Дозволяє визначити метод найменших квадратів. Апроксимація дослідних даних
Вибравши вид функції регресії, тобто. вид моделі залежності Y від Х (або Х від У), наприклад, лінійну модель y x =a+bx, необхідно визначити конкретні значеннякоефіцієнтів моделі
При різних значенняха та b можна побудувати нескінченне числозалежностей виду y x =a+bx тобто на координатної площиниє нескінченна кількість прямих, нам необхідна така залежність, яка відповідає спостеріганим значенням найкращим чином. Таким чином, завдання зводиться до підбору найкращих коефіцієнтів.
Лінійну функцію a+bx шукаємо, виходячи лише з деякої кількості спостережень. Для знаходження функції з найкращою відповідністю спостеріганим значенням використовуємо метод найменших квадратів.
Позначимо: Y i - значення, обчислене за рівнянням Y i = a + b x i. y i - виміряне значення, i =y i -Y i - різниця між виміряними і обчисленими за рівнянням значенням, i =y i -a-bx i .
У методі найменших квадратів потрібно, щоб ε i різниця між виміряними y i і обчисленими за рівнянням значенням Y i була мінімальною. Отже, знаходимо коефіцієнти а і b так, щоб сума квадратів відхилень значень, що спостерігаються від значень на прямій лінії регресії виявилася найменшою:
Досліджуючи на екстремум цю функцію аргументів та за допомогою похідних, можна довести, що функція приймає мінімальне значенняякщо коефіцієнти а і b є рішеннями системи:
 (2)
(2)
Якщо розділити обидві частини нормальних рівняньна n, то отримаємо:

Враховуючи що  (3)
(3)
Отримаємо  , Звідси , підставляючи значення a в перше рівняння, отримаємо:
, Звідси , підставляючи значення a в перше рівняння, отримаємо:

При цьому називають коефіцієнтом регресії; a називають вільним членом рівняння регресії та обчислюють за формулою:
Отримана пряма оцінка для теоретичної лінії регресії. Маємо:
Отже, ![]() є рівнянням лінійної регресії.
є рівнянням лінійної регресії.
Регресія може бути прямою (b>0) та зворотною (b Приклад 1. Результати вимірювання величин X та Y дано в таблиці:
| x i | -2 | 0 | 1 | 2 | 4 |
| y i | 0.5 | 1 | 1.5 | 2 | 3 |
Припускаючи, що між X і Y існує лінійна залежність y=a+bx способом найменших квадратів визначити коефіцієнти a і b.
Рішення. Тут n=5
x i = -2 +0 +1 +2 +4 = 5;
x i 2 =4+0+1+4+16=25
x i y i =-2 0.5+0 1+1 1.5+2 2+4 3=16.5
y i =0.5+1+1.5+2+3=8
і нормальна система(2) має вигляд ![]()
Вирішуючи цю систему, отримаємо: b = 0.425, a = 1.175. Тому y=1.175+0.425x.
Приклад 2. Є вибірка із 10 спостережень економічних показників(X) та (Y).
| x i | 180 | 172 | 173 | 169 | 175 | 170 | 179 | 170 | 167 | 174 |
| y i | 186 | 180 | 176 | 171 | 182 | 166 | 182 | 172 | 169 | 177 |
Потрібно визначити вибіркове рівняння регресії Y на X. Побудувати вибіркову лінію регресії Y на X.
Рішення. 1. Проведемо впорядкування даних за значеннями x i та y i . Отримуємо нову таблицю:
| x i | 167 | 169 | 170 | 170 | 172 | 173 | 174 | 175 | 179 | 180 |
| y i | 169 | 171 | 166 | 172 | 180 | 176 | 177 | 182 | 182 | 186 |
Для спрощення обчислень складемо розрахункову таблицю, до якої занесемо необхідні чисельні значення.
| x i | y i | x i 2 | x i y i |
| 167 | 169 | 27889 | 28223 |
| 169 | 171 | 28561 | 28899 |
| 170 | 166 | 28900 | 28220 |
| 170 | 172 | 28900 | 29240 |
| 172 | 180 | 29584 | 30960 |
| 173 | 176 | 29929 | 30448 |
| 174 | 177 | 30276 | 30798 |
| 175 | 182 | 30625 | 31850 |
| 179 | 182 | 32041 | 32578 |
| 180 | 186 | 32400 | 33480 |
| ∑x i =1729 | ∑y i =1761 | ∑x i 2 299105 | ∑x i y i =304696 |
| x = 172.9 | y=176.1 | x i 2 = 29910.5 | xy = 30469.6 |
Згідно з формулою (4), обчислюємо коефіцієнта регресії
а за формулою (5)
Таким чином, вибіркове рівняння регресії має вигляд y=-59.34+1.3804x.
Нанесемо на координатній площині точки (x i ; y i) і відзначимо пряму регресію.

