Математика и информатика. Учебное пособие по всему курсу
Функция распределения в этом случае согласно (5.7), примет вид:
где: m – математическое ожидание, s– среднеквадратическое отклонение.
Нормальное распределение называют еще гауссовским по имени немецкого математика Гаусса . Тот факт, что случайная величина имеет нормальное распределение с параметрами: m,, обозначают так: N (m,s), где: m =a =M ;
Достаточно часто в формулах математическое ожидание обозначают через а . Если случайная величина распределена по закону N(0,1), то она называется нормированной или стандартизированной нормальной величиной. Функция распределения для нее имеет вид:
|
|
 .
.График плотности нормального распределения, который называют нормальной кривой или кривой Гаусса, изображен на рис.5.4.

Рис. 5.4. Плотность нормального распределения
Определение числовых характеристик случайной величины по её плотности рассматривается на примере.
Пример 6 .
Непрерывная случайная величина задана плотностью распределения:![]() .
.
Определить вид распределения, найти математическое ожидание M(X) и дисперсию D(X).
Сравнивая заданную плотность распределения с (5.16) можно сделать вывод, что задан нормальный закон распределения с m =4. Следовательно, математическое ожидание M(X)=4, дисперсия D(X)=9.
Среднее квадратическое отклонение s=3.
Функция Лапласа, имеющая вид:
|
|
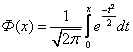 ,
,связана с функцией нормального распределения (5.17), cоотношением:
F 0 (x) = Ф(х) + 0,5.
Функции Лапласа нечётная.
Ф(-x )=-Ф(x ).
Значения функции Лапласа Ф(х) табулированы и берутся из таблицы по значению х (см. Приложение 1).
Нормальное распределение непрерывной случайной величины играет важную роль в теории вероятностей и при описании реальности, имеет очень широкое распространение в случайных явлениях природы. На практике очень часто встречаются случайные величины, образующиеся именно в результате суммирования многих случайных слагаемых. В частности, анализ ошибок измерения показывает, что они являются суммой разного рода ошибок. Практика показывает, что распределение вероятностей ошибок измерения близко к нормальному закону.
С помощью функции Лапласа можно решать задачи вычисления вероятности попадания в заданный интервал и заданного отклонения нормальной случайной величины.
Законы распределений случайных величин.
Большинство СВ подчиняется определенному закону распределения, зная который можно предвидеть вероятности попадания исследуемой СВ в определенные интервалы. Это очень важно при анализе экономических показателей, т.к. в этом случае появляется возможность осуществлять продуманную политику с учетом возможности возникновения той или иной ситуации.
Законов распределений достаточно много. К числу наиболее активно использующихся в эконометрическом анализе относятся:
Нормальное распределение (распределение Гаусса);
Распределение χ 2 ;
Распределение Стьюдента;
Распределение Фишера.
Для удобства использования данных законов были разработаны таблицы критических точек, которые позволяют быстро и эффективно оценивать соответствующие вероятности.
Нормальное распределение (распределение Гаусса) является предельным случаем почти всех реальных распределений вероятности. Поэтому оно используется в очень большом числе реальных приложений теории вероятностей.
СВ Х имеет нормальное распределение, если ее плотность вероятности имеет вид:
 (14)
(14)
Это равносильно тому, что
 (15)
(15)
СВ, имеющая нормальное распределение, называется нормально распределенной или нормальной. Графики плотности вероятности и функции распределения нормальной СВ изображены на рис.1 и 2.

0 m – σ m m + σ x
Рис.1. График плотности вероятности нормального распределения СВ Х.

Рис.2. Функция распределения нормальной СВ.
Как видно из формул (1) и (2), нормальное распределение зависит от параметров m и σ
и полностью определяется ими. При этом m = M (X),
σ = σ (Х),
т.е. D (X) = σ 2 , π = 3,14159…, e = 2,71828….
Если СВ Х
имеет нормальное распределение с параметрами M (X) = m
и
σ (Х) = σ
, то символически это можно записать так:
Х ~ N (m, σ) или Х ~ N (m, σ 2).
Очень важным частным случаем нормального распределения является ситуация, когда m = 0 и σ = 1 . В этом случае говорят о стандартизированном (стандартном) нормальном распределении.
