Математика та інформатика. Навчальний посібник з усього курсу
Функція розподілу в цьому випадку згідно (5.7), набуде вигляду:
де: m - математичне очікування, s-середньо квадратичне відхилення.
Нормальний розподіл називають ще гауссівським на ім'я німецького математика Гаусса. Той факт, що випадкова величинамає нормальне розподілення з параметрами: m, позначають так: N (m,s), де: m =a =M ;
Досить часто у формулах математичне очікування позначають через а . Якщо випадкова величина розподілена згідно із законом N(0,1), то вона називається нормованою або стандартизованою нормальною величиною. Функція розподілу для неї має вигляд:
|
|
 .
.Графік густини нормального розподілу, який називають нормальною кривою або кривою Гауса, зображений на рис.5.4.

Мал. 5.4. Щільність нормального розподілу
Визначення числових показників випадкової величини з її щільності розглядається з прикладу.
Приклад 6.
Безперервна випадкова величина задана щільністю розподілу: ![]() .
.
Визначити вид розподілу, знайти математичне очікування M(X) та дисперсію D(X).
Порівнюючи задану щільністьрозподілу з (5.16) можна дійти невтішного висновку, що заданий нормальний закон розподілу з m =4. Отже, математичне очікування M(X)=4, дисперсія D(X)=9.
Середнє квадратичне відхилення s=3.
Функція Лапласа, що має вигляд:
|
|
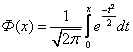 ,
,пов'язана з функцією нормального розподілу (5.17), співвідношенням:
F0(x) = Ф(х) + 0,5.
Функції Лапласа непарна.
Ф(-x) = -Ф(x).
Значення функції Лапласа Ф(х) табульовані та беруться з таблиці за значенням х (див. Додаток 1).
Нормальний розподіл безперервної випадкової величини грає важливу рольв теорії ймовірностей і при описі реальності, має дуже широке розповсюдженняу випадкових явищах природи. На практиці дуже часто зустрічаються випадкові величини, що утворюються саме в результаті підсумовування багатьох випадкових доданків. Зокрема, аналіз помилок виміру показує, що вони є сумою різного родупомилок. Практика показує, що розподіл ймовірностей помилок виміру близький до нормального закону.
За допомогою функції Лапласа можна вирішувати завдання обчислення ймовірності попадання в заданий інтервал та заданого відхилення нормальної випадкової величини.
Закони розподілу випадкових величин.
Більшість СВ підпорядковується певному закону розподілу, знаючи який можна передбачати ймовірність попадання досліджуваної СВ певні інтервали. Це дуже важливо під час аналізу економічних показників, т.к. у цьому випадку з'являється можливість здійснювати продуману політику з урахуванням можливості виникнення тієї чи іншої ситуації.
Законів розподілів досить багато. До найбільш активно використовуються в економетричному аналізі відносяться:
Нормальний розподіл (розподіл Гауса);
Розподіл χ 2;
Розподіл Стьюдента;
Розподіл Фішера.
Для зручності використання цих законів було розроблено таблиці критичних точок, які дозволяють швидко та ефективно оцінювати відповідні ймовірності.
Нормальний розподіл (розподіл Гауса) є граничним випадком багатьох реальних розподілів ймовірності. Тому воно використовується в дуже великому числіреальні програми теорії ймовірностей.
СВ Хмає нормальний розподіл, якщо її щільність ймовірності має вигляд:
 (14)
(14)
Це рівнозначно тому, що
 (15)
(15)
СВ, що має нормальний розподіл, називається нормально розподіленою або нормальною. Графіки щільності ймовірності та функції розподілу нормальної СВ зображені на рис.1 та 2.

0 m – σ m m + σ x
Рис.1. Графік густини ймовірності нормального розподілу СВ Х.

Рис.2. Функція розподілу нормальної СВ.
Як видно з формул (1) та (2), нормальний розподіл залежить від параметрів m та σта повністю визначається ними. При цьому m = M(X),
σ = σ (Х),тобто. D (X) = σ 2 , π = 3,14159 ..., e = 2,71828 ....
Якщо СВ Хмає нормальний розподіл із параметрами M(X) = mі
σ (Х) = σ, то символічно це можна записати так:
Х ~ N (m, σ) або Х ~ N (m, σ 2).