Рис 4
На рис.4 видно, як розташовуються значення щодо лінії регресії. Для чисельної оцінки відхилень y від Y i , де y i спостерігаються, а Y i зумовлені регресією значення, складемо таблицю:
| x i | y i | Y i | Y i -y i |
| 167 | 169 | 168.055 | -0.945 |
| 169 | 171 | 170.778 | -0.222 |
| 170 | 166 | 172.140 | 6.140 |
| 170 | 172 | 172.140 | 0.140 |
| 172 | 180 | 174.863 | -5.137 |
| 173 | 176 | 176.225 | 0.225 |
| 174 | 177 | 177.587 | 0.587 |
| 175 | 182 | 178.949 | -3.051 |
| 179 | 182 | 184.395 | 2.395 |
| 180 | 186 | 185.757 | -0.243 |
Значення Y i обчислені відповідно до рівняння регресії.
Помітне відхилення деяких значень від лінії регресії пояснюється малим числом спостережень. При дослідженні ступеня лінійної залежності Y від X кількість спостережень враховується. Сила залежності визначається величиною коефіцієнта кореляції.
Метод найменших квадратів
Метод найменших квадратів ( МНК, OLS, Ordinary Least Squares) - один із базових методів регресійного аналізу для оцінки невідомих параметрів регресійних моделей за вибірковими даними. Метод ґрунтується на мінімізації суми квадратів залишків регресії.
Необхідно відзначити, що власне методом найменших квадратів можна назвати метод вирішення задачі в будь-якій області, якщо рішення полягає або задовольняє деякий критерій мінімізації суми квадратів деяких функцій від змінних, що шукаються. Тому метод найменших квадратів може застосовуватися також для наближеного уявлення (апроксимації) заданої функціїіншими (простішими) функціями, при знаходженні сукупності величин, що задовольняють рівнянь або обмежень, кількість яких перевищує кількість цих величин і т.д.
Сутність МНК
Нехай задана деяка (параметрична) модель імовірнісної (регресійної) залежності між (з'ясованою) змінною yі безліччю факторів (що пояснюють змінних) x
де - вектор невідомих параметрів моделі
- Випадкова помилка моделі.Нехай також є вибіркові спостереження значень вказаних змінних. Нехай – номер спостереження (). Тоді - значення змінних у спостереженні. Тоді при заданих значенняхпараметрів b можна розрахувати теоретичні (модельні) значення змінної, що пояснюється y:
Розмір залишків залежить від значень параметрів b.
Сутність МНК (звичайного, класичного) у тому, щоб знайти такі параметри b, у яких сума квадратів залишків (англ. Residual Sum of Squares) буде мінімальною:
У загальному випадкувирішення цього завдання може здійснюватися чисельними методамиоптимізації (мінімізації). У цьому випадку говорять про нелінійному МНК(NLS або NLLS – англ. Non-Linear Least Squares). У багатьох випадках можна отримати аналітичне рішення. Для вирішення задачі мінімізації необхідно знайти стаціонарні точки функції, продиференціювавши її за невідомими параметрами b, прирівнявши похідні до нуля і вирішивши отриману систему рівнянь:
Якщо випадкові помилки моделі мають нормальний розподіл , мають однакову дисперсію і некорельовані між собою, МНК оцінки параметрів збігаються з оцінками методу максимальної правдоподібності (ММП).
МНК у разі лінійної моделі
Нехай регресійна залежність є лінійною:
Нехай y- вектор-стовпець спостережень пояснюваної змінної, а - матриця спостережень факторів (рядки матриці - вектори значень факторів даному спостереженні, Стовпці - вектор значень даного фактора у всіх спостереженнях). Матричне уявлення лінійної моделі має вигляд:
Тоді вектор оцінок змінної, що пояснюється, і вектор залишків регресії дорівнюватимуть
відповідно сума квадратів залишків регресії дорівнюватиме
Диференціюючи цю функцію за вектором параметрів та прирівнявши похідні до нуля, отримаємо систему рівнянь (у матричній формі):
.Вирішення цієї системи рівнянь і дає загальну формулуМНК-оцінок для лінійної моделі:
Для аналітичних цілей виявляється корисним останнє уявлення цієї формули. Якщо у регресійній моделі дані центровані, то цьому поданні перша матриця має сенс вибіркової ковариационной матриці чинників, а друга - вектор ковариаций чинників із залежною змінною. Якщо дані ще й нормованіна СКО (тобто зрештою стандартизовано), то перша матриця має сенс вибіркової кореляційної матриці факторів, другий вектор - вектора вибіркових кореляцій факторів із залежною змінною.
Важлива властивість МНК-оцінок для моделей з константою- лінія побудованої регресії проходить через центр тяжкості вибіркових даних, тобто виконується рівність:
Зокрема, у крайньому випадку, Коли єдиним регресором є константа, отримуємо, що МНК-оцінка єдиного параметра (власне константи) дорівнює середньому значенню змінної, що пояснюється. Тобто середнє арифметичне, відоме своїми добрими властивостями із законів великих чисел, також є МНК-оцінкою – задовольняє критерію мінімуму суми квадратів відхилень від неї.
Приклад: найпростіша (парна) регресія
У разі парної лінійної регресії формули розрахунку спрощуються (можна обійтися без матричної алгебри):
Властивості МНК-оцінок