Стандартизированную нормальную СВ обозначают через U (U ~ N (0,1)), учитывая при этом, что
 ;
;  (16)
(16)
Для практических расчетов специально разработаны таблицы функций
f (u), F (u)
стандартизированного нормального распределения, но чаще используется так называемая таблица значений Лапласа Ф (
u).
Функция Лапласа имеет вид:
 (17)
(17)
Эту таблицу можно использовать для любой нормальной СВ
Х (Х ~ N (m, σ))
при расчете соответствующих вероятностей:
Заметим, что если Х ~ N (m, σ),
то  ~ N(0,1).
~ N(0,1).
Как видно из предыдущих рисунков, нормально распределенная СВ Х ведет себя достаточно предсказуемо. График ее плотности вероятности (рис.1) симметричен относительно прямой Х = m . Площадь фигуры под графиком плотности вероятности должна оставаться равной единице при любых значениях m и σ. Следовательно, чем меньше значение σ , тем более крутым является график.
Кроме того, справедливы следующие соотношения:
Р ( Х – M (Х) < σ) = 0,68; Р ( Х – M (Х) < 2σ) = 0,95;
Р ( Х – M (Х) < 3σ) = 0,9973 .
Другими словами, значения нормально распределенной СВ
Х (Х ~ N (m, σ))
на 99,73 % сосредоточены в области [ m – 3σ, m + 3σ ].
Важным является тот факт, что линейная комбинация произвольного количества нормальных СВ имеет нормальное распределение . При этом, если Х ~ N (m х, σ х) и Y ~ N (m y , σ y) – независимые СВ, то
Z = aX + bY ~ N (m z , σ) , (19)
где m z = a m х + b m y ; σ z 2 = a 2 σ x 2 + b 2 σ y 2 .
Многие экономические показатели имеют нормальный или близкий к нормальному закон распределения. Например, доход населения, прибыль фирм в отрасли, объем потребления и т.д. имеют близкое к нормальному распределение.
Нормальное распределение используется при проверке различных гипотез в статистике (о величине математического ожидания при известной дисперсии, о равенстве математических ожиданий и т.д.).
Часто при моделировании экономических процессов приходится рассматривать СВ, которые представляют собой алгебраическую комбинацию нескольких СВ. Существенную роль в этом играет ряд специально разработанных теоретических законов распределений. К ним относятся χ 2 – распределение, распределения Стьюдента и Фишера.
Распределение χ 2 (хи – квадрат)
Пусть Х i , i = 1, 2, …, n – независимые нормально распределенные СВ с математическими ожиданиями m i и средними квадратическими отклонениями σ i соответственно, т.е. Х i ~ N (m i , σ i).
Тогда СВ  , i = 1, 2, …, n
, являются независимыми СВ, имеющими стандартизированное нормальное распределение, U i ~ N (0,1).
, i = 1, 2, …, n
, являются независимыми СВ, имеющими стандартизированное нормальное распределение, U i ~ N (0,1).
СВ χ 2
имеет хи – квадрат распределение с n
степенями свободы (χ 2 ~ χ n 2), если  (20).
(20).
Отметим, что число степеней свободы (это число обозначается v ) исследуемой СВ определяется числом СВ, ее составляющих, уменьшенным на число линейных связей между ними.
Например, число степеней свободы СВ, являющейся композицией n случайных величин, которые в свою очередь связаны m линейными уравнениями, определяется числом v = m – n. Таким образом, U 2 ~ χ 1 2 .
Из определения (20) следует, что распределение χ 2 определяется одним параметром – числом степеней свободы v .
График плотности вероятности СВ, имеющий χ 2 – распределение, лежит только в первой четверти декартовой системы координат и имеет асимметричный вид с вытянутым правым «хвостом» (рис.3). Но с увеличением числа степеней свободы распределение χ 2 постепенно приближается к нормальному:

Рис. 3. График плотности вероятности СВ Х, имеюший χ 2 – распределение.
M (χ 2) = v = n – m,
D (χ 2) = 2 v = 2 (n – m).
