапили до групи «Інші».Але нічого, з часом, ми навчимося робити все красиво, щоб вибірка у нас не залежала від появи в БД нових даних, а була динамічною. Трохи забігу вперед, щоб показати написання яких запитів ми прагнемо прийти:
SELECT ISNULL(dep.Name,"Інші") DepName, COUNT(DISTINCT emp.PositionID) PositionCount, COUNT(*) EmplCount, SUM(emp.Salary) SalaryAmount, AVG(emp.Salary) SalaryAvg - плюс виконуємо побажання директора FROM Employees emp LEFT JOIN Departments dep ON emp.DepartmentID=dep.ID GROUP BY emp.DepartmentID,dep.Name ORDER BY DepName
Загалом, не переживайте – всі починали просто. Поки що вам просто потрібно зрозуміти суть конструкції GROUP BY.
Насамкінець, давайте подивимося яким чином можна будувати зведені звіти за допомогою GROUP BY.
Наприклад виведемо зведену таблицю, у межах відділів, те щоб було підраховано сумарна вести, одержувана співробітниками у розбивці по посадам:
SELECT DepartmentID, SUM(CASE WHEN PositionID=1 THEN Salary END) [Бухгалтера], SUM(CASE WHEN PositionID=2 THEN Salary END) [Директора], SUM(CASE WHEN PositionID=3 THEN Salary END) [Програмісти], SUM CASE WHEN PositionID=4 THEN Salary END) [Старші програмісти], SUM(Salary) [Разом у відділі] FROM Employees GROUP BY DepartmentID
Тобто. ми можемо вільно використовувати будь-які висловлювання всередині агрегатних функцій.Можна, звичайно, переписати і за допомогою IIF:
SELECT DepartmentID, SUM(IIF(PositionID=1,Salary,NULL)) [Бухгалтера], SUM(IIF(PositionID=2,Salary,NULL)) [Директора], SUM(IIF(PositionID=3,Salary,NULL)) [Програмісти], SUM(IIF(PositionID=4,Salary,NULL)) [Старші програмісти], SUM(Salary) [Разом у відділі] FROM Employees GROUP BY DepartmentID
Але у випадку IIF нам доведеться явно вказувати NULL, яке повертається у разі невиконання умови.
В аналогічних випадках мені більше подобається використовувати CASE без блоку ELSE, ніж писати NULL. Але це, звичайно, справа смаку, про який не сперечаються.
І давайте згадаємо, що в агрегатних функціях при агрегації не враховуються значення NULL.
Для закріплення зробіть самостійний аналіз отриманих даних за розгорнутим запитом:
SELECT DepartmentID, CASE WHEN PositionID=1 THEN Salary END [Бухгалтера], CASE WHEN PositionID=2 THEN Salary END [Директора], CASE WHEN PositionID=3 THEN Salary END [Програмісти], CASE WHEN PositionID=4 THEN ], Salary [Разом з відділу] FROM Employees
DepartmentID Бухгалтера Директора Програмісти Старші програмісти Разом з відділу 1 NULL 5000 NULL NULL 5000 3 NULL NULL 1500 NULL 1500 2 2500 NULL NULL NULL 2500 3 NULL NULL NULL 2000 2000 3 NULL NULL 1500 NULL 1500 NULL NULL NULL NULL NULL 2000 І ще давайте пригадаємо, що якщо замість NULL ми хочемо побачити нулі, то ми можемо обробити значення, яке повертається агрегатною функцією. Наприклад:
SELECT DepartmentID, ISNULL(SUM(IIF(PositionID=1,Salary,NULL)),0) [Бухгалтера], ISNULL(SUM(IIF(PositionID=2,Salary,NULL)),0) [Директора], ISNULL(SUM (IIF(PositionID=3,Salary,NULL)),0) [Програмісти], ISNULL(SUM(IIF(PositionID=4,Salary,NULL)),0) [Старші програмісти], ISNULL(SUM(Salary),0 ) [Разом по відділу] FROM Employees GROUP BY DepartmentID
Тепер з метою практики, ви можете:- вивести назви департаментів замість їх ідентифікаторів, наприклад, додавши вираз CASE, що обробляє DepartmentID в блоці SELECT
- додайте сортування на ім'я відділу за допомогою ORDER BY
GROUP BY у скупі з агрегатними функціями, один з основних засобів, що служать для отримання зведених даних з БД, адже зазвичай дані у такому вигляді і використовуються, т.к. зазвичай від нас вимагають надання зведених звітів, а не детальних даних (простирадла). І звичайно все це крутиться навколо знання базової конструкції, т.к. перш ніж щось підсумувати (агрегувати), вам потрібно насамперед це правильно вибрати, використовуючи "SELECT ... WHERE ...".