Насамперед, зазначимо, що для лінійних моделейМНК-оцінки є лінійними оцінками, як це випливає з вищенаведеної формули. Для незміщеності МНК-оцінок необхідне та достатньо виконання найважливішої умовирегресійного аналізу: умовне за факторами математичне очікування випадкової помилки має дорівнювати нулю. Ця умова, зокрема, виконано, якщо
- математичне очікуваннявипадкових помилок дорівнює нулю, і
- фактори та випадкові помилки - незалежні випадкові величини.
Друга умова - умова екзогенності факторів - важлива. Якщо ця властивість не виконано, то можна вважати, що практично будь-які оцінки будуть вкрай незадовільними: вони не будуть навіть заможними (тобто навіть дуже великий обсяг даних не дозволяє отримати якісні оцінкив цьому випадку). У класичному випадку робиться сильніша припущення про детермінованість факторів, на відміну від випадкової помилки, що автоматично означає виконання умови екзогенності. У випадку для спроможності оцінок досить виконання умови екзогенності разом із збіжністю матриці до деякої невиродженої матриці зі збільшенням обсягу вибірки до нескінченності.
Для того, щоб окрім спроможності та незміщеності, оцінки (звичайного) МНК були ще й ефективними (найкращими у класі лінійних незміщених оцінок) необхідно виконання додаткових властивостейвипадкової помилки:
Дані припущення можна сформулювати для коварійної матриці вектора випадкових помилок
Лінійна модель, що задовольняє такі умови, називається класичною. МНК-оцінки для класичної лінійної регресії є незміщеними, заможними та найбільш ефективними оцінками в класі всіх лінійних незміщених оцінок (в англомовній літературі іноді вживають абревіатуру BLUE (Best Linear Unbaised Estimator) - найкраща лінійна незміщена оцінка; в вітчизняної літературичастіше наводиться теорема Гауса – Маркова). Як неважко показати, ковариационная матриця вектора оцінок коефіцієнтів дорівнюватиме:
Узагальнений МНК
Метод найменших квадратів припускає широке узагальнення. Замість мінімізації суми квадратів залишків можна мінімізувати деяку позитивно визначену квадратичну форму від вектора залишків де - деяка симетрична позитивно визначена вагова матриця. Звичайний МНК є окремим випадком даного підходуколи вагова матриця пропорційна одиничній матриці. Як відомо з теорії симетричних матриць (або операторів) для таких матриць існує розкладання. Отже, зазначений функціонал можна уявити наступним чином , тобто цей функціонал можна як суму квадратів деяких перетворених «залишків». Отже, можна назвати клас методів найменших квадратів - LS-методи (Least Squares).
Доведено (теорема Айткена), що для узагальненої лінійної регресійної моделі (у якій на коварійну матрицю випадкових помилок не накладається жодних обмежень) найефективнішими (у класі лінійних незміщених оцінок) є оцінки т.з. узагальненого МНК (ОМНК, GLS - Generalized Least Squares)- LS-метода з ваговою матрицею, що дорівнює зворотній коварійній матриці випадкових помилок: .
Можна показати, що формула ОМНК оцінок параметрів лінійної моделі має вигляд
Коваріаційна матриця цих оцінок відповідно дорівнюватиме
Фактично сутність ОМНК полягає у певному (лінійному) перетворенні (P) вихідних даних та застосуванні звичайного МНК до перетворених даних. Ціль цього перетворення - для перетворених даних випадкові помилки вже задовольняють класичним припущенням.
Зважений МНК
У випадку діагональної вагової матриці (а значить і матриці коварійної випадкових помилок) маємо так званий зважений МНК (WLS - Weighted Least Squares). У даному випадкумінімізується зважена сума квадратів залишків моделі, тобто кожне спостереження отримує «вагу», обернено пропорційну дисперсії випадкової помилки в даному спостереженні: . Фактично дані перетворюються зважуванням спостережень (розподілом на величину, пропорційну передбачуваному стандартного відхиленнявипадкових помилок), а до виважених даних застосовується стандартний МНК.
Деякі окремі випадки застосування МНК на практиці
Апроксимація лінійної залежності
Розглянемо випадок, коли внаслідок вивчення залежності деякої скалярної величини від деякої скалярної величини(Це може бути, наприклад, залежність напруги від сили струму : , де - постійна величина, опір провідника) було проведено вимірювань цих величин, в результаті яких були отримані значення та відповідні їм значення . Дані вимірювань мають бути записані у таблиці.
Таблиця. Результати вимірів.
| № виміру | ||
|---|---|---|
| 1 | ||
| 2 | ||
| 3 | ||
| 4 | ||
| 5 | ||
| 6 |
Питання звучить так: яке значення коефіцієнта можна підібрати, щоб якнайкраще описати залежність? Згідно з МНК це значення має бути таким, щоб сума квадратів відхилень величин від величин
була мінімальною
Сума квадратів відхилень має один екстремум – мінімум, що дозволяє нам використовувати цю формулу. Знайдемо з цієї формули значення коефіцієнта. Для цього перетворюємо її ліву частинунаступним чином:
Остання формула дозволяє знайти значення коефіцієнта , що й потрібно завдання.