Если Х и Y – две независимые χ 2 – распределенные СВ с числами степеней свободы n и k соответственно (Х ~ χ n 2 , Y ~ χ k 2), то их сумма (Х + Y) также является χ 2 – распределенной СВ с числом степеней свободы v = n + k.
Распределение χ 2 применяется для нахождения интервальных оценок и проверки статистических гипотез. При этом используется таблица критических точек χ 2 – распределения.
Если исследователь использовав методы, изложенные в предыдущем параграфе, убедился, что гипотеза нормальности распределения не может быть принята, то вполне может быть, что с помощью существующих методов удастся так преобразовать исходные данные, что их распределение будет подчиняться нормальному закону распределения. Для пояснения идеи преобразований рассмотрим качественный пример. Пусть кривая распределения f(x) имеет вид, представленный на рис. 3.7, т.е. имеется очень крутая левая ветвь и пологая правая. Такое распределение отличается от нормального.
Для
выполнения операций преобразования
каждое наблюдение трансформируется с
помощью логарифмического преобразования
При этом левая ветвь кривой распределения
сильно растягивается и распределение
принимает приближенно нормальный вид.
Если при преобразовании получаются
значения, расположенные между 0 и 1, то
все наблюдаемые значения для удобства
расчетов и во избежание получения
отрицательных параметров необходимо
умножить на 10 в соответствующей степени,
чтобы все вновь полученные, преобразованные
значения были больше единицы, т.е.
необходимо выполнить преобразования

Рис. 3 .7. Преобразование функции f(x) к нормальному распределению
Асимметричное
распределение с одной вершиной приводится
к нормальному преобразованием
 В отдельных случаях можно применять и
другие преобразования:
В отдельных случаях можно применять и
другие преобразования:
а)
обратная величина

б)
обратное значение квадратных корней

Преобразование "обратная величина" является наиболее "сильным". Среднее положение между логарифмическим преобразованием и "обратной величиной" занимает преобразование "обратное значение квадратных корней".
Для
нормализации смещенного вправо
распределения служат, например, степенные
преобразования
 При этом для a принимают значения: а=1,5
при умеренном и а=2 при сильно выраженном
правом смещении. Рекомендуем читателю
придумать такие преобразования, которые
удовлетворяли бы исследователя в том
или ином случае.
При этом для a принимают значения: а=1,5
при умеренном и а=2 при сильно выраженном
правом смещении. Рекомендуем читателю
придумать такие преобразования, которые
удовлетворяли бы исследователя в том
или ином случае.
а ограничено? Рассмотрим в дальнейшем методологию решения этой
4. Анализ результатов пассивного эксперимента. Эмпирические зависимости
4.1. Характеристика видов связей между рядами наблюдений
На
практике сама необходимость измерений
большинства величин вызывается тем,
что они не остаются постоянными, а
изменяются в функции от изменения других
величин. В этом случае целью проведения
эксперимента является установление
вида функциональной зависимости
 =f(X
).
Для этого должны одновременно определяться
как значенияX
, так и соответствующие
им значения
=f(X
).
Для этого должны одновременно определяться
как значенияX
, так и соответствующие
им значения ,
а задачей эксперимента является
установление математической модели
исследуемой зависимости. Фактически
речь идет об установлениисвязи
между двумя рядами наблюдений (измерений).
,
а задачей эксперимента является
установление математической модели
исследуемой зависимости. Фактически
речь идет об установлениисвязи
между двумя рядами наблюдений (измерений).
Определение связи включает в себя указание вида модели и определения ее параметров. В теории экспериментов независимые параметры X =(x 1 , ..., x n) принято называтьфакторами , а зависимые переменные y –откликами . Координатное пространство с координатами x 1 , x 2 , ..., x i , ..., x n называетсяфакторным пространством . Эксперимент по определению вида функции
 (4.1)
(4.1)
где x – скаляр, называется однофакторным . Эксперимент по определению функции вида
 =f(X
), (4.1а)
=f(X
), (4.1а)
где X =(x 1 , x 2 , ..., x i , ..., x k) – вектор, – многофакторным.
Геометрическое представление функции отклика в факторном пространстве является поверхностью отклика . При однофакторном эксперименте k=1 поверхность отклика представляет собой линию на плоскости, при двухфакторном k=2 – поверхность в трехмерном пространстве.