Важливе місце тут має практика, тому, якщо ви поставили за мету зрозуміти мову SQL, не вивчити, а саме зрозуміти - практикуйтеся, практикуйтеся і практикуйтеся, перебираючи різні варіанти, які тільки зможете придумати.
На початкових порах, якщо ви не впевнені в правильності отриманих агрегованих даних, робіть детальну вибірку, яка включає всі значення, якими йде агрегація. І перевіряйте правильність розрахунків вручну за цими детальними даними. У цьому випадку дуже може допомогти використання програми Excel.
Припустимо, що ви дійшли до цього моменту
Допустимо, що ви бухгалтер Сидоров С.С., який вирішив навчитися писати SELECT-запити.
Припустимо, що ви вже встигли дочитати цей підручник до цього моменту, і вже впевнено користуєтесь усіма перерахованими базовими конструкціями, тобто. ви вмієте:- Вибирати детальні дані за умовою WHERE з однієї таблиці
- Вмієте користуватися агрегатними функціями та групуванням з однієї таблиці
Так, але вони не врахували, що ви не вмієте будувати запити з кількох таблиць, лише з однієї, тобто. ви не вмієте робити щось на кшталт такого:
SELECT emp.*, -- повернути всі поля таблиці Employees dep.Name DepartmentName, -- до цих полів додати поле Name з таблиці Departments pos.Name PositionName -- і додати поле Name з таблиці Positions FROM Employees emp LEFT JOIN Departments dep ON emp.DepartmentID=dep.ID LEFT JOIN Positions pos ON emp.PositionID=pos.ID
Незважаючи на те, що ви цього не вмієте, повірте, ви молодець, і вже так багато досягли.І так, як можна скористатися вашими поточними знаннями і отримати при цьому ще більш продуктивні результати?! Скористаємося силою колективного розуму – йдемо до програмістів, які у вас, тобто. до Андрєєва А.А., Петрова П.П. або Миколаєву Н.Н., і попросимо когось із них написати для вас уявлення (VIEW або просто «В'юха», так вони навіть, думаю, швидше зрозуміють вас), яке крім основних полів з таблиці Employees, ще повертатиме поля з "Назвою відділу" та "Назвою посади", яких вам так бракує зараз для щотижневого звіту, яким вас завантажив Іванов І.І.
Т.к. ви всі грамотно пояснили, то ІТ-шники, відразу ж зрозуміли, що від них хочуть і створили, спеціально для вас, уявлення з назвою ViewEmployeesInfo.
Уявляємо, що наступної команди не бачите, т.к. це роблять ІТ-шники:
CREATE VIEW ViewEmployeesInfo AS SELECT emp.*, -- повернути всі поля таблиці Employees dep.Name DepartmentName, -- до цих полів додати поле Name з таблиці Departments pos.Name PositionName -- і додати поле Name з таблиці Positions FROM Employees emp LEFT JOIN Departments dep ON emp.DepartmentID=dep.ID LEFT JOIN Positions pos ON emp.PositionID=pos.ID
Тобто. для вас весь цей, поки страшний і незрозумілий, текст залишається за кадром, а ІТ-шники дають вам тільки назву уявлення «ViewEmployeesInfo», яке повертає всі вищезгадані дані (тобто те, що ви у них просили).