Історія
До початку XIXв. вчені не мали певних правилдля розв'язання системи рівнянь , у якій число невідомих менше, ніж число рівнянь; до цього часу використовувалися приватні прийоми, що залежали від виду рівнянь і від дотепності обчислювачів, і тому різні обчислювачі, виходячи з тих самих даних спостережень, приходили до різних висновків. Гаусс (1795) належить перше застосування методу, а Лежандр (1805) незалежно відкрив і опублікував його під сучасною назвою(Фр. Méthode des moindres quarrés ). Лаплас пов'язав метод з теорією ймовірностей, а американський математик Едрейн (1808) розглянув його теоретико-імовірнісні додатки. Метод поширений і вдосконалений подальшими дослідженнями Енке, Бесселя, Ганзена та інших.
Альтернативне використання МНК
Ідея методу найменших квадратів може бути використана також в інших випадках, які не пов'язані безпосередньо з регресійним аналізом. Справа в тому, що сума квадратів є одним із найпоширеніших заходів близькості для векторів (евклідова метрика в кінцевомірних просторах).
Одне із застосувань – «вирішення» систем лінійних рівнянь, у яких число рівнянь більше числазмінних
де матриця не квадратна, а прямокутна розміру.
Така система рівнянь, у випадку немає рішення (якщо ранг насправді більше числа змінних). Тому цю систему можна «вирішити» тільки в сенсі вибору такого вектора, щоб мінімізувати «відстань» між векторами та . Для цього можна застосувати критерій мінімізації суми квадратів різниць лівої та правої частинрівнянь системи, тобто . Неважко показати, що вирішення цього завдання мінімізації призводить до вирішення наступної системи рівнянь
приклад.
Експериментальні дані про значення змінних хі унаведено у таблиці. 
В результаті їх вирівнювання отримано функцію ![]()
Використовуючи метод найменших квадратів, апроксимувати ці дані лінійною залежністю y=ax+b(Знайти параметри аі b). З'ясувати, яка з двох ліній краще (у сенсі способу менших квадратів) вирівнює експериментальні дані. Зробити креслення.
Суть методу найменших квадратів (МНК).
Завдання полягає у знаходженні коефіцієнтів лінійної залежності, при яких функція двох змінних аі b ![]() приймає наї менше значення. Тобто, за даними аі bсума квадратів відхилень експериментальних даних від знайденої прямої буде найменшою. У цьому суть методу найменших квадратів.
приймає наї менше значення. Тобто, за даними аі bсума квадратів відхилень експериментальних даних від знайденої прямої буде найменшою. У цьому суть методу найменших квадратів.
Таким чином, рішення прикладу зводиться до знаходження екстремуму функції двох змінних.
Висновок формул знаходження коефіцієнтів.
Складається та вирішується система із двох рівнянь із двома невідомими. Знаходимо приватні похідні функції змінних аі b, Прирівнюємо ці похідні до нуля. 
Вирішуємо отриману систему рівнянь будь-яким методом (наприклад методом підстановкиабо ) і отримуємо формули для знаходження коефіцієнтів методом найменших квадратів (МНК). 
За даними аі bфункція ![]() набуває найменшого значення. Доказ цього факту наведено.
набуває найменшого значення. Доказ цього факту наведено.
Ось і весь спосіб найменших квадратів. Формула для знаходження параметра aмістить суми , , , та параметр n- Кількість експериментальних даних. Значення цих сум рекомендуємо обчислювати окремо. Коефіцієнт bзнаходиться після обчислення a.
Настав час згадати про вихідний приклад.
Рішення.
У нашому прикладі n=5. Заповнюємо таблицю для зручності обчислення сум, що входять до формул шуканих коефіцієнтів. 
Значення у четвертому рядку таблиці отримані множенням значень 2-го рядка на значення 3-го рядка для кожного номера i.
Значення у п'ятому рядку таблиці отримані зведенням у квадрат значень другого рядка для кожного номера i.
Значення останнього стовпця таблиці – це суми значень рядків.
Використовуємо формули методу найменших квадратів для знаходження коефіцієнтів аі b. Підставляємо у них відповідні значення з останнього стовпця таблиці: 
Отже, y = 0.165x+2.184- пряма апроксимуюча.
Залишилося з'ясувати, яка з ліній y = 0.165x+2.184або ![]() краще апроксимує вихідні дані, тобто провести оцінку шляхом найменших квадратів.
краще апроксимує вихідні дані, тобто провести оцінку шляхом найменших квадратів.
Оцінка похибки способу менших квадратів.
Для цього потрібно обчислити суми квадратів відхилень вихідних даних від цих ліній ![]() і
і ![]() менше значення відповідає лінії, яка краще в сенсі методу найменших квадратів апроксимує вихідні дані.
менше значення відповідає лінії, яка краще в сенсі методу найменших квадратів апроксимує вихідні дані. 
Оскільки , то пряма y = 0.165x+2.184краще наближає вихідні дані.
Графічна ілюстрація методу найменших квадратів (МНК).
На графіках все чудово видно. Червона лінія – це знайдена пряма y = 0.165x+2.184, синя лінія – це ![]() , Рожеві точки - це вихідні дані.
, Рожеві точки - це вихідні дані.