Дуже важливим окремим випадком нормального розподілу є ситуація, коли m = 0і σ = 1. У цьому випадку говорять про стандартизованому (стандартному) нормальному розподілі.
Стандартизовану нормальну СВ позначають через U (U ~ N (0,1)),враховуючи при цьому, що
 ;
;  (16)
(16)
Для практичних розрахунківспеціально розроблені таблиці функцій
f(u), F(u)стандартизованого нормального розподілу, але найчастіше використовується так звана таблиця значень Лапласа Ф (
u).
Функція Лапласа має вигляд:
 (17)
(17)
Цю таблицю можна використовувати для будь-якої нормальної СВ
Х (Х ~ N (m, σ))при розрахунку відповідних ймовірностей:
Зауважимо, що якщо Х ~ N (m, σ),то  ~ N(0,1).
~ N(0,1).
Як видно з попередніх малюнків, нормально розподілена СВ Хведе себе досить передбачувано. Графік її густини ймовірності (рис.1) симетричний щодо прямої Х = m. Площа фігури під графіком щільності ймовірності має залишатися рівної одиниціза будь-яких значень m та σ.Отже, чим менше значення σ , тим паче крутим є графік.
Крім того, справедливі такі співвідношення:
Р ( Х – M (Х) < σ) = 0,68; Р ( Х – M (Х) < 2σ) = 0,95;
Р ( Х – M (Х) < 3σ) = 0,9973 .
Іншими словами, значення нормально розподіленої СВ
Х (Х ~ N (m, σ))на 99,73% зосереджено в області [m - 3?, m + 3?].
Важливим є той факт, що лінійна комбінація довільної кількості нормальних СВ має нормальний розподіл. При цьому, якщо Х ~ N (m х, σ х) та Y ~ N (m y , σ y)- незалежні СВ, то
Z = aX + bY ~ N (m z , σ), (19)
де m z = a m х + b m y; σ z 2 = a 2 σ x 2 + b 2 σ y 2.
Багато економічні показникимають нормальний чи близький до нормального закону розподілу. Наприклад, доход населення, прибуток фірм у галузі, обсяг споживання тощо. мають близький до нормального розподілу.
Нормальний розподіл використовується під час перевірки різних гіпотезу статистиці (про величину математичного очікування при відомої дисперсії, про рівність математичних очікувань тощо).
Часто під час моделювання економічних процесівдоводиться розглядати СВ, які є алгебраїчну комбінацію декількох СВ. Істотну рольу цьому грає ряд спеціально розроблених теоретичних законіврозподілів. До них відносяться χ 2- розподіл, розподіл Стьюдента і Фішера.
Розподіл χ 2 (хі – квадрат)
Нехай Х i , i = 1, 2, …, n- незалежні нормально розподілені СВ з математичними очікуваннями m iта середніми квадратичними відхиленнями σ iвідповідно, тобто. Х i ~ N (m i , i).
Тоді СВ  , i = 1, 2, …, n, є незалежними СВ, що мають стандартизований нормальний розподіл, U i ~ N (0,1).
, i = 1, 2, …, n, є незалежними СВ, що мають стандартизований нормальний розподіл, U i ~ N (0,1).
СВ χ 2має хі – квадрат розподіл з nступенями свободи (χ 2 ~ χ n 2), якщо  (20).
(20).
Відмітимо, що кількість ступенів свободи(Це число позначається v ) досліджуваної СВ визначається числом СВ, її складових, зменшеним на число лінійних зв'язківміж ними.
Наприклад, кількість ступенів свободи СВ, що є композицією nвипадкових величин, які у свою чергу пов'язані m лінійними рівняннями, визначається числом v = m – n.Таким чином, U 2 ~ χ 1 2 .
З визначення (20) випливає, що розподіл χ 2 визначається одним параметром - числом ступенів свободи v .
Графік щільності ймовірності СВ, що має χ 2 – розподіл, лежить лише у першій чверті декартової системикоординат і має асиметричний вигляд з витягнутим правим хвостом (рис.3). Але зі збільшенням числа ступенів свободи розподіл χ 2 поступово наближається до нормального:

Мал. 3. Графік щільності ймовірності СВ Х, що має χ 2 – розподіл.
M (χ 2) = v = n - m,
D (χ 2) = 2 v = 2 (n - m).