Ви тепер можете працювати з даним поданням, як зі звичайною таблицею:
SELECT * FROM ViewEmployeesInfo
Т.к. тепер всі необхідні для звіту дані є в одній «таблиці» (а-ля завірюха), то ви з легкістю зможете переробити свій щотижневий звіт:SELECT DepartmentName, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount, AVG(Salary) SalaryAvg FROM ViewEmployeesInfo emp GROUP BY DepartmentID,DepartmentName ORDER BY DepartmentName
Тепер усі назви відділів на місцях плюс до того ж запит став динамічним, і буде змінюватися при додаванні нових відділів та їх співробітників, тобто. вам тепер нічого переробляти не потрібно, а достатньо разів на тиждень виконати запит і віддати результат директорові.Тобто. Вам в цьому випадку, як би нічого і не змінилося, ви продовжуєте так само працювати з однією таблицею (тільки вже правильніше сказати з поданням ViewEmployeesInfo), яке повертає всі необхідні вам дані. Завдяки допомозі ІТ-шників, деталі з добування DepartmentName і PositionName залишилися для вас у чорній скриньці. Тобто. уявлення вам виглядає так само, як і звичайна таблиця, вважайте, що це розширена версія таблиці Employees.
Давайте для прикладу ще сформуємо відомість, щоб ви переконалися, що все дійсно так, як я і говорив (що вся вибірка йде з одного уявлення):
SELECT ID, Name, Salary FROM ViewEmployeesInfo WHERE Salary IS NOT NULL AND Salary>0 ORDER BY Name
Сподіваюся, що цей запит вам зрозумілий.Використання уявлень у деяких випадках дає можливість значно розширити межі користувачів, які мають написання базових SELECT-запитів. У даному випадку представлення являє собою плоску таблицю з усіма необхідними користувачеві даними (для тих, хто розуміється на OLAP, це можна порівняти з наближеною подобою OLAP-куба з фактами та вимірами).
Вирізка із вікіпедії.Хоча SQL і замислювався як роботи кінцевого користувача, зрештою він став настільки складним, що перетворився на інструмент програміста.
Як бачите, шановні користувачі, мова SQL спочатку замислювався як інструмент для вас. Отже, все у ваших руках та бажанні, не відпускайте руки.
HAVING – накладення умови вибірки до згрупованих даних
Власне якщо ви зрозуміли, що таке угруповання, то з HAVING нічого складного немає. HAVING – чимось подібний до WHERE, тільки якщо WHERE-умова застосовується до детальних даних, то HAVING-умова застосовується до вже згрупованих даних. З цієї причини в умовах блоку HAVING ми можемо використовувати або вирази з полями, що входять до угруповання, або вирази, що містяться в агрегатних функціях.Розглянемо приклад:
SELECT DepartmentID, SUM(Salary) SalaryAmount FROM Employees GROUP BY DepartmentID HAVING SUM(Salary)>3000
DepartmentID SalaryAmount 1 5000 3 5000
Тобто. даний запит повернув нам згруповані дані лише з тим відділам, які мають сума ЗП всіх співробітників перевищує 3000, тобто. "SUM (Salary)> 3000".
Тобто. тут у першу чергу відбувається угруповання та обчислюються дані по всіх відділах:
SELECT DepartmentID, SUM(Salary) SalaryAmount FROM Employees GROUP BY DepartmentID -- 1. отримуємо згруповані дані по всіх відділах
А вже до цих даних застосовується умова, зазначена в блоці HAVING:
SELECT DepartmentID, SUM(Salary) SalaryAmount FROM Employees GROUP BY DepartmentID -- 1. отримуємо згруповані дані по всіх відділах HAVING SUM(Salary)>3000 -- 2. умова для фільтрації згрупованих даних
У HAVING-умові так само можна будувати складні умови, використовуючи оператори AND, OR та NOT:
SELECT DepartmentID, SUM(Salary) SalaryAmount FROM Employees GROUP BY DepartmentID HAVING SUM(Salary)>3000 AND COUNT(*)<2 -- и число людей меньше 2-х

Як можна помітити агрегатна функція (див. «COUNT(*)») може бути вказана тільки в блоці HAVING.
Відповідно ми можемо відобразити лише номер відділу, що підпадає під HAVING-умову:
SELECT DepartmentID FROM Employees GROUP BY DepartmentID HAVING SUM(Salary)>3000 AND COUNT(*)<2 -- и число людей меньше 2-х
Приклад використання HAVING-умови поля включеного в GROUP BY:
SELECT DepartmentID, SUM(Salary) SalaryAmount FROM Employees GROUP BY DepartmentID -- 1. зробити угруповання HAVING DepartmentID=3 -- 2. накласти фільтр на результат угруповання
Це лише приклад, т.к. в даному випадку перевірку логічніше було б зробити через WHERE-умову:
SELECT DepartmentID, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=3 - 1. провести фільтрацію детальних даних GROUP BY DepartmentID - 2. зробити угруповання тільки за відібраними записами
Тобто. спочатку відфільтрувати співробітників з відділу 3, і потім зробити розрахунок.