Навіщо це потрібно, до чого всі ці апроксимації?
Я особисто використовую для вирішення завдань згладжування даних, задач інтерполяції та екстраполяції (у вихідному прикладі могли б попросити знайти значення спостережуваної величини yпри x=3або при x=6методом МНК). Але докладніше поговоримо про це пізніше в іншому розділі сайту.
Доказ.
Щоб при знайдених аі bфункція приймала найменше значення, необхідно, щоб у цій точці матриця квадратичної форми диференціала другого порядку для функції ![]() була позитивно визначеною. Покажемо це.
була позитивно визначеною. Покажемо це.
Одним із методів вивчення стохастичних зв'язків між ознаками є регресійний аналіз.
Регресійний аналізє висновок рівняння регресії, за допомогою якого знаходиться середня величинавипадкової змінної (ознака-результату), якщо величина іншої (або інших) змінних (ознак-факторів) відома. Він включає такі етапи:
- вибір форми зв'язку (виду аналітичного рівняння регресії);
- оцінку параметрів рівняння;
- оцінку якості аналітичного рівняння регресії
У разі лінійного парного зв'язку рівняння регресії набуде вигляду: y i =a+b·x i +u i . Параметри даного рівнянняа та b оцінюються за даними статистичного спостереження x та y . Результатом такої оцінки є рівняння: , де - оцінки параметрів a і b - значення результативної ознаки (змінної), отримане за рівнянням регресії (розрахункове значення).
Найчастіше для оцінки параметрів використовують Метод найменших квадратів (МНК).
Метод найменших квадратів дає найкращі (заможні, ефективні та незміщені) оцінки параметрів рівняння регресії. Але тільки в тому випадку, якщо виконуються певні передумови щодо випадкового члена (u) та незалежної змінної (x) (див. передумови МНК).
Завдання оцінювання параметрів лінійного парного рівняння методом найменших квадратівполягає в наступному: отримати такі оцінки параметрів , при яких сума квадратів відхилень фактичних значень результативної ознаки - y i від розрахункових значень - мінімальна.
Формально критерій МНКможна записати так:  .
.
Класифікація методів найменших квадратів
- Метод найменших квадратів.
- Метод максимальної правдоподібності(Для нормальної класичної лінійної моделі регресії постулюється нормальність регресійних залишків).
- Узагальнений метод найменших квадратів ОМНК застосовується у разі автокореляції помилок та у разі гетероскедастичності.
- Метод зважених найменших квадратів ( окремий випадокОМНК із гетероскедастичними залишками).
Проілюструємо суть класичного методунайменших квадратів графічно. Для цього збудуємо точковий графікза даними спостережень (x i , y i , i = 1; n) прямокутної системикоординат (такий точковий графік називають кореляційним полем). Спробуємо підібрати пряму лінію, яка найближче розташована до точок кореляційного поля. Відповідно до методу найменших квадратів лінія вибирається так, щоб сума квадратів відстаней по вертикалі між точками кореляційного поля та цією лінією була б мінімальною. 
Математичний запис даної задачі:  .
.
Значення y i x i =1...n нам відомі, це дані спостережень. У функції S вони є константи. Змінними у цій функції є оцінки параметрів - , . Щоб визначити мінімум функції двох змінних потрібно обчислити приватні похідні цієї функції у кожному з властивостей і прирівняти їх нулю, тобто. 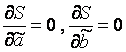 .
.
В результаті отримаємо систему з двох нормальних лінійних рівнянь: 
Вирішуючи цю системузнайдемо шукані оцінки параметрів: 
Правильність розрахунку параметрів рівняння регресії може бути перевірена порівнянням сум (можлива деяка розбіжність через заокруглення розрахунків).
Для розрахунку оцінок параметрів можна побудувати таблицю 1.
Знак коефіцієнта регресії b вказує напрямок зв'язку (якщо b >0, зв'язок прямий, якщо b<0, то связь обратная). Величина b показывает на сколько единиц изменится в среднем признак-результат -y при изменении признака-фактора - х на 1 единицу своего измерения.
Формально значення параметра - середнє значення y при х рівному нулю. Якщо ознака-фактор немає і може мати нульового значення, то вищевказане трактування параметра немає сенсу.
Оцінка тісноти зв'язку між ознаками
здійснюється за допомогою коефіцієнта лінійної парної кореляції - r x, y. Він може бути розрахований за формулою:  . Крім того, коефіцієнт лінійної парної кореляції може бути визначений через коефіцієнт регресії b:
. Крім того, коефіцієнт лінійної парної кореляції може бути визначений через коефіцієнт регресії b:  .
.
Область допустимих значень лінійного коефіцієнта парної кореляції від -1 до +1. Знак коефіцієнта кореляції вказує напрямок зв'язку. Якщо r x, y >0, то зв'язок прямий; якщо r x, y<0, то связь обратная.
Якщо цей коефіцієнт по модулю близький до одиниці, то зв'язок між ознаками може бути інтерпретований як досить тісний лінійний. Якщо його модуль дорівнює одиниці r x , y = 1, то зв'язок між ознаками функціональна лінійна. Якщо ознаки х і y лінійно незалежні, то r x y близький до 0.
Для розрахунку r x, y можна також використовувати таблицю 1.
Таблиця 1
| N спостереження | x i | y i | x i ∙y i | ||
| 1 | x 1 | y 1 | x 1 · y 1 | ||
| 2 | x 2 | y 2 | x 2 · y 2 | ||
| ... | |||||
| n | x n | y n | x n ·y n | ||
| Сума по стовпцю | ∑x | ∑y | ∑x·y | ||
| Середнє значення |
|
|
 ,
,
де d 2 - Пояснена рівнянням регресії дисперсія y;
e 2 - залишкова (непояснена рівнянням регресії) дисперсія y;
s 2 y - загальна (повна) дисперсія y.
Коефіцієнт детермінації характеризує частку варіації (дисперсії) результативної ознаки y, що пояснюється регресією (а, отже, і фактором х), у загальній варіації (дисперсії) y. Коефіцієнт детермінації R 2 yx набуває значення від 0 до 1. Відповідно величина 1-R 2 yx характеризує частку дисперсії y , викликану впливом інших неврахованих у моделі факторів та помилками специфікації.
При парній лінійній регресії R 2 yx = r 2 yx.
- Tutorial
Вступ
Я математик-програміст. Найбільший стрибок у своїй кар'єрі я зробив, коли навчився говорити: "Я нічого не розумію!"Зараз мені не соромно сказати світилу науки, що читає лекцію, що я не розумію, про що воно, світило, мені говорить. І це дуже складно. Так, зізнатися у своєму незнанні складно та соромно. Кому сподобається визнаватись у тому, що він не знає азів чогось там. Через свою професію я повинен бути присутнім на великій кількості презентацій та лекцій, де, зізнаюся, в переважній більшості випадків мені хочеться спати, бо я нічого не розумію. А я не розумію тому, що величезна проблема поточної ситуації в науці криється в математиці. Вона припускає, що всі слухачі знайомі з усіма областями математики (що абсурдно). Зізнатися в тому, що ви не знаєте, що таке похідна (про те, що це трохи пізніше) - соромно.
Але я навчився говорити, що не знаю, що таке множення. Так, я не знаю, що таке подалгебра над алгеброю Лі. Так, я не знаю, навіщо потрібні у житті квадратні рівняння. До речі, якщо ви впевнені, що ви знаєте, то нам є над чим поговорити! Математика – це серія фокусів. Математики намагаються заплутати та залякати публіку; там, де немає збентеження, немає репутації, немає авторитету. Так, це престижно говорити якомога абстрактнішою мовою, що є по собі повна нісенітниця.
Чи знаєте ви, що таке похідна? Найімовірніше ви мені скажете про межу різницевого відношення. На першому курсі матуху СПбГУ Віктор Петрович Хавін мені визначивпохідну як коефіцієнт першого члена ряду Тейлора функції у точці (це була окрема гімнастика, щоб визначити ряд Тейлора без похідних). Я довго сміявся над таким визначенням, поки не зрозумів, про що воно. Похідна не що інше, як просто міра того, наскільки функція, яку ми диференціюємо, схожа на функцію y=x, y=x^2, y=x^3.
Я зараз маю честь читати лекції студентам, які боятьсяматематики. Якщо ви боїтеся математики – нам з вами по дорозі. Як тільки ви намагаєтеся прочитати якийсь текст, і вам здається, що він надмірно складний, то знайте, що він написано хронічно. Я стверджую, що немає жодної галузі математики, про яку не можна говорити «на пальцях», не втрачаючи при цьому точності.
Завдання найближчим часом: я доручив своїм студентам зрозуміти, що таке лінійно-квадратичний регулятор. Не посоромтеся, витратите три хвилини свого життя, сходіть на заслання. Якщо ви нічого не зрозуміли, то нам з вами по дорозі. Я (професійний математик-програміст) також нічого не зрозумів. І я запевняю, що в цьому можна розібратися «на пальцях». На даний момент я не знаю, що це таке, але я запевняю, що ми зможемо розібратися.
Отже, перша лекція, яку я збираюся прочитати своїм студентам після того, як вони з жахом вдадуться до мене зі словами, що лінійно-квадратичний регулятор - це страшна бяка, яку ніколи в житті не подужати, це методи найменших квадратів. Чи вмієте ви розв'язувати лінійні рівняння? Якщо ви читаєте цей текст, то, швидше за все, ні.
Отже, дано дві точки (x0, y0), (x1, y1), наприклад, (1,1) і (3,2), завдання знайти рівняння прямої, що проходить через ці дві точки:
ілюстрація