Якщо Хі Y– дві незалежні χ 2 – розподілені СВ із числами ступенів свободи nі kвідповідно (Х ~ χ n 2 , Y ~ χ k 2),то їх сума (Х+Y)також є χ 2– розподіленої СВ із числом ступенів свободи v = n+k.
Розподіл χ 2застосовується для знаходження інтервальних оцінокта перевірки статистичних гіпотез. При цьому використовується таблиця критичних точок χ 2- Розподілу.
Якщо дослідник, використавши методи, викладені в попередньому параграфі, переконався, що гіпотеза нормальності розподілу не може бути прийнята, то цілком можливо, що за допомогою існуючих методів вдасться так перетворити вихідні дані, що їх розподіл підпорядковуватиметься нормальному закону розподілу. Для пояснення ідеї перетворень розглянемо якісний приклад. Нехай крива розподілу f(x) має вигляд, поданий на рис. 3.7, тобто. є дуже крута ліва гілка та пологі права. Такий розподіл відрізняється від нормального.
Для виконання операцій перетворення кожне спостереження трансформується за допомогою логарифмічного перетворення. При цьому ліва гілка кривої розподілу сильно розтягується і розподіл набуває приблизно нормального вигляду. Якщо при перетворенні виходять значення, розташовані між 0 і 1, то всі значення, що спостерігаються для зручності розрахунків і щоб уникнути отримання негативних параметрів необхідно помножити на 10 у відповідній мірі, щоб всі знову отримані, перетворені значення були більше одиниці, тобто. необхідно виконати перетворення 

Мал. 3.7. Перетворення функції f(x) до нормального розподілу
Асиметричний розподіл з однією вершиною наводиться до нормального перетворення  В окремих випадках можна застосовувати інші перетворення:
В окремих випадках можна застосовувати інші перетворення:
а) обернена величина 
б) зворотне значення квадратного коріння 
Перетворення "зворотний розмір" є найбільш "сильним". Середнє положення між логарифмічним перетворенням та "зворотною величиною" займає перетворення "зворотне значення квадратного коріння".
Для нормалізації зміщеного вправо розподілу служать, наприклад, статечні перетворення  При цьому для приймають значення: а=1,5 при помірному і а=2 при сильно вираженому правому зміщенні. Рекомендуємо читачеві вигадати такі перетворення, які задовольняли б дослідника в тому чи іншому випадку.
При цьому для приймають значення: а=1,5 при помірному і а=2 при сильно вираженому правому зміщенні. Рекомендуємо читачеві вигадати такі перетворення, які задовольняли б дослідника в тому чи іншому випадку.
а обмежено? Розглянемо надалі методологію розв'язання цієї
4. Аналіз результатів пасивного експерименту. Емпіричні залежності
4.1. Характеристика видів зв'язків між рядами спостережень
Насправді сама необхідність вимірів більшості величин викликається тим, що де вони залишаються постійними, а змінюються функції від зміни інших величин. У цьому випадку метою проведення експерименту є встановлення виду функціональної залежності  =f( X). Для цього повинні одночасно визначатися як значення X, і відповідні їм значення
=f( X). Для цього повинні одночасно визначатися як значення X, і відповідні їм значення  а завданням експерименту є встановлення математичної моделі досліджуваної залежності. Фактично йдеться про встановлення зв'язкуміж двома рядами спостережень (вимірювань).
а завданням експерименту є встановлення математичної моделі досліджуваної залежності. Фактично йдеться про встановлення зв'язкуміж двома рядами спостережень (вимірювань).
Визначення зв'язку включає вказівку виду моделі та визначення її параметрів. У теорії експериментів незалежні параметри X=(x 1 , ..., x n) прийнято називати факторами, а залежні змінні y – відгуками. Координатний простір з координатами x 1 , x 2 , ..., x i , ..., x n називається факторним простором. Експеримент з визначення виду функції
 (4.1)
(4.1)
де x - скаляр, називається однофакторним. Експеримент з визначення функції виду
 =f( X), (4.1а)
=f( X), (4.1а)
де X=(x 1 , x 2 , ..., x i , ..., x k) – вектор – багатофакторним.
Геометричне уявлення функції відгуку у факторному просторі є поверхнею відгуку. При однофакторному експерименті k=1 поверхню відгуку є лінію на площині, при двухфакторном k=2 – поверхню в тривимірному просторі.