Связи в общем случае являются достаточно многообразными и сложными. Обычно выделяют следующие виды связей.
Функциональные связи (или зависимости). Это такие связи, когда при изменении величиныX другая величинаY изменяется так, что каждому значению x i соответствует совершенно определенное (однозначное) значение y i (рис.4.1а). Таким образом, если выбрать все условия эксперимента абсолютно одинаковыми, то повторяя испытания получим одну и ту же зависимость, т.е. кривые идеально совпадут для всех испытаний.
К сожалению, таких условий в реальности не встречается. На практике не удается поддерживать постоянство условий (например, колебания физико-химических свойств шихты при моделировании процессов тепломассопереноса в металлургических печах). При этом влияние каждого случайного фактора в отдельности может быть мало, однако в совокупности они существенно могут повлиять на результаты эксперимента. В этом случае говорят о стохастической (вероятностной) связи между переменными.

Рис.4.1. Виды связей: а – функциональная связь, все точки лежат на линии; б – связь достаточно тесная, точки группируются возле линии регрессии, но не все они лежат на ней; в – связь слабая
Стохастичность
связи
состоит в том, что одна
случайная переменнаяY
реагирует
на изменение другойX
изменением
своего закона распределения (см. рис.
4.1б). Таким образом, зависимая переменная
принимает не одно конкретное значение,
а некоторое из множества значений.
Повторяя испытания мы будем получать
другие значения функции отклика и одному
и тому же значению x в различных реализациях
будут соответствовать различные значения
y в интервале . Искомая
зависимость может быть найдена лишь в результате
совместной обработки полученных значений
x и y.
может быть найдена лишь в результате
совместной обработки полученных значений
x и y.
На
рис.4.1б эта кривая зависимости, проходящая
по центру полосы экспериментальных
точек (математическому ожиданию), которые
могут и не лежать на искомой кривой
 ,
а занимают некоторую полосу вокруг нее.
Эти отклонения вызваны погрешностями
измерений, неполнотой модели и учитываемых
факторов, случайным характером самих
исследуемых процессов и другими
причинами.
,
а занимают некоторую полосу вокруг нее.
Эти отклонения вызваны погрешностями
измерений, неполнотой модели и учитываемых
факторов, случайным характером самих
исследуемых процессов и другими
причинами.
При анализе стохастических связей можно выделить следующие основные типы зависимостей между переменными.
1.
Зависимости между одной случайной
переменной X
от другой случайной
переменнойY
и их условными средними
значениями называютсякорреляционными
.
Условное среднее i – это среднее арифметическое для
реализации случайной величиныY
при
условии, что случайная величинаX
принимает значение
i – это среднее арифметическое для
реализации случайной величиныY
при
условии, что случайная величинаX
принимает значение i .
i .
2. Зависимость случайной переменной Y от неслучайной переменнойX или зависимость математического ожидания M y случайной величиныY от детерминированного значенияX называетсярегрессионной . Приведенная зависимость характеризует влияние изменений величиныX на среднее значение величиныY .
Стохастические зависимости характеризуются формой, теснотой связи и численными значениями коэффициентов уравнения регрессии.
Форма
связи
устанавливает вид функциональной
зависимости =f(X
)
и характеризуетсяуравнением регрессии
.
Если уравнение связи линейное, то имеем
линейную многомерную регрессию, в этом
случае зависимостиY
отX
описываются уравнением прямой линии в
k-мерном пространстве
=f(X
)
и характеризуетсяуравнением регрессии
.
Если уравнение связи линейное, то имеем
линейную многомерную регрессию, в этом
случае зависимостиY
отX
описываются уравнением прямой линии в
k-мерном пространстве
 (4.2)
(4.2)
где
b 0 , ..., b j , ..., b k –
коэффициенты уравнения. Для пояснения
существа используемых методов ограничимся
сначала случаем, когда x скаляр. В общем
случае виды функциональных зависимостей
в технике достаточно многообразны:
показательные ,
логарифмические
,
логарифмические и т.д.
и т.д.