Ця пряма повинна мати рівняння наступного типу:
Тут альфа і бета нам невідомі, але відомі дві точки цієї прямої:
Можна записати це рівняння у матричному вигляді:
Тут слід створити ліричний відступ: що таке матриця? Матриця це не що інше, як двовимірний масив. Це спосіб зберігання даних, більше ніяких значень йому не варто надавати. Це залежить від нас, як саме інтерпретувати якусь матрицю. Періодично я її інтерпретуватиму як лінійне відображення, періодично як квадратичну форму, а ще іноді просто як набір векторів. Це все буде уточнено у контексті.
Давайте замінимо конкретні матриці на їхнє символьне уявлення:
Тоді (alpha, beta) може бути легко знайдено:
Більш конкретно для наших попередніх даних:
Що веде до наступного рівняння прямої, що проходить через точки (1,1) та (3,2):
Окей, тут зрозуміло. А давайте знайдемо рівняння прямої, що проходить через триточки: (x0, y0), (x1, y1) та (x2, y2):
Ой-ой-ой, але ж у нас три рівняння на дві невідомі! Стандартний математик скаже, що рішення немає. А що скаже програміст? А він спершу перепише попередню систему рівнянь у наступному вигляді:
У нашому випадку вектори i,j,b тривимірні, отже, (загалом) рішення цієї системи немає. Будь-який вектор (alpha i i beta i j) лежить у площині, натягнутій на вектори (i, j). Якщо b не належить цій площині, то рішення немає (рівності у рівнянні не досягти). Що робити? Давайте шукати компроміс. Давайте позначимо через e(alpha, beta)наскільки саме ми не досягли рівності:
І намагатимемося мінімізувати цю помилку:
Чому квадрат?
Ми шукаємо не просто мінімум норми, а мінімум квадрата норми. Чому? Сама точка мінімуму збігається, а квадрат дає гладку функцію (квадратичну функцію від агрументів (alpha, beta)), тоді як просто довжина дає функцію як конуса, недиференційовану в точці мінімуму. Брр. Квадрат зручніший.
Очевидно, що помилка мінімізується, коли вектор eортогональний площині, натягнутій на вектори. iі j.
Ілюстрація