Зв'язки у випадку є досить різноманітними і складними. Зазвичай виділяють наступні видизв'язків.
Функціональні зв'язки(або залежність). Це такі зв'язки, коли за зміни величини Xінша величина Yзмінюється отже кожному значенню x i відповідає цілком певне (однозначне) значення y i (рис.4.1а). Таким чином, якщо вибрати всі умови експерименту абсолютно однаковими, то повторюючи випробування отримаємо одну й ту саму залежність, тобто. криві ідеально збігатимуться для всіх випробувань.
На жаль, таких умов насправді не зустрічається. Насправді не вдається підтримувати сталість умов (наприклад, коливання фізико-хімічних властивостей шихти під час моделювання процесів тепломасопереносу в металургійних печах). У цьому вплив кожного випадкового чинника окремо може бути мало, однак у сукупності вони можуть вплинути на результати експерименту. У цьому випадку говорять про стохастичну (імовірнісну) зв'язок між змінними.

Рис.4.1.Види зв'язків: а – функціональний зв'язоквсі точки лежать на лінії; б – зв'язок досить тісний, точки групуються біля лінії регресії, але вони лежать у ній; в – зв'язок слабкий
Стохастичність зв'язкуполягає в тому, що одна випадкова змінна Yреагує на зміну іншої Xзміною свого закону розподілу (див. рис. 4.1б). Таким чином, залежна змінна набуває не одного конкретного значення, а деякого з безлічі значень. Повторюючи випробування ми будемо отримувати інші значення функції відгуку і тому значенню x у різних реалізаціях будуть відповідати різні значення y в інтервалі . Шукана залежність  може бути знайдена лише результаті спільної обробки отриманих значень x і y.
може бути знайдена лише результаті спільної обробки отриманих значень x і y.
На рис.4.1б ця крива залежності, що проходить по центру смуги експериментальних точок (математичного очікування), які можуть і не лежати на кривій, що шукається  , А займають деяку смугу навколо неї. Ці відхилення викликані похибками вимірювань, неповнотою моделі та факторів, що враховуються, випадковим характером самих досліджуваних процесів та іншими причинами.
, А займають деяку смугу навколо неї. Ці відхилення викликані похибками вимірювань, неповнотою моделі та факторів, що враховуються, випадковим характером самих досліджуваних процесів та іншими причинами.
При аналізі стохастичних зв'язків можна назвати такі основні типи залежностей між змінними.
1. Залежності між однією випадковою змінною Xвід іншої випадкової змінної Yта їх умовними середніми значеннями називаються кореляційними. Умовне середнє  i – це середнє арифметичне для реалізації випадкової величини Yза умови, що випадкова величина Xприймає значення
i – це середнє арифметичне для реалізації випадкової величини Yза умови, що випадкова величина Xприймає значення  i.
i.
2. Залежність випадкової змінної Yвід невипадкової змінної Xабо залежність математичного очікування M y випадкової величини Yвід детермінованого значення Xназивається регресійної. Наведена залежність характеризує вплив змін величини Xна середнє значення величини Y.
Стохастичні залежності характеризуються формою, тіснотою зв'язку та чисельними значеннями коефіцієнтів рівняння регресії.
Форма зв'язкувстановлює вид функціональної залежності  =f( X) і характеризується рівнянням регресії. Якщо рівняння зв'язку лінійне, маємо лінійну багатовимірну регресію, у разі залежності Yвід Xописуються рівнянням прямої лінії в k-мірному просторі
=f( X) і характеризується рівнянням регресії. Якщо рівняння зв'язку лінійне, маємо лінійну багатовимірну регресію, у разі залежності Yвід Xописуються рівнянням прямої лінії в k-мірному просторі
 (4.2)
(4.2)
де b 0 ..., b j, ..., b k - Коефіцієнти рівняння. Для пояснення суті використовуваних методів обмежимося спочатку випадком, коли скаляр. У випадку види функціональних залежностей у техніці досить різноманітні: показові  , логарифмічні
, логарифмічні  і т.д.
і т.д.