Заметим, что задача выбора вида функциональной зависимости – задача неформализуемая, т.к. одна и та же кривая на данном участке примерно с одинаковой точностью может быть описана самыми различными аналитическими выражениями. Отсюда следует важный практический вывод. Даже в наш век ПЭВМ принятие решения о выборе той или иной математической модели остается за исследователем. Только экспериментатор знает, для чего будет в дальнейшем использоваться эта модель, на основе каких понятий будут интерпретироваться ее параметры.
Крайне
желательно при обработке результатов
эксперимента вид функции
 =f(X)
выбирать исходя их условия соответствия
физической природе изучаемых явлений
или имеющимся представлениям об
особенностях поведения исследуемой
величины. К сожалению, такая возможность
не всегда имеется, так как эксперименты
чаще всего проводятся для исследования
недостаточно или неполно изученных
явлений.
=f(X)
выбирать исходя их условия соответствия
физической природе изучаемых явлений
или имеющимся представлениям об
особенностях поведения исследуемой
величины. К сожалению, такая возможность
не всегда имеется, так как эксперименты
чаще всего проводятся для исследования
недостаточно или неполно изученных
явлений.

Рис.4.2. Корреляционное поле
При изучения зависимости =f(X
)
от одного фактора при заранее неизвестном
виде функции отклика для приближенного
определения вида уравнения регрессии
полезно предварительно построить
эмпирическую линию регрессии (рис.4.2).
Для этого весь диапазон изменения x на
поле корреляции разбивают на равные
интервалыx. Все
точки, попавшие в данный интервалx j ,
относят к его середине
=f(X
)
от одного фактора при заранее неизвестном
виде функции отклика для приближенного
определения вида уравнения регрессии
полезно предварительно построить
эмпирическую линию регрессии (рис.4.2).
Для этого весь диапазон изменения x на
поле корреляции разбивают на равные
интервалыx. Все
точки, попавшие в данный интервалx j ,
относят к его середине .
Для этого подсчитывают частные средние
для каждого интервала
.
Для этого подсчитывают частные средние
для каждого интервала (4.3)
(4.3)
Здесь
n j – число точек в интервалеx j ,
причем ,
где k* – число интервалов разбиения, n –
объем выборки.
,
где k* – число интервалов разбиения, n –
объем выборки.
Затем
последовательно соединяют точки
 отрезками прямой. Полученная ломаная
называетсяэмпирической линией
регрессии
. По виду эмпирической линии
регрессии можно в первом приближении
подобрать вид уравнения регрессии
отрезками прямой. Полученная ломаная
называетсяэмпирической линией
регрессии
. По виду эмпирической линии
регрессии можно в первом приближении
подобрать вид уравнения регрессии =f(X
).
=f(X
).
Под теснотой связи понимается степень близости стохастической зависимости к функциональной, т.е. это показатель тесноты группирования экспериментальных данных относительно принятого уравнения модели (см. рис. 4.1б). В дальнейшем уточним это положение.
Нормальный закон распределения вероятностей
Без преувеличения его можно назвать философским законом. Наблюдая за различными объектами и процессами окружающего мира, мы часто сталкиваемся с тем, что чего-то бывает мало, и что бывает норма: 
Перед вами принципиальный вид функции плотности
нормального распределения вероятностей, и я приветствую вас на этом интереснейшем уроке.
Какие можно привести примеры? Их просто тьма. Это, например, рост, вес людей (и не только), их физическая сила, умственные способности и т.д. Существует «основная масса» (по тому или иному признаку) и существуют отклонения в обе стороны.
Это различные характеристики неодушевленных объектов (те же размеры, вес). Это случайная продолжительность процессов…, снова пришёл на ум грустный пример, и поэтому скажу время «жизни» лампочек:) Из физики вспомнились молекулы воздуха: среди них есть медленные, есть быстрые, но большинство двигаются со «стандартными» скоростями.
Далее отклоняемся от центра ещё на одно стандартное отклонение и рассчитываем высоту:
Отмечаем точки на чертеже (зелёный цвет) и видим, что этого вполне достаточно.
На завершающем этапе аккуратно чертим график, и особо аккуратно отражаем его выпуклость / вогнутость ! Ну и, наверное, вы давно поняли, что ось абсцисс – это горизонтальная асимптота , и «залезать» за неё категорически нельзя!