Іншими словами: ми шукаємо таку пряму, що сума квадратів довжин відстаней від усіх точок до цієї прямої мінімальна:
UPDATE: тут у мене одвірок, відстань до прямої має вимірюватися по вертикалі, а не ортогональною проекцією. коментатор прав.
Ілюстрація

Зовсім іншими словами (обережно, погано формалізовано, але на пальцях має бути ясно): ми беремо всі можливі прямі між усіма парами точок і шукаємо середню пряму між усіма:
Ілюстрація

Інше пояснення на пальцях: ми прикріплюємо пружинку між усіма точками даних (тут у нас три) і пряме, що ми шукаємо, і пряма рівноважного стану є саме те, що ми шукаємо.
Мінімум квадратичної форми
Отже, маючи цей вектор bта площину, натягнуту на стовпці-вектори матриці A(в даному випадку (x0,x1,x2) та (1,1,1)), ми шукаємо вектор eз мінімуму квадрата довжини. Очевидно, що мінімум можна досягти тільки для вектора. e, ортогональної площини, натягнутої на стовпці-вектори матриці. A:Інакше кажучи, ми шукаємо такий вектор x=(alpha, beta), що:
Нагадую, цей вектор x=(alpha, beta) є мінімумом квадратичної функції ||e(alpha, beta)||^2:
Тут не зайвим буде згадати, що матрицю можна інтерпретувати у тому числі як і квадратичну форму, наприклад, одинична матриця ((1,0),(0,1)) може бути інтерпретована як функція x^2 + y^2:
квадратична форма