Зауважимо, що завдання вибору виду функціональної залежності – завдання неформалізоване, т.к. одна і та ж крива на даній ділянці приблизно з однаковою точністю може бути описана різними аналітичними виразами. Звідси випливає важливий практичний висновок. Навіть у наш час ПЕОМ ухвалення рішення про вибір тієї чи іншої математичної моделі залишається за дослідником. Тільки експериментатор знає, навіщо використовуватиме ця модель, з урахуванням яких понять інтерпретуватимуться її параметри.
Вкрай бажано при обробці результатів експерименту вид функції  =f(X) вибирати виходячи з умов відповідності фізичної природі досліджуваних явищ чи наявним уявленням про особливості поведінки досліджуваної величини. На жаль, така можливість не завжди є, оскільки експерименти найчастіше проводяться для дослідження недостатньо чи неповно вивчених явищ.
=f(X) вибирати виходячи з умов відповідності фізичної природі досліджуваних явищ чи наявним уявленням про особливості поведінки досліджуваної величини. На жаль, така можливість не завжди є, оскільки експерименти найчастіше проводяться для дослідження недостатньо чи неповно вивчених явищ.

Рис.4.2. Кореляційне поле
При вивченні залежності =f( X) від одного фактора при заздалегідь невідомому вигляді функції відгуку для наближеного визначення виду рівняння регресії корисно попередньо побудувати емпіричну лінію регресії (рис.4.2). І тому весь діапазон зміни x на полі кореляції розбивають на рівні інтервалиx. Усі точки, що потрапили в даний інтервал x j, відносять до його середини
=f( X) від одного фактора при заздалегідь невідомому вигляді функції відгуку для наближеного визначення виду рівняння регресії корисно попередньо побудувати емпіричну лінію регресії (рис.4.2). І тому весь діапазон зміни x на полі кореляції розбивають на рівні інтервалиx. Усі точки, що потрапили в даний інтервал x j, відносять до його середини  . Для цього підраховують приватні середні для кожного інтервалу
. Для цього підраховують приватні середні для кожного інтервалу (4.3)
(4.3)
Тут n j – число точок в інтервалі x x j , причому  , де k * - Число інтервалів розбиття, n - обсяг вибірки.
, де k * - Число інтервалів розбиття, n - обсяг вибірки.
Потім послідовно з'єднують крапки  відрізками прямий. Отримана ламана називається емпіричною лінією регресії. За видом емпіричної лінії регресії можна у першому наближенні підібрати вид рівняння регресії
відрізками прямий. Отримана ламана називається емпіричною лінією регресії. За видом емпіричної лінії регресії можна у першому наближенні підібрати вид рівняння регресії  =f( X).
=f( X).
Під тіснотою зв'язкурозуміється ступінь близькості стохастичної залежність до функціональної, тобто. це показник тісноти групування експериментальних даних щодо прийнятого рівняння моделі (див. рис. 4.1б). Надалі уточнимо це положення.
Нормальний законрозподілу ймовірностей
Без перебільшення його можна назвати філософським законом. Спостерігаючи за різними об'єктами та процесами навколишнього світу, ми часто стикаємося з тим, що чогось буває мало, і що буває норма: 
Перед вами важливий вигляд функції щільності
нормального розподілу ймовірностей, і я вітаю вас на цьому цікавому уроці.
Які приклади можна навести? Їхня просто темрява. Це, наприклад, зростання, вага людей (і не тільки), їх фізична сила, розумові здібностіі т.д. Існує «основна маса» (за тією чи іншою ознакою)і є відхилення в обидві сторони.
Це різні характеристикинеживих об'єктів (ті самі розміри, вага). Це випадкова тривалість процесів…, знову спало на думку сумний приклад, і тому скажу час «життя» лампочок:) З фізики згадалися молекули повітря: серед них є повільні, є швидкі, але більшість рухаються зі «стандартними» швидкостями.
Далі відхиляємося від центру ще одне стандартне відхилення і розраховуємо висоту: 
Зазначаємо точки на кресленні (зелений колір) і бачимо, що цього цілком достатньо.
На завершальному етапі акуратно креслимо графік, та особливо акуратновідбиваємо його опуклість/увігнутість ! Ну і, мабуть, ви давно зрозуміли, що вісь абсцис – це горизонтальна асимптота , І «залазити» за неї категорично не можна!
При електронному оформленні рішення графік легко побудувати в Екселі, і несподівано для себе я навіть записав короткий відеоролик на цю тему. Але спочатку поговоримо про те, як змінюється форма нормальної кривої в залежності від значень і .