Примітка.Насправді, незважаючи на те, що ці два запити виглядають по-різному, оптимізатор СУБД може виконати їх однаково.
Думаю, на цьому розповідь про HAVING-умови можна закінчити.
Підведемо підсумки
Зведемо дані отримані у другій та третій частині та розглянемо конкретне місце розташування кожної вивченої нами конструкції та вкажемо порядок їх виконання:Конструкція/Блок Порядок виконання Виконувана функція SELECT вирази, що повертаються 4 Повернення даних, отриманих запитом FROM джерело 0 У нашому випадку це поки що всі рядки таблиці WHERE умова вибірки із джерела 1 Відбираються лише рядки, що проходять за умовою GROUP BY вирази угруповання 2 Створення груп за вказаним виразом угруповання. Розрахунок агрегованих значень за цими групами, які у SELECT чи HAVING блоках HAVING фільтр за згрупованими даними 3 Фільтрування, що накладається на згруповані дані ORDER BY вираз сортування результату 5 Сортування даних за вказаним виразом Звичайно, ви також можете застосувати до згрупованих даних пропозиції DISTINCT і TOP, вивчені в другій частині.
Ці пропозиції в цьому випадку застосовуються до остаточного результату:
SELECT TOP 1 -- 6. застосовується в останню чергу SUM(Salary) SalaryAmount FROM Employees GROUP BY DepartmentID HAVING SUM(Salary)>3000 ORDER BY DepartmentID -- 5. сортування результату
Як вийшли дані результати, проаналізуйте самостійно.
Висновок
Основна мета яку я ставив у цій частині – розкрити вам суть агрегатних функцій та угруповань.Якщо базова конструкція дозволяла нам отримати необхідні детальні дані, то застосування агрегатних функцій та угруповань до цих детальних даних дало нам можливість отримати по них зведені дані. Отже, як бачите тут усе важливе, т.к. одне спирається інше – без знання базової конструкції ми зможемо, наприклад, правильно відібрати дані, якими нам треба прорахувати результати.
Тут я навмисно намагаюся показувати лише основи, щоб зосередити увагу початківців на найголовніших конструкціях та не перевантажувати їх зайвою інформацією. Тверде розуміння основних конструкцій (про які я ще продовжу розповідь у наступних частинах) дасть вам можливість вирішити практично будь-яке завдання щодо вибірки даних з РБД. Основні конструкції оператора SELECT застосовні в такому ж вигляді практично у всіх СУБД (відмінності в основному складаються в деталях, наприклад, у реалізації функцій – для роботи з рядками, часом тощо).
Надалі, тверде знання бази дасть вам можливість самостійно вивчити різні розширення мови SQL, такі як:
- GROUP BY ROLLUP(…), GROUP BY GROUPING SETS(…), …
- PIVOT, UNPIVOT
- і т.п.
Якщо ви робите перші кроки в SQL, то зосередьтеся насамперед, саме з вивченні базових конструкцій, т.к. володіючи базою, все інше вам зрозуміти буде набагато легше, до того ж самостійно. Вам насамперед, хіба що потрібно об'ємно зрозуміти можливості мови SQL, тобто. які операції він взагалі дозволяє зробити над даними. Донести до початківців інформацію в об'ємному вигляді – це ще одна з причин, чому я показуватиму тільки найголовніші (залізні) конструкції.
Удачі вам у вивченні та розумінні мови SQL.
Частина четверта -
Останні матеріали розділу:

По вуха в оге та еге російська Схеми аналізу творів Алгоритм порівняльного аналізу 1. Знайти риси подібності двох текстів на рівні: · сюжету або мотиву; · Образною...

Лунін Віктор Володимирович © Лунін В. В., 2013 © Звонарьова Л. У., вступна стаття, 2013 © Агафонова Н. М., ілюстрації, 2013 © Оформлення серії. ВАТ «Видавництво «Дитяча...

Ах війна ти зробила підла авторка Ах, війна, що ж ти зробила, підла: стали тихими наші двори, наші хлопчики голови підняли, подорослішали вони до пори, на порозі ледь помаячили і...