При электронном оформлении решения график легко построить в Экселе, и неожиданно для самого себя я даже записал короткий видеоролик на эту тему. Но сначала поговорим о том, как меняется форма нормальной кривой в зависимости от значений и .
При увеличении или уменьшении «а» (при неизменном «сигма»)
график сохраняет свою форму и перемещается вправо / влево
соответственно. Так, например, при функция принимает вид ![]() и наш график «переезжает» на 3 единицы влево – ровнехонько в начало координат:
и наш график «переезжает» на 3 единицы влево – ровнехонько в начало координат:
Нормально распределённая величина с нулевым математическим ожиданием получила вполне естественное название – центрированная
; её функция плотности  – чётная
, и график симметричен относительно оси ординат.
– чётная
, и график симметричен относительно оси ординат.
В случае изменения «сигмы» (при постоянном «а»)
, график «остаётся на месте», но меняет форму. При увеличении он становится более низким и вытянутым, словно осьминог, растягивающий щупальца. И, наоборот, при уменьшении график становится более узким и высоким
– получается «удивлённый осьминог». Так, при уменьшении
«сигмы» в два раза: предыдущий график сужается и вытягивается вверх в два раза:
Всё в полном соответствии с геометрическими преобразованиями графиков
.
Нормальное распределёние с единичным значением «сигма» называется нормированным
, а если оно ещё и центрировано
(наш случай), то такое распределение называют стандартным
. Оно имеет ещё более простую функцию плотности, которая уже встречалась в локальной теореме Лапласа
: ![]() . Стандартное распределение нашло широкое применение на практике, и очень скоро мы окончательно поймём его предназначение.
. Стандартное распределение нашло широкое применение на практике, и очень скоро мы окончательно поймём его предназначение.
Ну а теперь смотрим кино:
Да, совершенно верно – как-то незаслуженно у нас осталась в тени функция распределения вероятностей
. Вспоминаем её определение
:
– вероятность того, что случайная величина примет значение, МЕНЬШЕЕ, чем переменная , которая «пробегает» все действительные значения до «плюс» бесконечности.
Внутри интеграла обычно используют другую букву, чтобы не возникало «накладок» с обозначениями, ибо здесь каждому значению ставится в соответствие несобственный интеграл
 , который равен некоторому числу
из интервала .
, который равен некоторому числу
из интервала .
Почти все значения не поддаются точному расчету, но как мы только что видели, с современными вычислительными мощностями с этим нет никаких трудностей. Так, для функции  стандартного распределения соответствующая экселевская функция вообще содержит один аргумент:
стандартного распределения соответствующая экселевская функция вообще содержит один аргумент:
=НОРМСТРАСП(z)
Раз, два – и готово:
На чертеже хорошо видно выполнение всех свойств функции распределения
, и из технических нюансов здесь следует обратить внимание на горизонтальные асимптоты
и точку перегиба .
Теперь вспомним одну из ключевых задач темы, а именно выясним, как найти –вероятность того, что нормальная случайная величина примет значение из интервала
. Геометрически эта вероятность равна площади
между нормальной кривой и осью абсцисс на соответствующем участке:
но каждый раз вымучивать приближенное значение  неразумно, и поэтому здесь рациональнее использовать «лёгкую» формулу
:
неразумно, и поэтому здесь рациональнее использовать «лёгкую» формулу
:
.
! Вспоминает также , что
Тут можно снова задействовать Эксель, но есть пара весомых «но»: во-первых, он не всегда под рукой, а во-вторых, «готовые» значения , скорее всего, вызовут вопросы у преподавателя. Почему?
Об этом я неоднократно рассказывал ранее: в своё время (и ещё не очень давно) роскошью был обычный калькулятор, и в учебной литературе до сих пор сохранился «ручной» способ решения рассматриваемой задачи. Его суть состоит в том, чтобы стандартизировать
значения «альфа» и «бета», то есть свести решение к стандартному распределению:![]()
Примечание
: функцию легко получить из общего случая
 с помощью линейной замены
. Тогда и:
с помощью линейной замены
. Тогда и:
и из проведённой замены как раз следует формула ![]() перехода от значений произвольного распределения – к соответствующим значениям стандартного распределения.