При збільшенні чи зменшенні «а» (При постійному «сигма»)графік зберігає свою форму та переміщається вправо / вліво
відповідно. Так, наприклад, при функція набуває вигляду ![]() і наш графік «переїжджає» на 3 одиниці вліво – рівно на початок координат:
і наш графік «переїжджає» на 3 одиниці вліво – рівно на початок координат: 
Нормально розподілена величина з нульовим математичним очікуванням отримала цілком природна назва – центрована; її функція щільності  – парна
, І графік симетричний щодо осі ординат.
– парна
, І графік симетричний щодо осі ординат.
У разі зміни «сигми» (При постійному "а"), графік «залишається дома», але змінює форму. При збільшенні він стає нижчим і витягнутим, наче восьминіг, що розтягує щупальця. І, навпаки, при зменшенні графіка стає вужчим і високим- Виходить «здивований восьминіг». Так, при зменшенні«сигми» вдвічі: попередній графік звужується і витягується вгорув два рази: 
Все в повній відповідності до геометричними перетвореннями графіків
.
Нормальний розподіл із одиничним значенням «сигма» називається нормованим, а якщо воно ще й центровано(наш випадок), то такий розподіл називають стандартним. Воно має ще більше просту функціющільності, яка вже зустрічалась у локальної теореми Лапласа
: ![]() . Стандартний розподіл знайшов широке застосуванняна практиці, і дуже скоро ми остаточно зрозуміємо його призначення.
. Стандартний розподіл знайшов широке застосуванняна практиці, і дуже скоро ми остаточно зрозуміємо його призначення.
Ну а тепер дивимось кіно:
Так, абсолютно вірно - якось незаслужено у нас залишилася в тіні функція розподілу ймовірностей
. Згадуємо її визначення:
- Імовірність того, що випадкова величина набуде значення, МЕНШЕ, ніж змінна , яка "пробігає" всі дійсні значення до "плюс" нескінченності.
Усередині інтеграла зазвичай використовують іншу букву, щоб не виникало «накладок» з позначеннями, бо тут кожному значенню ставиться у відповідність невласний інтеграл
 , який дорівнює деякому числуз інтервалу.
, який дорівнює деякому числуз інтервалу.
Майже всі значення не піддаються точному розрахунку, але як ми щойно бачили, із сучасними обчислювальними потужностями з цим немає жодних труднощів. Так, для функції  стандартного розподілу відповідна екселівська функція взагалі містить один аргумент:
стандартного розподілу відповідна екселівська функція взагалі містить один аргумент:
=НОРМСТРАСП(z)
Раз, два – і готово: 
На кресленні добре видно виконання всіх властивостей функції розподілу
, і з технічних нюансів тут слід звернути увагу на горизонтальні асимптоти
і точку перегину.
Тепер згадаємо одну з ключових завданьтеми, а саме з'ясуємо, як знайти - ймовірність того, що нормальна випадкова величина набуде значення з інтервалу
. Геометрично ця ймовірність дорівнює площі
між нормальною кривою та віссю абсцис на відповідній ділянці: 
але щоразу вимучувати наближене значення  нерозумно, і тому тут раціональніше використовувати «легку» формулу
:
нерозумно, і тому тут раціональніше використовувати «легку» формулу
:
.
! Згадує також , що
Тут можна знову задіяти Ексель, але є пара вагомих "але": по-перше, він не завжди під рукою, а по-друге, "готові" значення, швидше за все, викличуть питання у викладача. Чому?
Про це я неодноразово розповідав раніше: свого часу (і ще не дуже давно) розкішшю був звичайний калькулятор, і в навчальної літературидосі зберігся «ручний» спосіб вирішення завдання. Його суть полягає в тому, щоб стандартизуватизначення «альфа» та «бета», тобто звести рішення до стандартному розподілу:![]()
Примітка
: функцію легко отримати з загального випадку
 за допомогою лінійної заміни
. Тоді й:
за допомогою лінійної заміни
. Тоді й:
і з проведеної заміни випливає формула ![]() переходу від значень довільного розподілу– до відповідних значень стандартного розподілу.
переходу від значень довільного розподілу– до відповідних значень стандартного розподілу.