Вся ця гімнастика відома під ім'ям лінійної регресії.
Рівняння Лапласа з граничною умовою Діріхле
Тепер найпростіше реальне завдання: є якась тріангульована поверхня, необхідно її згладити. Наприклад, давайте завантажимо модель моєї особи:
Початковий коміт доступний. Для мінімізації зовнішніх залежностей я взяв код свого софтверного рендерера вже на хабрі. Для вирішення лінійної системи я користуюся OpenNL, це відмінний солвер, який, щоправда, дуже складно встановити: потрібно скопіювати два файли (.h+.c) у папку з вашим проектом. Все згладжування робиться наступним кодом:
For (int d=0; d<3; d++) {
nlNewContext();
nlSolverParameteri(NL_NB_VARIABLES, verts.size());
nlSolverParameteri(NL_LEAST_SQUARES, NL_TRUE);
nlBegin(NL_SYSTEM);
nlBegin(NL_MATRIX);
for (int i=0; i<(int)verts.size(); i++) {
nlBegin(NL_ROW);
nlCoefficient(i, 1);
nlRightHandSide(verts[i][d]);
nlEnd(NL_ROW);
}
for (unsigned int i=0; i
X, Y та Z координати відокремлені, я їх згладжую окремо. Тобто, я вирішую три системи лінійних рівнянь, кожне має кількість змінних рівною кількістю вершин у моїй моделі. Перші n рядків матриці A мають лише одну одиницю на рядок, а перші n рядків вектора b мають оригінальні координати моделі. Тобто, я прив'язую по пружинці між новим становищем вершини і старим становищем вершини - нові не повинні занадто далеко йти від старих.
Всі наступні рядки матриці A (faces.size()*3 = кількості ребер всіх трикутників у сітці) мають одне входження 1 та одне входження -1, причому вектор b має нульові компоненти навпаки. Це означає, що я вішаю пружинку на кожне ребро нашої трикутної сітки: всі ребра намагаються отримати одну й ту саму вершину як відправну та фінальну точку.
Ще раз: змінними є всі вершини, причому вони можуть далеко відходити від початкового становища, але заодно намагаються стати схожими друг на друга.
Ось результат:

Все було б добре, модель дійсно згладжена, але вона відійшла від свого початкового краю. Давайте трохи змінимо код:
For (int i=0; i<(int)verts.size(); i++) { float scale = border[i] ? 1000: 1; nlBegin(NL_ROW); nlCoefficient(i, scale); nlRightHandSide(scale*verts[i][d]); nlEnd(NL_ROW); }
У нашій матриці A я для вершин, що знаходяться на краю, не додаю рядок з розряду v_i = verts[i][d], а 1000*v_i = 1000*verts[i][d]. Що це змінює? А змінює це нашу квадратичну форму помилки. Тепер одиничне відхилення від вершини краю коштуватиме не одну одиницю, як раніше, а 1000*1000 одиниць. Тобто, ми повісили сильнішу пружинку на крайні вершини, рішення воліє розтягнути інші. Ось результат:

Давайте вдвічі посилимо пружинки між вершинами:
nlCoefficient (face [j], 2); nlCoefficient(face[(j+1)%3], -2);
Логічно, що поверхня стала гладкішою:

А тепер ще в сто разів сильніше:

Що це? Уявіть, що ми вмочили дротяне кільце в мильну воду. У результаті мильна плівка, що утворилася, намагатиметься мати найменшу кривизну, наскільки це можливо, торкаючись-таки кордону - нашого дротяного кільця. Саме це ми й отримали, зафіксувавши кордон та попросивши отримати гладку поверхню всередині. Вітаю вас, ми тільки-но вирішили рівняння Лапласа з граничними умовами Діріхле. Круто звучить? А насправді лише одну систему лінійних рівнянь вирішити.
Рівняння Пуассона
Давайте ще круте ім'я згадаємо.Припустимо, що у мене є така картинка:

Всім гарна, тільки стілець мені не подобається.
Розріжу картинку навпіл: 

І виділю руками стілець: 
Потім все, що біле в масці, притягну до лівої частини картинки, а заразом по всій картинці скажу, що різниця між двома сусідніми пікселями повинна дорівнювати різниці між двома сусідніми пікселями правої картинки:
For (int i=0; i Ось результат: Код та зображення доступні