перехода от значений произвольного распределения – к соответствующим значениям стандартного распределения.
Зачем это нужно? Дело в том, что значения скрупулезно подсчитаны нашими предками и сведены в специальную таблицу, которая есть во многих книгах по терверу. Но ещё чаще встречается таблица значений , с которой мы уже имели дело в интегральной теореме Лапласа
:
Если же в нашем распоряжении есть таблица значений функции Лапласа  , то решаем через неё:
, то решаем через неё:
Дробные значения традиционно округляем до 4 знаков после запятой, как это сделано в типовой таблице. И для контроля есть Пункт 5
макета
.
Напоминаю, что ![]() , и во избежание путаницы всегда контролируйте
, таблица КАКОЙ функции перед вашими глазами.
, и во избежание путаницы всегда контролируйте
, таблица КАКОЙ функции перед вашими глазами.
Ответ требуется дать в процентах, поэтому рассчитанную вероятность нужно умножить на 100 и снабдить результат содержательным комментарием:
– с перелётом от 5 до 70 м упадёт примерно 15,87% снарядов
Тренируемся самостоятельно:
Пример 3
Диаметр подшипников, изготовленных на заводе, представляет собой случайную величину, распределенную нормально с математическим ожиданием 1,5 см и средним квадратическим отклонением 0,04 см. Найти вероятность того, что размер наугад взятого подшипника колеблется от 1,4 до 1,6 см.
В образце решения и далее я буду использовать функцию Лапласа, как самый распространённый вариант. Кстати, обратите внимание, что согласно формулировке, здесь можно включить концы интервала в рассмотрение. Впрочем, это не критично.
И уже в этом примере нам встретился особый случай – когда интервал симметричен относительно математического ожидания. В такой ситуации его можно записать в виде и, пользуясь нечётностью функции Лапласа, упростить рабочую формулу:

Параметр «дельта» называют отклонением
от математического ожидания, и двойное неравенство можно «упаковывать» с помощью модуля
:
![]() – вероятность того, что значение случайной величины отклонится от математического ожидания менее чем на .
– вероятность того, что значение случайной величины отклонится от математического ожидания менее чем на .
Хорошо то решение, которое умещается в одну строчку:)
– вероятность того, что диаметр наугад взятого подшипника отличается от 1,5 см не более чем на 0,1 см.
Результат этой задачи получился близким к единице, но хотелось бы ещё бОльшей надежности – а именно, узнать границы, в которых находится диаметр почти всех подшипников. Существует ли какой-нибудь критерий на этот счёт? Существует! На поставленный вопрос отвечает так называемое
правило «трех сигм»
Его суть состоит в том, что практически достоверным
является тот факт, что нормально распределённая случайная величина примет значение из промежутка ![]() .
.
И в самом деле, вероятность отклонения от матожидания менее чем на составляет:
или 99,73%
В «пересчёте на подшипники» – это 9973 штуки с диаметром от 1,38 до 1,62 см и всего лишь 27 «некондиционных» экземпляров.
В практических исследованиях правило «трёх сигм» обычно применяют в обратном направлении: если статистически установлено, что почти все значения исследуемой случайной величины укладываются в интервал длиной 6 стандартных отклонений, то появляются веские основания полагать, что эта величина распределена по нормальному закону. Проверка осуществляется с помощью теории статистических гипотез , до которых я надеюсь рано или поздно добраться:)
Ну а пока продолжаем решать суровые советские задачи:
Пример 4
Случайная величина ошибки взвешивания распределена по нормальному закону с нулевым математическим ожиданием и стандартным отклонением 3 грамма. Найти вероятность того, что очередное взвешивание будет проведено с ошибкой, не превышающей по модулю 5 грамм.
Решение
очень простое. По условию, и сразу заметим, что при очередном взвешивании (чего-то или кого-то)
мы почти 100% получим результат с точностью до 9 грамм. Но в задаче фигурирует более узкое отклонение и по формуле ![]() :
:
![]() – вероятность того, что очередное взвешивание будет проведено с ошибкой, не превышающей 5 грамм.