Навіщо це потрібно? Справа в тому, що значення скрупульозно підраховані нашими предками і зведені до спеціальної таблиці, яка є в багатьох книгах за тервером. Але ще частіше зустрічається таблиця значень, з якою ми вже мали справу в інтегральної теореми Лапласа
:
Якщо в нашому розпорядженні є таблиця значень функції Лапласа  , То вирішуємо через неї:
, То вирішуємо через неї:
Дробові значенняЗазвичай округляємо до 4 знаків після коми, як це зроблено у типовій таблиці. І для контролю є Пункт 5 макета
.
Нагадую, що ![]() , і щоб уникнути плутанини завжди контролюйте, таблиця ЯКИЙ функції перед очима.
, і щоб уникнути плутанини завжди контролюйте, таблиця ЯКИЙ функції перед очима.
Відповідьпотрібно дати у відсотках, тому розраховану ймовірність потрібно помножити на 100 і забезпечити результат змістовним коментарем:
- з перельотом від 5 до 70 м впаде приблизно 15,87% снарядів
Тренуємося самостійно:
Приклад 3
Діаметр підшипників, виготовлених на заводі, являє собою випадкову величину, нормально розподілену з математичним очікуванням 1,5 см і середнім квадратичним відхиленням 0,04 см. Знайти ймовірність того, що розмір навмання взятого підшипника коливається від 1,4 до 1,6 см.
У зразку рішення і далі я використовуватиму функцію Лапласа як найпоширеніший варіант. До речі, зверніть увагу, що згідно з формулюванням, тут можна включити кінці інтервалу до розгляду. Втім, це критично.
І вже у цьому прикладі нам зустрівся особливий випадок– коли інтервал симетричний щодо математичного очікування. У такій ситуації його можна записати у вигляді і, користуючись непарністю функції Лапласа, спростити робочу формулу:

Параметр "дельта" називають відхиленнямвід математичного очікування, та подвійна нерівністьможна «упаковувати» за допомогою модуля
:
![]() - Імовірність того, що значення випадкової величини відхилиться від математичного очікування менш ніж на .
- Імовірність того, що значення випадкової величини відхилиться від математичного очікування менш ніж на .
Добре те рішення, яке вміщується в один рядок:)
- Імовірність того, що діаметр навмання взятого підшипника відрізняється від 1,5 см не більше ніж на 0,1 см.
Результат цього завдання вийшов близьким до одиниці, але хотілося б ще більшої надійності - а саме, дізнатися межі, в яких знаходиться діаметр майже всіхпідшипників. Чи існує якийсь критерій щодо цього? Існує! На поставлене запитання відповідає так зване
правило «трьох сигм»
Його суть полягає в тому, що практично достовірним
є той факт, що нормально розподілена випадкова величина набуде значення з проміжку ![]() .
.
І насправді, ймовірність відхилення від матожидания менш ніж становить:
або 99,73%
У «перерахунку на підшипники» – це 9973 штуки з діаметром від 1,38 до 1,62 см і лише 27 «некондиційних» екземплярів.
У практичних дослідженнях правило «трьох сигм» зазвичай застосовують у зворотному напрямку: якщо статистично встановлено, що майже всі значення досліджуваної випадкової величиниукладаються в інтервал довжиною 6 стандартних відхилень, то з'являються вагомі підстави вважати, що ця величина розподілена за нормальним законом. Перевірка здійснюється за допомогою теорії статистичних гіпотез, до яких я сподіваюся рано чи пізно дістатися:)
Ну а поки що продовжуємо вирішувати суворі радянські завдання:
Приклад 4
Випадкова величина помилки зважування розподілена за нормальним законом з нульовим математичним очікуванням і стандартним відхиленням 3 грами. Знайти ймовірність того, що чергове зважування буде проведено з помилкою, що не перевищує модуля 5 грам.
Рішеннядуже просте. За умовою, і відразу зауважимо, що за чергового зважування (чогось чи когось)ми майже 100% отримаємо результат із точністю до 9 грам. Але в задачі фігурує вужче відхилення і за формулою ![]() :
:
![]() - Імовірність того, що чергове зважування буде проведено з помилкою, що не перевищує 5 грам.
- Імовірність того, що чергове зважування буде проведено з помилкою, що не перевищує 5 грам.
Відповідь:
Вирішене завдання принципово відрізняється від начебто схожого Приклад 3уроку про рівномірному розподілі . Там була похибка округленнярезультатів вимірів, тут йдеться про випадкової похибки самих вимірів. Такі похибки виникають у зв'язку з технічними характеристикамисамого приладу (діапазон припустимих помилок, як правило, вказують у його паспорті), а також з вини експериментатора – коли ми, наприклад, «на око» знімаємо свідчення зі стрілки тієї ж ваги.
Окрім інших, існують ще так звані систематичніпомилки виміру. Це вже невипадковіпомилки, які виникають через некоректне налаштування або експлуатацію приладу. Так, наприклад, невідрегульовані ваги підлоги можуть стабільно «додавати» кілограм, а продавець систематично обвішувати покупців. Або не систематично можна обрахувати. Однак, у будь-якому випадку, випадковою така помилка не буде, і її маточкування відмінно від нуля.
…терміново розробляю курс з підготовки продавців =)
Самостійно вирішуємо зворотне завдання:
Приклад 5
Діаметр валика - випадкова нормально розподілена випадкова величина, середнє квадратичне відхилення її дорівнює мм. Знайти довжину інтервалу, симетричного щодо математичного очікування, куди з ймовірністю потрапить довжина діаметра валика.
Пункт 5* розрахункового макета в допомогу. Зверніть увагу, що тут не відоме математичне очікування, але це не заважає вирішити поставлене завдання.
І екзаменаційне завдання, яке я настійно рекомендую для закріплення матеріалу:
Приклад 6
Нормально розподілена випадкова величина задана своїми параметрами (математичне очікування) та (середнє квадратичне відхилення). Потрібно:
а) записати щільність ймовірності та схематично зобразити її графік;
б) знайти ймовірність того, що набуде значення з інтервалу ![]() ;
;
в) знайти ймовірність того, що відхилиться по модулю не більше ніж на ;
г) застосовуючи правило "трьох сигм", знайти значення випадкової величини.
Такі завдання пропонуються повсюдно, і за роки практики мені їх довелося вирішити сотні та сотні штук. Обов'язково попрактикуйтесь у ручній побудові креслення та використанні паперових таблиць;)
Ну а я розберу приклад підвищеної складності:
Приклад 7
Щільність розподілу ймовірностей випадкової величини має вигляд ![]() . Знайти, математичне очікування, дисперсію, функцію розподілу, побудувати графіки щільності та функції розподілу, знайти.
. Знайти, математичне очікування, дисперсію, функцію розподілу, побудувати графіки щільності та функції розподілу, знайти.
Рішення: Насамперед, звернемо увагу, що в умові нічого не сказано про характер випадкової величини Сама собою присутність експоненти ще нічого не означає: це може виявитися, наприклад, показове або взагалі довільне безперервний розподіл . І тому «нормальність» розподілу ще треба обґрунтувати:
Оскільки функція ![]() визначена при будь-кому дійсному значенні, і її можна привести до вигляду
визначена при будь-кому дійсному значенні, і її можна привести до вигляду  , то випадкова величина розподілена за нормальним законом.
, то випадкова величина розподілена за нормальним законом.
Наводимо. Для цього виділяємо повний квадрат
та організуємо триповерховий дріб
:
Обов'язково виконуємо перевірку, повертаючи показник у вихідний вигляд:
що ми й хотіли побачити.
Таким чином:  - за правилу дій зі ступенями
«відщипуємо». І тут можна одразу записати очевидні числові характеристики:
- за правилу дій зі ступенями
«відщипуємо». І тут можна одразу записати очевидні числові характеристики:![]()
Тепер знайдемо значення параметра. Оскільки множник нормального розподілу має вигляд і , то:  , звідки висловлюємо та підставляємо на нашу функцію:
, звідки висловлюємо та підставляємо на нашу функцію:  після чого ще раз пробіжимося по запису очима і переконаємося, що отримана функція має вигляд
після чого ще раз пробіжимося по запису очима і переконаємося, що отримана функція має вигляд  .
.
Побудуємо графік щільності: 
та графік функції розподілу  :
:
Якщо під рукою немає Екселя і навіть звичайного калькулятора, то останній графік легко будується вручну! У точці функція розподілу набуває значення ![]() і тут знаходиться
і тут знаходиться