– вероятность того, что очередное взвешивание будет проведено с ошибкой, не превышающей 5 грамм.
Ответ :
Прорешанная задача принципиально отличается от вроде бы похожего Примера 3 урока о равномерном распределении . Там была погрешность округления результатов измерений, здесь же речь идёт о случайной погрешности самих измерений. Такие погрешности возникают в связи с техническими характеристиками самого прибора (диапазон допустимых ошибок, как правило, указывают в его паспорте) , а также по вине экспериментатора – когда мы, например, «на глазок» снимаем показания со стрелки тех же весов.
Помимо прочих, существуют ещё так называемые систематические ошибки измерения. Это уже неслучайные ошибки, которые возникают по причине некорректной настройки или эксплуатации прибора. Так, например, неотрегулированные напольные весы могут стабильно «прибавлять» килограмм, а продавец систематически обвешивать покупателей. Или не систематически ведь можно обсчитать. Однако, в любом случае, случайной такая ошибка не будет, и её матожидание отлично от нуля.
…срочно разрабатываю курс по подготовке продавцов =)
Самостоятельно решаем обратную задачу:
Пример 5
Диаметр валика – случайная нормально распределенная случайная величина, среднее квадратическое отклонение ее равно мм. Найти длину интервала, симметричного относительно математического ожидания, в который с вероятностью попадет длина диаметра валика.
Пункт 5* расчётного макета в помощь. Обратите внимание, что здесь не известно математическое ожидание, но это нисколько не мешает решить поставленную задачу.
И экзаменационное задание, которое я настоятельно рекомендую для закрепления материала:
Пример 6
Нормально распределенная случайная величина задана своими параметрами (математическое ожидание) и (среднее квадратическое отклонение). Требуется:
а) записать плотность вероятности и схематически изобразить ее график;
б) найти вероятность того, что примет значение из интервала ![]() ;
;
в) найти вероятность того, что отклонится по модулю от не более чем на ;
г) применяя правило «трех сигм», найти значения случайной величины .
Такие задачи предлагаются повсеместно, и за годы практики мне их довелось решить сотни и сотни штук. Обязательно попрактикуйтесь в ручном построении чертежа и использовании бумажных таблиц;)
Ну а я разберу пример повышенной сложности:
Пример 7
Плотность распределения вероятностей случайной величины имеет вид ![]() . Найти , математическое ожидание , дисперсию , функцию распределения , построить графики плотности и функции распределения, найти .
. Найти , математическое ожидание , дисперсию , функцию распределения , построить графики плотности и функции распределения, найти .
Решение : прежде всего, обратим внимание, что в условии ничего не сказано о характере случайной величины. Само по себе присутствие экспоненты ещё ничего не значит: это может оказаться, например, показательное или вообще произвольное непрерывное распределение . И поэтому «нормальность» распределения ещё нужно обосновать:
Так как функция ![]() определена при любом
действительном значении , и её можно привести к виду
определена при любом
действительном значении , и её можно привести к виду  , то случайная величина распределена по нормальному закону.
, то случайная величина распределена по нормальному закону.
Приводим. Для этого выделяем полный квадрат
и организуем трёхэтажную дробь
:
Обязательно выполняем проверку, возвращая показатель в исходный вид:
, что мы и хотели увидеть.
Таким образом: – по правилу действий со степенями
«отщипываем» . И здесь можно сразу записать очевидные числовые характеристики:
– по правилу действий со степенями
«отщипываем» . И здесь можно сразу записать очевидные числовые характеристики:![]()
Теперь найдём значение параметра . Поскольку множитель нормального распределения имеет вид и , то: , откуда выражаем и подставляем в нашу функцию:
, откуда выражаем и подставляем в нашу функцию: , после чего ещё раз пробежимся по записи глазами и убедимся, что полученная функция имеет вид
, после чего ещё раз пробежимся по записи глазами и убедимся, что полученная функция имеет вид  .
.
Построим график плотности: 
и график функции распределения  :
:
Если под рукой нет Экселя и даже обычного калькулятора, то последний график легко строится вручную! В точке функция распределения принимает значение ![]() и здесь находится
и здесь находится


